partition专题
![[LeetCode] 763. Partition Labels](/front/images/it_default.gif)
[LeetCode] 763. Partition Labels
题:https://leetcode.com/submissions/detail/187840512/ 题目 A string S of lowercase letters is given. We want to partition this string into as many parts as possible so that each letter appears in at mo

MS SQL Server partition by 函数实战三 成绩排名
目录 需求 范例运行环境 视图样本设计 功能实现 基础数据展示 SQL语句 继续排序 小结 需求 假设有若干已更新考试成绩的考生,考试成绩包括总成绩、分项成绩1、分项成绩2,其它信息包括应聘岗位名称、姓名等信息。现希望根据总成绩计算排名,成绩越高排名越靠前,相同成绩排名并列,另外有并列则按总数递增,如两个第1后是第3。本文将继续介绍利用 partition by

关于PostgreSQL的分区表的历史及分区裁剪参数enable_partition_pruning与constraint_exclusion的区别
1. 疑惑 我们知道控制分区裁剪的参数有两个: enable_partition_pruningconstraint_exclusion 这两个参数有什么区别呢? 2. 解答 要说明这两个参数的区别需要先讲一讲PostgreSQL数据库中分区的历史,在PostgreSQL 10版本之前,PostgreSQL数据库实际上是没有单独的创建分区表的DDL语句,都是通过表继承的原理来创建分区表,

Hadoop中MapReduce中combine、partition、shuffle的作用是什么?在程序中怎么运用?
InputFormat类:该类的作用是将输入的文件和数据分割成许多小的split文件,并将split的每个行通过LineRecorderReader解析成<Key,Value>,通过job.setInputFromatClass()函数来设置,默认的情况为类TextInputFormat,其中Key默认为字符偏移量,value是该行的值。 Map类:根据输入的<Key,Value>对生成中间结果

Partition by子句
上篇博客写到使用开窗函数来进行数据查询,那么over关键字可以加什么查询条件呢?下面先介绍一下其中之一的partition by子句。 开窗函数的over关键字后括号中可以使用Partition by字句来定义行的分区来进行聚合运算。与group by 字句不同,partition by字句创建的分区是独立于结果集的,创建的分区只是提供聚合计算的,而且不同的开窗函数所创建的分区也不相互影响。

SpringBoot集成kafka-指定topic(主题)-partition(分区)-offset(偏移量)消费信息
SpringBoot集成kafka-指定topic-partition-offset消费信息 1、消费者2、生产者3、配置类4、配置文件5、实体类6、工具类7、测试类8、第一次测试(读取到19条信息)9、第二次测试(读取到3条信息) 1、消费者 指定消费者读取配置文件中 topic = " k a f k a . t o p i c . n a m e " , g r o u

ORA-1688: unable to extend table ACT.INFO_HIS partition P_201807 by 64 in tablespace TA
问题描述: 表空间TA的已扩展空间还有剩余255GB,而数据文件最大可扩展空间已到最大值。current_tatal=max_total,数据文件已经无法扩展。 据库报ORA-1688错误的问题分析如下: Mon Aug 13 09:35:47 2018 ORA-1688: unable to extend table ACT.INFO_HIS partition P_201807

count(distinct ...) over (partition by...) 替换成mysql
你这个是用了 Oracle 的分析函数。 SQL Server 是不支持的。如果语句比较简单的。例如SELECT COUNT( distinct A) OVER ( partition by B) FROM C可以修改为:SELECT COUNT( distinct A) FROM CGROUP BY B但是如果你的逻辑很复杂的话,那就麻烦了。
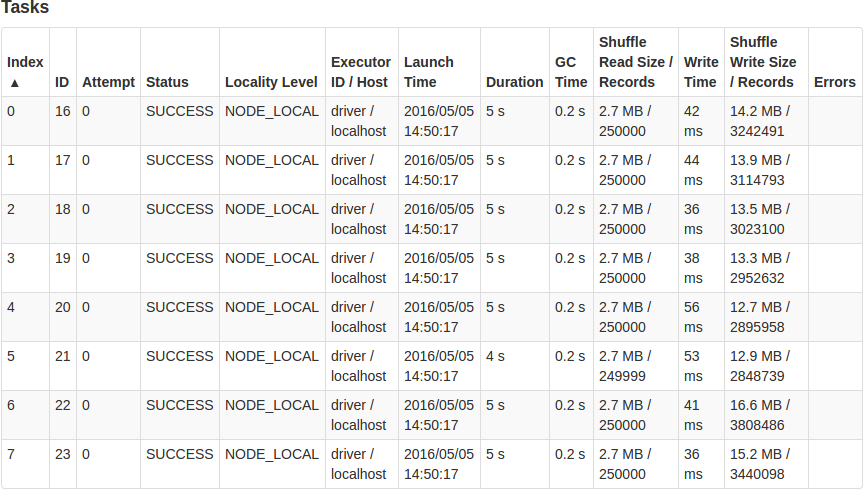
计算质数通过分区(Partition)提高Spark的运行性能
在Sortable公司,很多数据处理的工作都是使用Spark完成的。在使用Spark的过程中他们发现了一个能够提高Spark job性能的一个技巧,也就是修改数据的分区数,本文将举个例子并详细地介绍如何做到的。 查找质数 比如我们需要从2到2000000之间寻找所有的质数。我们很自然地会想到先找到所有的非质数,剩下的所有数字就是我们要找的质数。 我们首先遍历2到2000000之间的每个数
Ubuntu14.04安装 error:no such partition
参考: Ubuntu 开机出现 grub rescue> 终端模式修复方法:http://www.linuxidc.com/Linux/2012-07/65249.htm Windows&Ubuntu双系统一键Ghost,提示grub rescue的解决方法:http://www.linuxidc.com/Linux/2015-01/111189.htm #############

Apache Doris 全新分区策略 Auto Partition 应用场景与功能详解 | Deep Dive系列
编辑:SelectDB 技术团队 在当今数据驱动的时代,如何高效、有序地管理数据库中的海量数据成为挑战。为了处理庞大的数据集,分布式数据库引入了类似分区和分桶策略,通过将数据按特定规则划分成较小的单位并分布到不同节点上,利用并行计算能力以提升处理和分析性能,并加强了数据管理的灵活性。 在 Apache Doris 中,数据划分包含分区和分桶两个层级。分区一般按照时间或其他连续值对数据进行划分,
Array Partition I问题及解法
问题描述: Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1, b1), (a2, b2), ..., (an, bn) which makes sum of min(ai, bi) for all i from 1 to n as large
Partition to K Equal Sum Subsets问题及解法
问题描述: Given an array of integers nums and a positive integer k, find whether it's possible to divide this array into k non-empty subsets whose sums are all equal. 示例: Input: nums = [4, 3, 2, 3
OVER(PARTITION BY)函数用法
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下: 1:over后的写法: over(order by salary) 按

解决centos使用parted命令分区出现的警告Partition 1 does not start on physical sector boundary
问题描述 最近因为工作需要,需把申请的Linux服务器大容量磁盘分区并挂载,在实施的过程中遇到了这样一个问题:使用parted命令分区完毕后,使用fdisk –l 命令查看磁盘分区情况,发现有一条警告信息(Partition 1 does not start on physical sector boundary.)大致意思是:分区1不是从物理扇区的边界开始的。如图所示: 查了好多资料都说

LeetCode刷题 | Day 3 分割等和子集(Partition Equal Subset Sum)
LeetCode刷题 | Day 3 分割等和子集(Partition Equal Subset Sum) 文章目录 LeetCode刷题 | Day 3 分割等和子集(Partition Equal Subset Sum)前言一、题目概述二、解题方法2.1 动态规划思想2.1.1 思路讲解2.1.2 伪代码 + 逐步输出示例2.1.3 Python代码如下2.1.4 C++代码如下
uva 11258 - String Partition(dp)
题目链接: 11258 - String Partition 题目大意:给出一个字符串,由0~9组成,现在可以将字符串切割成若干段,每一段便可代表一个数值,但是这个数值不能大于int的最大上限,问,如何切割可以使得这若干个数的和最大。 解题思路:一开始想用区间dp做,但是小伙伴告诉我可以用递推的方法,就去找了一下代码,确实非常简单,dp[i]表示第i位数以前的最优解,由于in
hdu 4982 Goffi and Squary Partition(构造)
题目链接:hdu 4982 Goffi and Squary Partition 题目大意:给定n和k,求一个包含k个不相同正整数的集合,要求元素之和为n,并且其中k-1的元素的和为完全平方数。 解题思路:枚举平方数然后判断剩下的是否能组成即可。尽量用小的数去构造。 #include <cstdio>#include <cstring>#include <cmath>#inclu
HDU 4982 Goffi and Squary Partition(推理)
HDU 4982 Goffi and Squary Partition 思路:直接从完全平方数往下找,然后判断能否构造出该完全平方数,如果可以就是yes,如果都不行就是no,注意构造时候的判断,由于枚举一个完全平方数,剩下数字为kk,构造的时候要保证数字不重复 代码: #include <cstdio>#include <cstring>#include <cmath>int
LeetCode 题解(159): Partition List
题目: Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x. You should preserve the original relative order of the nodes in ea
ubiformat partition(The partition has data in it)
umount /configs/ ubidetach -p /dev/mtd12 #ubidetach -m 12 ubiformat /dev/mtd12 -y ubiattach /dev/ubi_ctrl -m 12 ubimkvol /dev/ubi1 -s 14MiB -N my_ubi_vol mount -t ubifs -o sync /dev/ubi1_0 /configs/
Flink源码阅读:如何使用FlinkKafkaProducer将数据在Kafka的多个partition中均匀分布
使Flink输出的数据在多个partition中均匀分布 FlinkKafkaProducerBase的子类可以使用默认的KafkaPartitioner FixedPartitioner(只向partition 0中写数据)也可以使用自己定义的Partitioner(继承KafkaPartitioner),我觉得实现比较复杂. 构造FlinkKafkaProducerBase的子类的2种情况
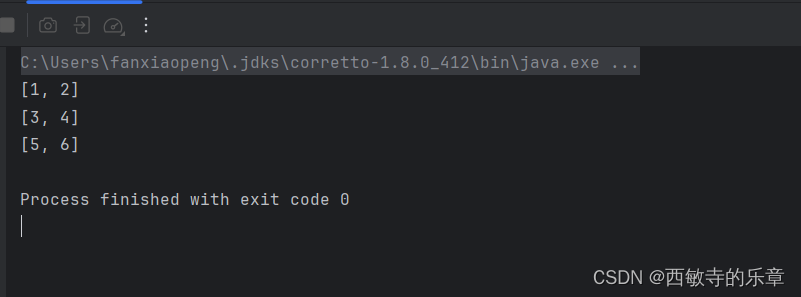
Lists.partition用法详解
文章目录 一、引入依赖二、用法三、输出 一、引入依赖 依赖于谷歌的guava 包 <!-- guava --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.1-jre</version></dependency> 二、用法 将strings整
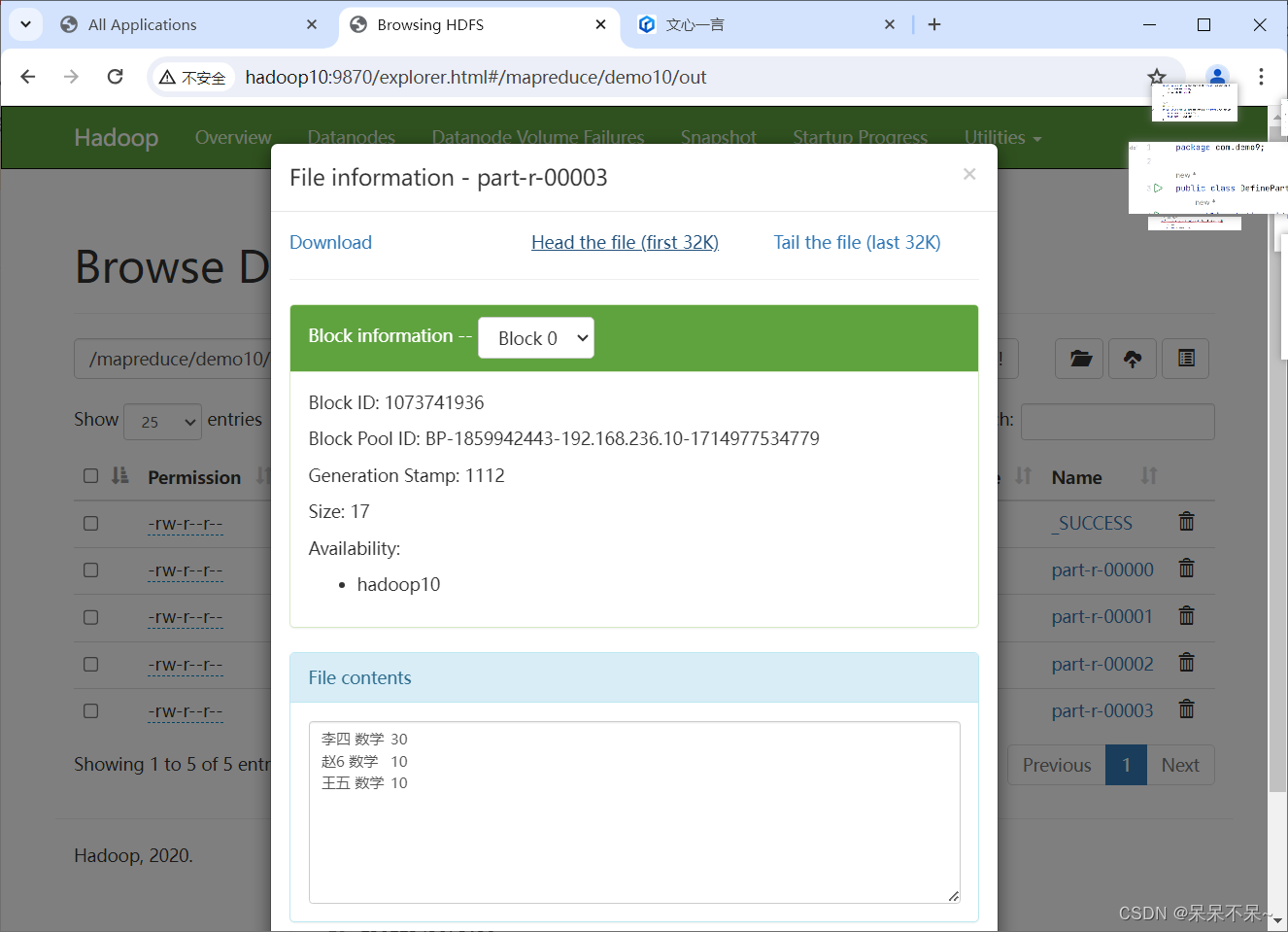
mapreduce | 自定义Partition分区(案例1)
1.需求 将学生成绩,按照各个成绩降序排序,各个科目成绩单独输出。 # 自定义partition 将下面数据分区处理: 人名 科目 成绩 张三 语文 10 李四 数学 30 王五 语文 20 赵6 英语 40 张三 数据 50 李四 语文 10 张三 英语 70 李四 英语 80 王五 英语 45 王五 数学 10 赵6 数学 10 赵6 语文 100
Leetcode 3144. Minimum Substring Partition of Equal Character Frequency
Leetcode 3144. Minimum Substring Partition of Equal Character Frequency 1. 解题思路2. 代码实现 题目链接:3144. Minimum Substring Partition of Equal Character Frequency 1. 解题思路 这一题的话思路上还是比较直接的,就是一个动态规划,这里就不过多展开了