本文主要是介绍17、论文解读:Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介:
Scan Context(常简称SC):是2018年韩国kim等发在IROS上的一篇文章,是在shape context的基础上提出的,可以和loam系的一些文章相结合用于回环检测。
标题:Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map
作者:Giseop Kim, Ayoung Kim
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
文章链接:Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map
代码链接:SC-lego-loam
代码解读:18、SC-lego-loam代码解读
现在已经有了一些SC的增强版本:isc-loam。
注:均为个人解读版本,用于学习记录和复习,如有不足,请多多指教。
Abstract:
为了实现基于激光雷达传感器的结构化信息的全局定位,文章提出了Scan Context方法。该方法是基于传感器采集的3D点云信息的传统方法,没有使用直方图,也不必经过训练集训练。此外,该方法提出了使用相似的评分来计算两个描述子之间的距离,提出了两向搜索的算法来检测回环。该方法具有旋转不变性,在多种数据集下有较好的表现。(经过我的多个数据集实验证明也确实挺好的)
I.INTRODUCTION :
大概介绍了一下激光雷达和相机比的优势,以及该方法采用合理的编码,保存好点云结构属性,使其具有旋转不变性和处理噪声的能力,不必使用之前常见直方图等方法。
II.RELATED WORK:
其他人的方法就不说了,想深入了解可以自己看,略。本文将3D点云存入一个矩阵中去,scan context中有点云结构,有效的编码信息、两向搜索算法。
III. SCAN CONTEXT FOR PLACE RECOGNITION
A. Scan Context
依据点云信息创建scan context,提出两帧之间相似度的计算方法。
文章建立描述子的第一步是将整个空间创建为以激光雷达传感器为中心的二维坐标系,使用2Π/Ns(用多少条半径划分)和Lmax(雷达最大有效距离)/Nr(在半径垂直方向划分)为单位代表分辨率划分整个空间为Bin(我理解为栅格),文中Ns = 60 and Nr = 20。第二步则将每个栅格存放该栅格范围内所有点云的最大z值,如果不存在点云,则设为0。下图分别对应第一二步:


其中:p代表各个栅格
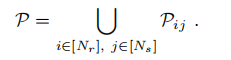
规则的划分结构能够带来更有效的信息,在划分结束之后,scan context补偿了较远处较为稀疏的点云信息,将附近的动态信息视为噪点(不知道咋实现的,一会儿去看看代码)。栅格中存放该栅格中最大的真值z,公式如下:
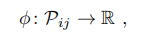
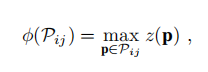
综上,一个scan context创建成功,使用I表示:
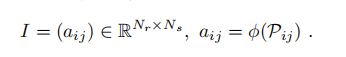
为了避免再次回到已经访问到的地方的时候雷达中心点和原先不一致导致(例如再次回到该点时是在对面的车道)的匹配失败,将原始的点云存到了Ntrans(由)中车道水平间隔和store scan contexts共同决定。
B.Similarity Score between Scan Contexts
使用余弦距离公式来判断两个Scan Contexts 相似度:
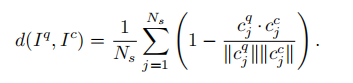
为了保证该描述子具有旋转不变性(相同方向的),将搜索所有可能的情况来寻找最小的距离。其实就是将描述子平移一小段距离来检测是否能得到更小值。
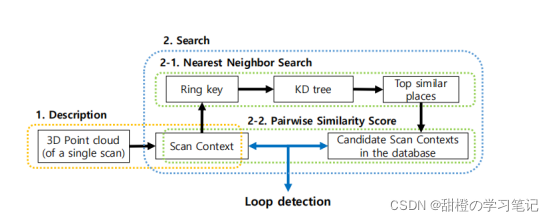
C.Two-phase Search Algorithm
回环检测的主流方法:相似度评分、NNS(最领近搜索)、稀疏优化。SC融合了相似度评分和分等级的临近搜索。采用K作为环:
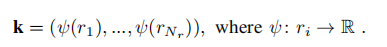
然后使用ψ 作为环中的占据比,就是不为0的栅格占据环中的栅格总数之比的结果:
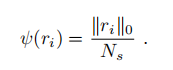
这样做的原因是更快,访问成功的阈值许选择:
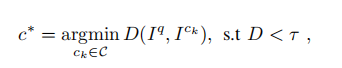
C是从KD树中选出来的匹配候选集,τ是一个可以接受的阈值,c∗是决定回环点的指数。
实验:略。
怕什么真理无穷,近一寸有近一寸的欢喜!
这篇关于17、论文解读:Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






