本文主要是介绍顶会ICLR2024论文Time-LLM:基于大语言模型的时间序列预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文青松
松鼠AI首席科学家、AI研究院负责人
美国佐治亚理工学院(Georgia Tech)电子与计算机工程博士,人工智能、决策智能和信号处理方向专家,在松鼠AI、阿里、Marvell等公司超10年的技术和管理经验,近100篇文章发表在人工智能相关的顶会与顶刊,多篇文章被AI顶会(NeurIPS, ICLR等)评选为Oral/Spotlight论文,两次入选IJCAI最具影响力论文并排名第一,两次获得AAAI人工智能系统部署应用奖,获得ICASSP Grand Challenge冠军。近期研究兴趣为智能时序与AI教育, 也是AI顶会 (AAAI, IJCAI, KDD, ICDM等) Workshop on AI for Time Series, Workshop on AI for Education的主要组织者之一。个人主页为: https://sites.google.com/site/qingsongwen8
论文:
Time-LLM: Time Series Forecasting By Reprogramming Large Language Models
Time-LLM:通过重编程大型语言模型进行时间序列预测
论文链接:
论文(arXiv):https://arxiv.org/abs/2310.01728
论文(ICLR’24):https://openreview.net/forum?id=Unb5CVPtae
代码:
https://github.com/KimMeen/Time-LLM
以下内容是根据松鼠AI首席科学家、AI研究院负责人文青松团队成员在2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会闪电论文分享环节上的演讲整理成文。
大家好,我是来自莫纳什大学的博士生金明(个人主页:https://mingjin.dev/),今天很荣幸能和大家分享我们团队的研究成果,介绍的内容是Time-LLM,主要探讨的是如何重编程大语言模型来实现时间序列预测。
背 景
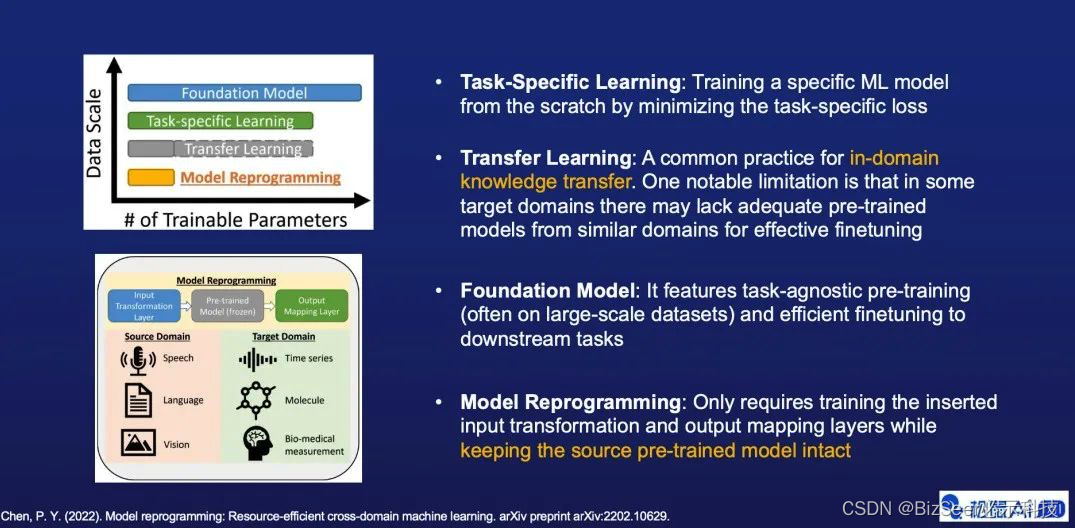
和传统的任务导向学习与基准模型预训练相比,模型重编程所需要的训练样本和待学习的参数都很少。与典型的迁移学习相比,模型重编程在域内和跨域泛化等方面,都显示出了较好的有效性。在技术层面模型重编程只需要训练外部的输入变换层和输出映射层,而不涉及任何对预训练模型本身的更新。
目 的

我们的工作内容主要是研究如何从编程大语言模型时期可以轻松的用于时间序列相关任务。
比方说预测,我们将大语言模型重编程定义为两部分,第一是Adaptation,目的在于打通两个短链之间的隔阂,使大语言模型能够将时间序列作为输入和对应输出。其次是Alignment,也就是我们常说的对齐,目的是进一步消除短链之间的间隔。
此外我们还发现重编程大语言模型可以让其在时间序列任务上更有效。比如通过Prompts的形式引入外部的专家知识和具体的任务描述。
架 构
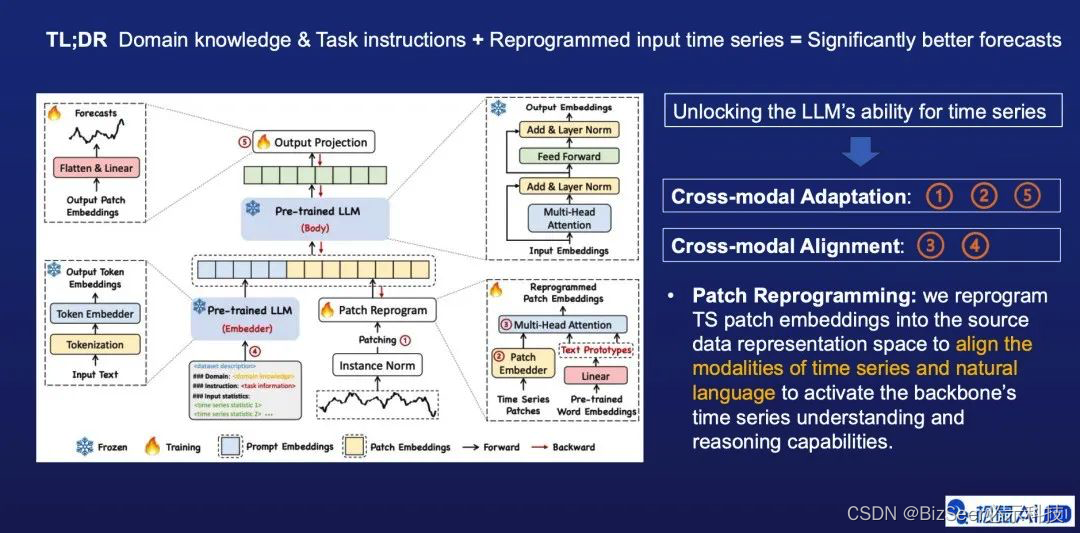
上图中展示的是我们方法的架构图,其中第1、第2、第5步是Adaptation相关的设计,然后第3、第4步是对齐相关的设计。在第3步里也就是Patch Reprogramming,我们通过使用Word Embedding来表示不同时间序列,进而对齐两个不同的模态即自然语言和时间序列。
第4步,我们通过将外部知识做前缀这个方法,进一步帮助大语言模型在时序数据上做有效的推理,外部知识可以是一些专家知识或者具体的实训任务的描述。
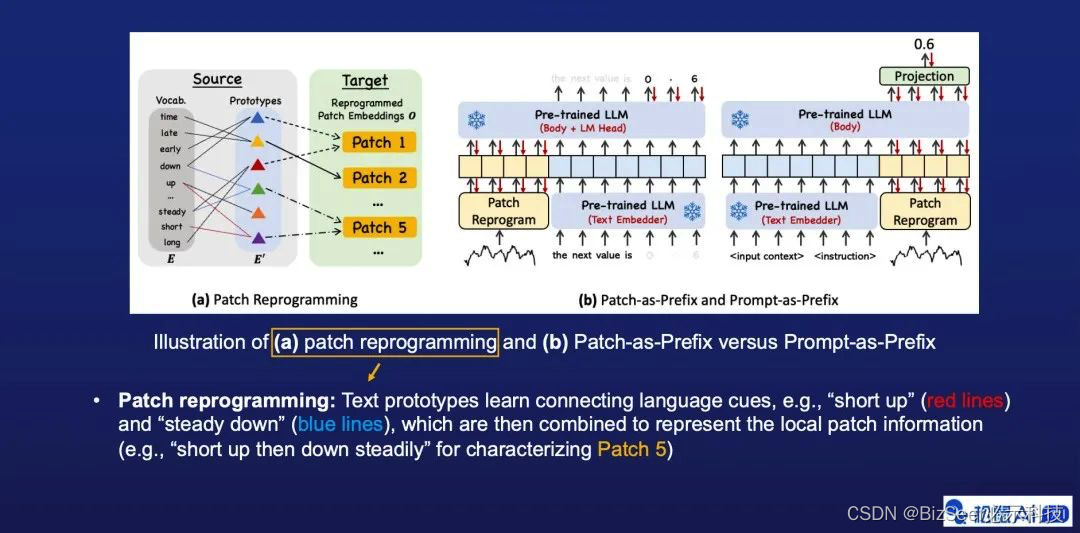
图片中的a部分,我们进一步描述了Patch reprogramming的核心思想。在这个例子中,我们展示了如何使用自然语言刻画时间序列片段 (Patch),比如Patch 5的语义信息其实可以描述成两个具体过程:先短暂上升再平稳下降。因此我们可以用绿色和紫色两个不同的Text prototypes来表示它,进而打通如图所示的两个不同的数据模态/信息域。
图片
在图片中的b部分,我们对比了两种结合文本Prompt的范式,其中我们提出来的Prompt-as-Prefix(PaP)方法具有两个比较直接的优势:一是无需构建特定的多模态指令训练集,二是规避了大语言模型本身在生成输出时间序列方面存在的一些挑战,例如有限的上下文窗口,较低的高精度数字敏感度,和不同分词策略对结果产生的未知影响。
结 果
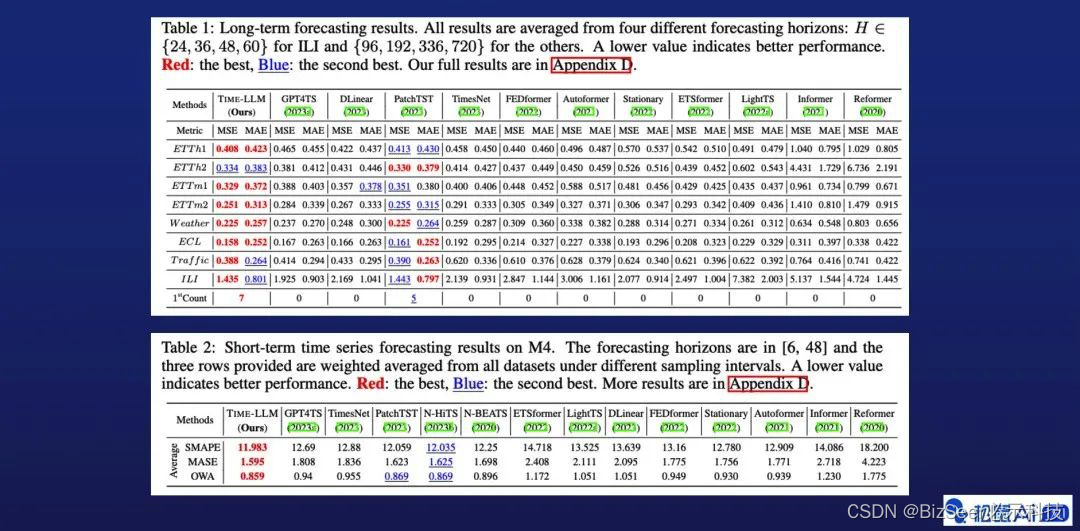
接下来展示实验的结果。如图所示,我们的Time-LLM方法显示出了非常好的有效性。上图是标准的长程预测结果在8个基准数据集上的对比,下图是标准短程预测在M4比赛数据集上的结果对比。
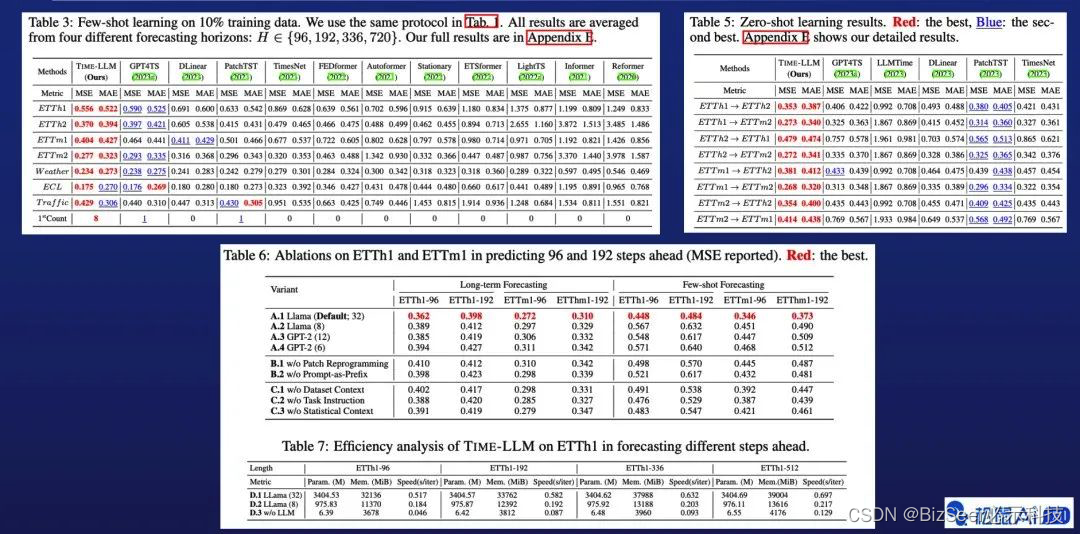
图片中上半部分展示的是部分Few-shot和Zero-show的预测结果的对比,下半部分展示的是主要的消融实验和训练效率相关的实验结果,均显示了本文提出方法的有效性。
总 结

最后是一个简短的总结。
我们的研究工作一是探索使用大语言模型做时序分析任务的可能性,提出了对大语言模型做重编程的概念。二是发现和验证了时序任务本身可以抽象成一种能够被大语言模型解决的特殊语言任务。最后是我们的一些启发和展望,比如说做多模态的时序分析,以及通用的时序GPT。
我的分享到此结束,谢谢大家。
更多LLM for Time Series相关资料:
- (时序与时空大模型, 综述): Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook, in arXiv, Oct. 2023.
Authors: Ming Jin, Qingsong Wen*, Yuxuan Liang, Chaoli Zhang, Siqiao Xue, Xue Wang, James Zhang, Yi Wang, Haifeng Chen, Xiaoli Li (IEEE Fellow), Shirui Pan*, Vincent S. Tseng (IEEE Fellow), Yu Zheng (IEEE Fellow), Lei Chen (IEEE Fellow), Hui Xiong (IEEE Fellow)
Link: https://arxiv.org/abs/2310.10196
2.(LLM for Time Series, Position Paper): What Can Large Language Models Tell Us about Time Series Analysis, in arXiv, Feb. 2024.
Authors: Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang*, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen*
Link: https://arxiv.org/abs/2402.02713
这篇关于顶会ICLR2024论文Time-LLM:基于大语言模型的时间序列预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






