本文主要是介绍无处不在的partition by,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前看到partition by在排名函数用过,也在sum函数里用过,这次又在case when里套用,学习了:
select company_id,employee_id,employee_name,case when max(salary) over(partition by company_id)<1000 then salary when max(salary) over(partition by company_id) between 1000 and 10000 then round(0.76*salary,0)else round(0.51*salary,0) end as salary
from Salaries
order by company_id,employee_id534. 游戏玩法分析 III - 力扣(LeetCode)
编写一个 SQL 查询,同时报告每组玩家和日期,以及玩家到目前为止玩了多少游戏。也就是说,在此日期之前玩家所玩的游戏总数。

partition by有兼顾前后的味道,不管是排名还是下面的累加。
selectplayer_id,event_date,sum(games_played) over(partition by player_id order by event_date) as games_played_so_far
fromactivityselect * from
activity a1,activity a2
where
a1.player_id=a2.player_id
and
a1.event_date>=a2.event_date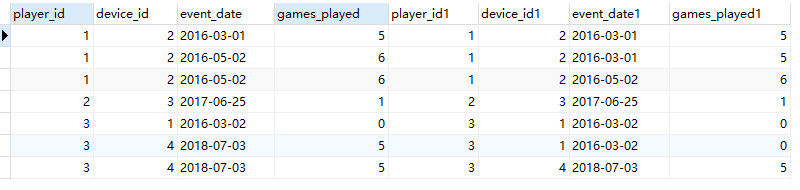
select a1.player_id,a1.event_date,sum(a2.games_played) games_played_so_far
from
activity a1,activity a2
where
a1.player_id=a2.player_id
and
a1.event_date>=a2.event_date
group by a1.player_id,a1.event_date
order by player_id,event_date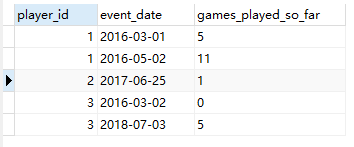
这篇关于无处不在的partition by的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[LeetCode] 763. Partition Labels](/front/images/it_default.gif)