本文主要是介绍即插即用 | 5行代码实现NAM注意力机制让ResNet、MobileNet轻松涨点(超越CBAM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

识别不显著特征是模型压缩的关键。然而,这一点在注意力机制中却没有得到研究。在这项工作中提出了一种新的基于规范化的注意力模块(NAM),它抑制了较少显著性的权值。它对注意力模块应用一个权重稀疏惩罚,因此,在保持类似性能的同时,使它们更有效地计算。通过与ResNet和MobileNet上其他三种注意力机制的比较,表明本文的方法具有更高的准确性。
论文地址:https://arxiv.org/abs/2111.12419
Github:https://github.com/Christian-lyc/NAM
1简介
注意力机制是近年来研究的热点之一。之前的许多研究都关注于通过注意力操作捕捉显著特征。这些方法成功地利用了特征不同维度上的相互信息。然而,它们缺乏对权重的影响因素的考虑,进而进一步抑制不显著的通道或像素。
而本文的目标是利用权重的贡献因子来改善注意力机制。使用批归一化的比例因子,它使用标准差来表示权重的重要性。这可以避免添加SE、BAM和CBAM中使用的全连接层和卷积层。因此,本文提出了一种有效的基于规范化的注意力机制。
2相关工作
许多先前的工作试图通过抑制无关紧要的权值来改善神经网络的性能。
Squeeze-and-Excitation Networks(SENet) 将空间信息整合到通道特征响应中,并使用两个多层感知器(MLP)层计算相应的注意。
Bottleneck Attention Module(BAM)并行构建分离的空间子模块和通道子模块,它们可以嵌入到每个Bottleneck Block中。
Convolutional Block Attention Module(CBAM)提供了一种顺序嵌入通道和空间注意力子模块的解决方案。
为了避免忽视跨维度的相互作用,Triplet Attention Module (TAM) 通过旋转特征图考虑维度相关性。然而,这些工作忽略了来自训练中调整权重的信息。
因此,本文的目标是通过利用训练模型权重的方差度量来突出显著特征。
3本文方法
本文提出NAM作为一种高效、轻量级的注意力机制。NAM采用CBAM的模块整合,重新设计了通道和空间注意力子模块。然后,在每个网络块的末端嵌入一个NAM模块。对于残差网络,它嵌入在残差结构的末端。对于通道注意子模块,使用批归一化(BN)中的比例因子,如下式所示。
比例因子测量通道的方差并指出它们的重要性。
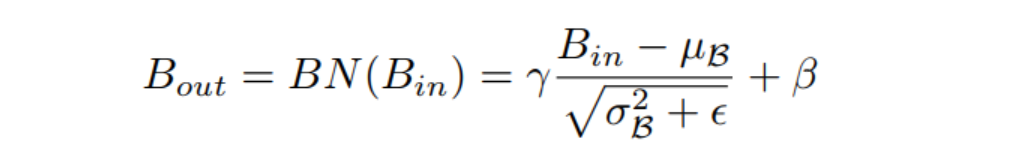
其中为均值,为标准差;和是可训练的仿射变换参数(尺度和位移)。
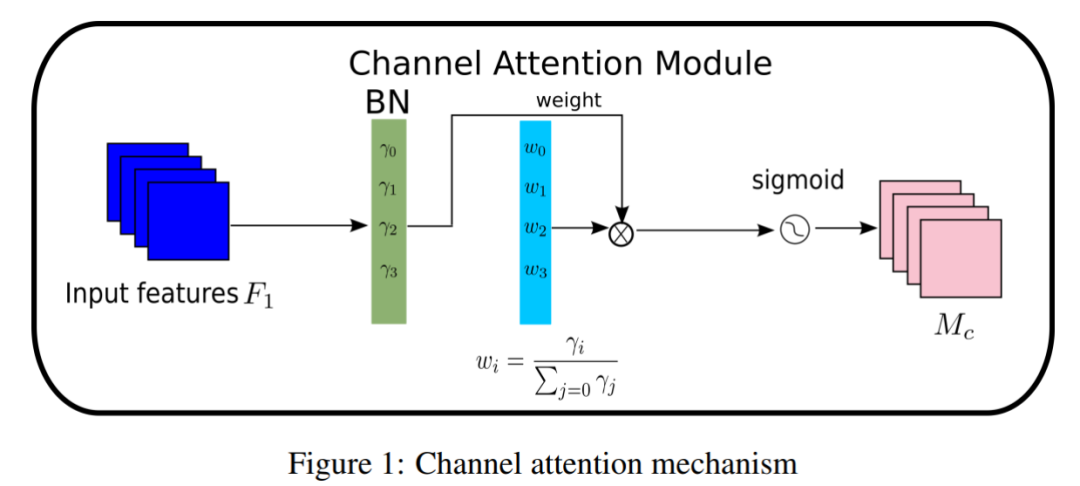
通道注意力子模块如图1和式(2)所示,其中表示输出特征。是每个通道的比例因子,权值为。这里还将BN的比例因子应用于空间维度,来衡量像素的重要性。称之为像素归一化。
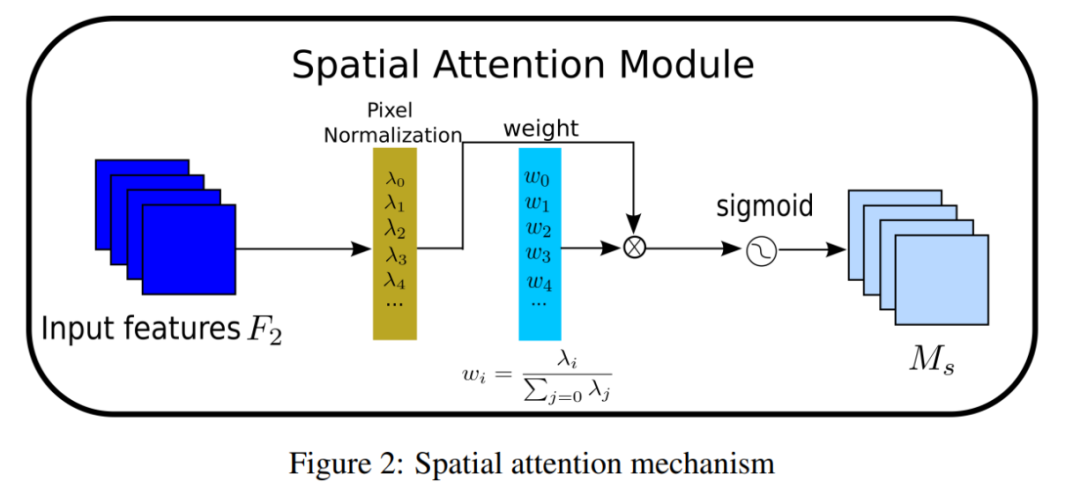
对应的空间注意力子模块如图2和式(3)所示,其中输出记为,为比例因子,权值为。
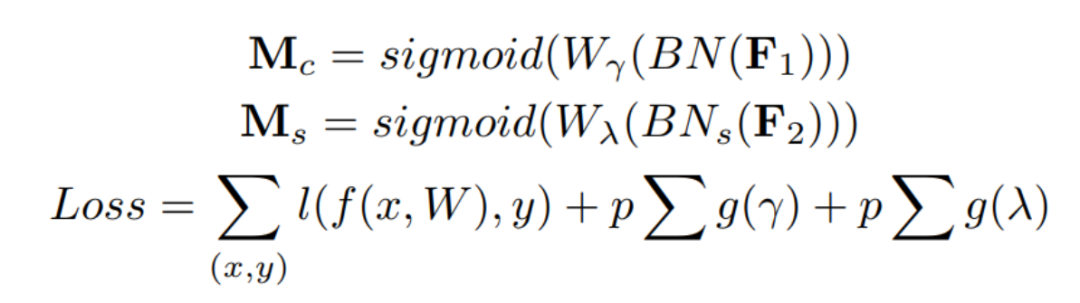
PyTorch实现如下:
对于残差网络,它嵌入在残差结构的末端。对于通道注意子模块,使用批归一化(BN)中的比例因子.
import torch.nn as nn
import torch
from torch.nn import functional as F# 具体流程可以参考图1,通道注意力机制
class Channel_Att(nn.Module):def __init__(self, channels, t=16):super(Channel_Att, self).__init__()self.channels = channelsself.bn2 = nn.BatchNorm2d(self.channels, affine=True)def forward(self, x):residual = xx = self.bn2(x)# 式2的计算,即Mc的计算weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())x = x.permute(0, 2, 3, 1).contiguous()x = torch.mul(weight_bn, x)x = x.permute(0, 3, 1, 2).contiguous()x = torch.sigmoid(x) * residual #return xclass Att(nn.Module):Yichao Liu, 2 months ago: • Add files via uploaddef __init__(self, channels,shape, out_channels=None, no_spatial=True):super(Att, self).__init__()self.Channel_Att = Channel_Att(channels)def forward(self, x):x_out1=self.Channel_Att(x)return x_out14实验
4.1 Cifar-100
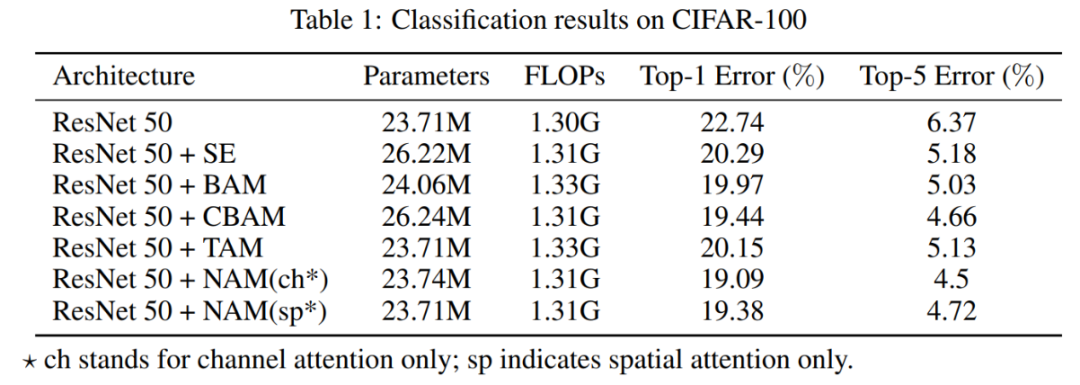
4.2 ImageNet
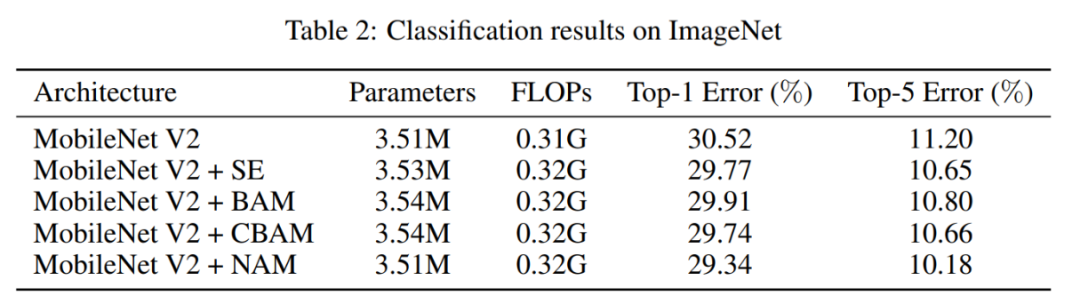
5参考
[1]. NAM: Normalization-based Attention Module
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~这篇关于即插即用 | 5行代码实现NAM注意力机制让ResNet、MobileNet轻松涨点(超越CBAM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




