本文主要是介绍BevFusion (2): nuScenes 数据介绍及点云可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. nuScenes 数据集
1.1 概述
nuScenes 数据集 (pronounced /nu:ːsiː:nz/) 是由 Motional (以前称为 nuTonomy) 团队开发的自动驾驶公共大型数据集。nuScenes 数据集的灵感来自于开创性的 KITTI 数据集。 nuScenes 是第一个提供自动驾驶车辆整个传感器套件 (6 个摄像头、1 个 LIDAR、5 个 RADAR、GPS、IMU) 数据的大型数据集。 与 KITTI 相比,nuScenes 包含的对象注释多了 7 倍。为了促进常见的计算机视觉任务 (例如对象检测和跟踪) ,整个数据集中使用 2Hz 的准确 3D 边界框注释 23 个对象类。 此外,还注释了对象级属性,例如可见性、活动和姿势。
2019 年 3 月,Motional 发布了包含全部 1000 个场景(scenes)的完整 nuScenes 数据集。 其中包含大约 140 万张相机图像、39 万张激光雷达扫描、140 万张雷达扫描和 4 万个关键帧中的 140 万个对象边界框。
1.2 数据收集
1.2.1 场景
对 nuScenes 数据集,Motional 在波士顿和新加坡收集了大约 15 小时的驾驶数据。完整的数据来自波士顿海港区以及新加坡 One North,Queenstown 和 Holland Village 地区。数据旨在涵盖广泛的地点、时间和天气条件。为了平衡各个类类别的频率分布,还加入了更多包含罕见类 (如自行车) 的场景。根据这些标准,人工选择了 1000 个每个持续 20 秒的场景,这些场景由人工专家进行标注。

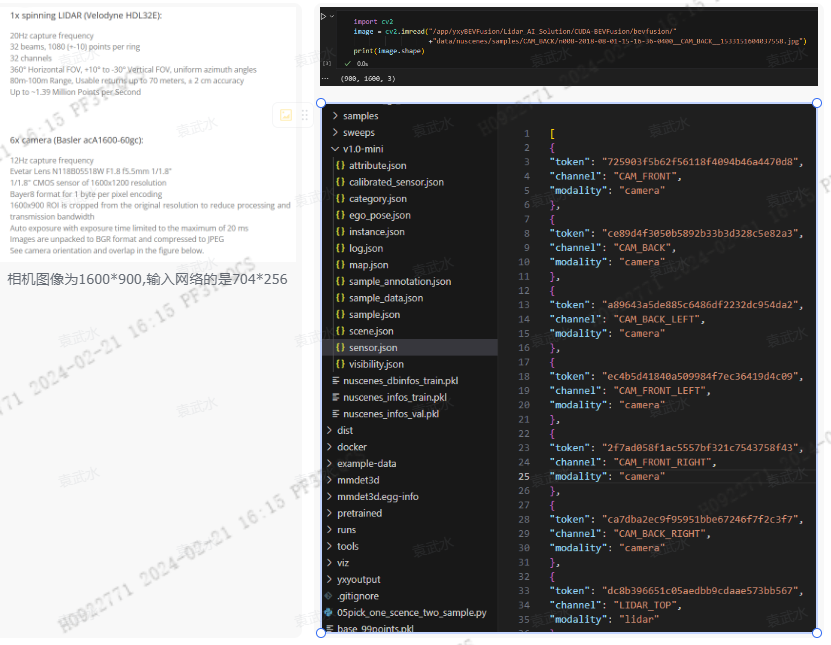
下图是下载的v1.0-min nuScenes数据集,其中关于场景的token信息存在scene.json中

1.2.2 采集车传感器配置
组成:6 个摄像头、1 个激光雷达、5 个雷达、GPS、IMU。
- 6 个摄像头布置的位置分别为:Front, Front_Right,Front_Left, Back,Back_Left, Back_Right;
- 5个雷达相机布置位置为:Front, Front_Right,Front_Left,Back_Left, Back_Right;
- 激光雷达布置在车顶位置。

值得注意的是:在nuScenes数据集中相机采集的图像分辨率为:1600 x 900, 但是最终输入BevFusion 网络的是704*256
1.2.3 传感器标定
为获得高质量的多传感器数据集,每个传感器的 extrinc (外参) 和 intrinsic (内参) 都必须进行标定(calibrate)。将外参坐标表示为相对于自车坐标系(ego)的We express extrinsic coordinates relative to the ego frame,也就是车尾中轴的中点。主要步骤描述如下:

LIDAR 外参数标定:使用激光定线器精确测量 LIDAR 相对于 ego (自车坐标系)的位置, 获得LIDAR相对于ego的calibrate参数: 旋转(rotation) 和平移 (translation)Radar 外参数标定:将 Radar 安装在水平位置上,然后在城市环境下收集 Radar 测量数据。在对移动物体进行滤波后,使用暴力方法校准偏航角,以最小化对静态物体的补偿速率。Camera 外参数标定:在 Camera 和 LIDAR 传感器前方放置一个立方体形状的校准目标。校准目标由三个具有已知图案的正交平面组成。在检测到这些图案后,通过对齐校准目标的平面来计算从 Camera 到 LIDAR 的转换矩阵。在上述计算得到 LIDAR 到 ego 的转换矩阵之后(rotation和translation),可以计算 Camera 到 ego 坐标系的转换矩阵以及相应的外参参数。- Camera 内参数标定:使用一个具有已知图案集合的校准目标板来推断 Camera 的
内参和畸变参数。
在nuScenes数据集中,calibration 相关数据保存在calibrated_sensor.json文件中。

1.2.4 数据同步
因为每个传感器采集数据的频率是有差异的,比如相机是12Hz, 而激光雷达是20Hz。为了在LIDAR和摄像头之间实现良好的跨模态数据对齐,当顶部 LIDAR 扫过摄像头 FOV 的中心时,会触发摄像头的曝光。图像的时间戳为曝光触发时间;而激光雷达扫描的时间戳是当前激光雷达帧实现全旋转的时间。鉴于相机的曝光时间几乎是瞬时的,这种方法通常会产生良好的数据对齐(通过观察相机和雷达的时间戳,其实还是存在差异的)。 请注意,相机以 12Hz 运行,而 LIDAR 以 20Hz 运行。 12 次相机曝光尽可能均匀地分布在 20 次激光雷达扫描中,因此并非所有激光雷达扫描都有相应的相机帧。 将摄像头的帧速率降低到 12Hz 有助于降低感知系统的计算、带宽和存储需求。
1.3 数据格式
https://boardmix.cn/app/editor/YvaRVkp18SgYjyqvivc7aA
以下是 nuScenes 中使用的数据库模式。所有的标注和元数据 (包括校准cablirate、地图map、车辆坐标等) 都存储在一个关系型数据库中。每一行都可以通过其唯一的主键标记来进行识别。外键,例如sample_token,可用于与sample表格的标记进行关联。请参考教程,了解数据库表格的介绍。

- 可以利用nuscenes库,基于数据库表之间的外键,找到对应的数据信息。比如当我们拿到
sample_data数据后,解析该数据,可以拿到ego_pose_token(唯一的标识码),利用ego_pose_token 就可以获得对应的ego_pose, 它包含了时间戳(timestamp)以及旋转矩阵(rotation)和平移矩阵(translation),从而获得了ego(自车)相对于(global)的变换矩阵。 - 同理利用sample_data中的
calibrate_sensor_token,就可以唯一确定calibrated_sensor数据,从而获得传感器相对于ego的变化矩阵(translation 和rotation)
lidar2ego=nuscenes.get('calibrate_sensor',calibrate_sensor_token)
1.4 数据标注
-
在收集了驾驶数据后,我们以 2Hz 的频率采样同步良好的关键帧(图像、LIDAR、RADAR)we sample well synchronized keyframes (image, LIDAR, RADAR) at 2Hz ,并将它们发送给我们的标注合作方 Scale 进行标注。通过专家标注人员和多重验证步骤,我们实现了
高度精确的标注(highly accurate annotations)。nuScenes 数据集中的所有对象都配有语义类别(semantic category),以及它们出现在每一帧(frame)中的 3D 包围盒和属性(D bounding box and attributes)。与 2D 包围盒相比,这使我们能够准确地推断出对象在空间中的位置和方向(position and orientation)。 -
我们为
23个对象类别提供了真实标签(ground truth labels)。对于完整的 nuScenes 数据集,我们提供以下类别(不包括测试集)的标注: -
对于 nuScenes-lidarseg,我们为激光雷达点云中的每一个点都标注了一个语义标签(semantic label)。除了来自 nuScenes 的
23个前景类别(foreground classes)(物体things)外,我们还包括了9 个背景类别( background classes )(场景stuff)。有关每个类别的详细定义和示例图片,请参见 nuScenes 和 nuScenes-lidarseg 的标注人员指南。我们提供以下类别(不包括测试集)的标注:
接下来是一些具体的标注数据统计,包括各类别的数量和比例等。

-
请注意,`static_object.bicycle_rack(自行车架)这个分类可能包括没有单独标注的自行车。我们使用这个标签来在训练期间忽略大量的共享自行车,以避免让我们的对象检测器偏向于这些相对不太有趣的自行车。
-
此外,nuScenes 中的某些类别具有特殊属性:


1.4.1 解释2HZ、12HZ
- 在nuScenes标注的是关键帧的数据,
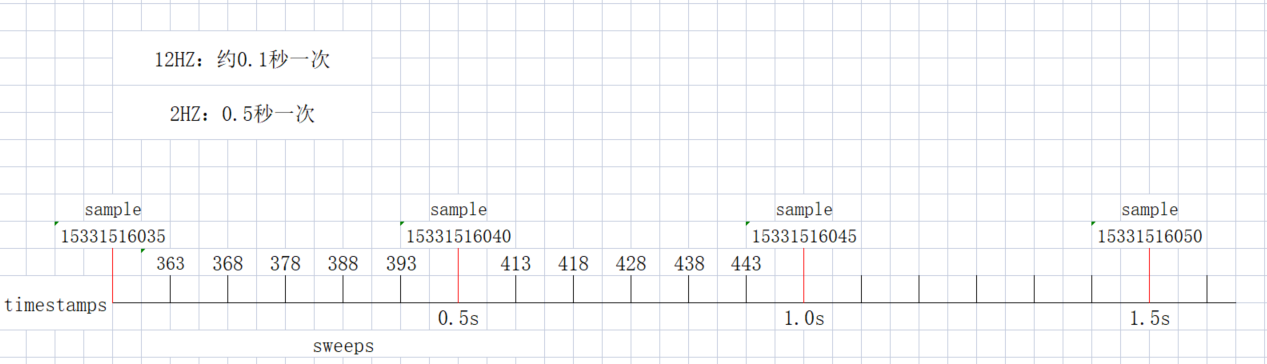
每隔0.5秒标注一次,也就是2HZ。而相机的采样频率为12HZ,也就是几乎每隔0.1s采集一张图片。如下图所示:15331516035->15331516040->15331516045 对应的是时间戳,最后两位35->40->45表示间隔0.5秒。对于激光雷达它的采样频率更高为20Hz,采集的数据为sweeps, 由于标注比较少,每隔0.5秒标注一次,中间有很多sweeps没有参与标注。
- 对于
单帧点云来说,对点云进行可视化一般比较稀疏,因此可以在一个关键帧中,利用相近的sweeps对点云进行加密,使得点云更加稠密。如下图所示:

第一张就是利用sweeps进行加密处理过的点云数据,看起来比较稠密。
1.4.2 Bevfusion中只用了10个类别

在BevFusion->configs->default.yaml列出了,识别的10个类别。
1.5 评价指标

上图是nuScences数据集的评价指标,可以点击https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any , 查看当前最新的算法在nuScences上的表现情况,评价的指标就是上图列出的指标
- (1)
Modalities: 列出了算法采用哪些传感器融合的 - (2)指标
mAP越高,说明算法的性能越好;其中带E结尾的指标, (mATE,mASE,mAOE,mAVE,mAAE),表示是相关的error,这些指标越小越好。
可以查看nuScenes发表的论文,论文中详细的描述了这些指标具体含义,在CVPR 2020的一篇论文中,新增了一个比较重要的指标PKL(Planning KL-Divergence)
-
mAP 平均精度(mean Average Precision)- mAP是一个比较重要的指标,与 2D目标检测不一样,它不是利用IoU来做阈值的,而是计算地平面上两个2D边界框中心点的距离作为阈值。这样做有几个原因

解耦检测与对象大小和方向:通过使用2D中心距离作为匹配标准,评价更加集中在检测准确性上,而不是对象的大小或方向。小物体问题:对于像行人和自行车这样的小物体,即使检测有小的平移误差,其IoU也可能为0。这使得很难比较依赖视觉的方法(这些方法往往有较大的定位误差)
- mAP是一个比较重要的指标,与 2D目标检测不一样,它不是利用IoU来做阈值的,而是计算地平面上两个2D边界框中心点的距离作为阈值。这样做有几个原因
-
mATE 平均平移误差(Average Translation Error):这是2D中心点之间的欧几里得距离,单位是米。 -
mASE平均尺度误差(Average Scale Error):这是在方向和平移对齐后的3D交并比(Intersection over Union,IOU),计算为 1−IOU。 -
mAOE平均方向误差(Average Orientation Error):这是预测和地面真实值之间最小偏航角度的差异,单位是弧度。所有角度都是在一个完整的360度周期内进行测量的,除了对于障碍物,它们是在一个180度周期内进行测量的。 -
mAVE平均速度误差(Average Velocity Error):这是2D速度差异的L2范数的绝对值,单位是米/秒(m/s)。 -
mAAE平均属性误差(Average Attribute Error):这是定义为 1−属性分类准确度(acc)1−属性分类准确度(acc)。 -
NDS(nuScenes detection score): 是这些指标的加权结果,这样做旨在简化评估过程,同时仍然能全面地评估模型在多个方面的性能。计算公式如下:

- 可以看到mAP占的权重是最高的。后面是对其他评价指标进行加权。
-
PKL(Planning KL-Divergence):PKL度量了预测对象与实际对象之间的差异性, ,以及这种差异性如何影响自车的路径规划。这是一种有用的度量方式,因为它直接关联到自动驾驶系统如何根据检测结果做出决策。
1.7 nuscenes官网中下载哪个数据集
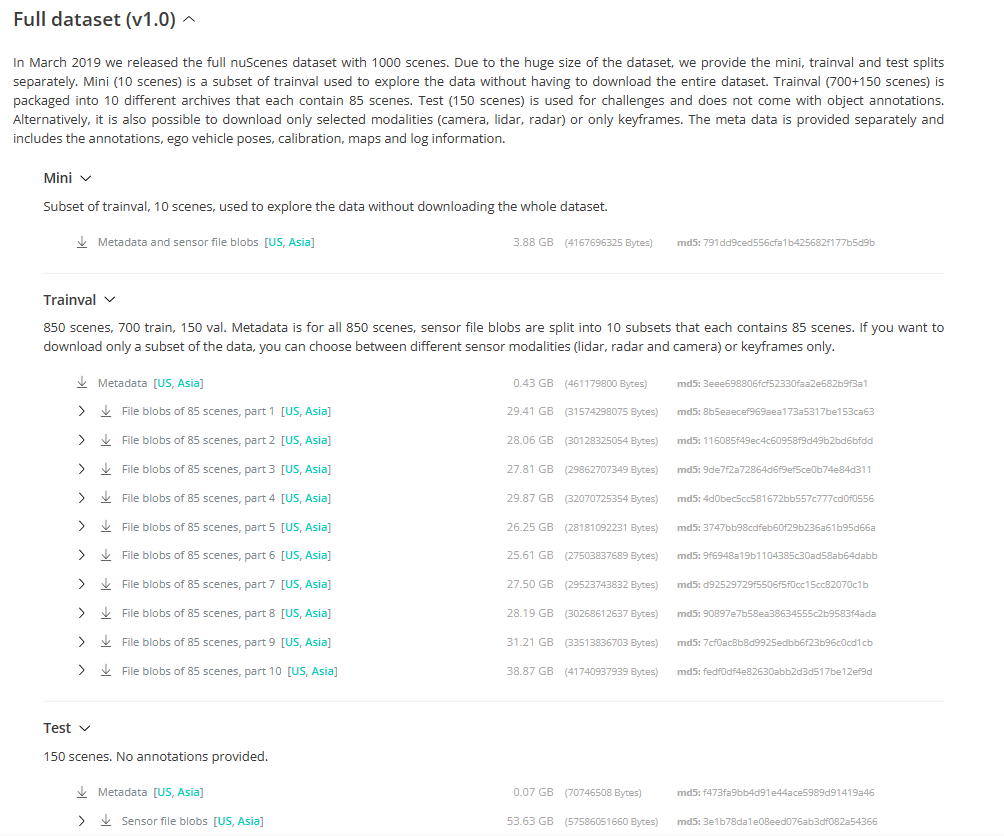
- nuscenes官网需要注册后才能下载数据集。
- 推荐下载Full dataset数据中Mini这个数据集,这是官方为我们提供的一个mini 版的数据集,总共3.88G。
- 最全的数据集为:Trainval + test, 它的数据比较大。
1.8 数据集官方教程
- 不需要自己电脑GPU,基本都能跑起来
https://colab.research.google.com/github/nutonomy/nuscenes-devkit/blob/master/python-sdk/tutorials/nuscenes_tutorial.ipynb
1.9 了解V1.0-mini数据
1.9.1 json文件的作用

可以看到V1.0-mini数据集中,包含了很多json文件,这些数据有什么作用呢
- “log”: 数据集采集的日志数量,记录数据采集过程中的相关信息。
- “scene”: 场景数量,表示数据集中的不同场景或驾驶情景。
- “sample”: 场景在特定时间戳下的一个带标注的快照。
- “sample_data”: 从特定传感器收集的数据。
- “category”: 数据集中的物体类别,例如车辆、行人、自行车等。human.pedestrian.police_officer、vehicle.motorcycle
- “attribute”: 物体属性数量,如颜色、行为等。vehicle.stopped、cycle.without_rider
- “visibility”: 物体可见性的数量,用于标识物体在图像中的可见程度。[1, 2, 3, 4]分别代表0-40-60-80-100

- “instance”: 物体实例数量,表示数据集中不同的物体实例。
- “sensor”: 传感器数量,表示用于数据采集的不同传感器设备。6 cam、1 lidar、5 radar
"calibrated_sensor": 经过标定的传感器数量,表示传感器的内外参数已经计算得到。"ego_pose": 特定timestamp自车位姿数量,表示车辆自身的位姿信息。rotation、translation表明。"sample_annotation": 包含样本注释数量,表示对样本数据进行的标注,如物体边界框3D Bounding Box、属性等。(关键帧标注)- “map”: 以二进制语义掩码形式存储的自顶向下视图的地图数据
1.9.2 官方网页可交互
https://www.nuscenes.org/nuscenes?sceneId=scene-0011&frame=0&view=regular

- 官方在
Explore模块,提供了一个可交互的工具,可以实时查看标注信息,更加直观。打开该网站,可以看到每个场景有40帧,因为20s的每个场景,每隔0.5s会标注一帧关键帧,因此一个场景可以查看40帧标注效果。 - 可以在
view的下拉菜单中选择nuScenes以及Scenes的下拉菜单中选择不同的场景进行查看。
1.10.1 总结
- 数据集使用Nuscenes数据集V1.0-mini
- V1.0-mini数据有10个scenes。8个用于训练,2个用于测试。
- V1.0-mini有404个sample,81个用于测试。
- camera原始数据大小:
1600*900 - sample与sweeps
- 23个类别,Bevfusion中只用了10个类别。
2. 点云的可视化
2.1 环境安装
(1) 首先,学习需要使用到nuScenes数据集。python工具需要使用到nuscenes-devkit、pyquaternion
- nuscenes-devkit 包安装
pip install nuscenes-devkit -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
- pyquaternion 包安装
pip install pyquaternion
- 包的引用
from nuscenes.nuscenes import NuScenes
from pyquaternion import Quaternion
(2) 安装vscode点云可视化插件
搜索point cloud找到插件vscode-pc-viewer, 点击安装即可。

安装好插件后,就可以用工具帮我们可视化点云。
注意:nuScenes中点云数据的格式为pcd.bin, 需要转换为kitti数据格式的binary file, 否则可视化的点云效果是不对的, 参考: https://github.com/PRBonn/lidar-bonnetal/issues/78

- 首先将数据保存为numapy.array的给
- 然后利用:
arr.astype('float32').tofile('filename.bin')保存为binary 文件
2.2 nuScenes数据集文件结构
(makefile) BEVFusion> tree BEVfusion/bevfusion/configs/nuscenes/ -L 1
|-- maps
|-- samples
|-- sweeps
`-- v1.0-mini6 directories, 1 file
|-- maps
| |-- 36092f0b03a857c6a3403e25b4b7aab3.png
| |-- 37819e65e09e5547b8a3ceaefba56bb2.png
| |-- 53992ee3023e5494b90c316c183be829.png
| `-- 93406b464a165eaba6d9de76ca09f5da.png
|-- samples
| |-- CAM_BACK
| |-- CAM_BACK_LEFT
| |-- CAM_BACK_RIGHT
| |-- CAM_FRONT
| |-- CAM_FRONT_LEFT
| |-- CAM_FRONT_RIGHT
| |-- LIDAR_TOP
| |-- RADAR_BACK_LEFT
| |-- RADAR_BACK_RIGHT
| |-- RADAR_FRONT
| |-- RADAR_FRONT_LEFT
| `-- RADAR_FRONT_RIGHT
|-- sweeps
| |-- CAM_BACK
| |-- CAM_BACK_LEFT
| |-- CAM_BACK_RIGHT
| |-- CAM_FRONT
| |-- CAM_FRONT_LEFT
| |-- CAM_FRONT_RIGHT
| |-- LIDAR_TOP # 里面文件格式pcd.bin
| |-- RADAR_BACK_LEFT
| |-- RADAR_BACK_RIGHT
| |-- RADAR_FRONT
| |-- RADAR_FRONT_LEFT
| `-- RADAR_FRONT_RIGHT
`-- v1.0-mini # 这里存了很多矩阵|-- attribute.json|-- calibrated_sensor.json|-- category.json|-- ego_pose.json|-- instance.json|-- log.json|-- map.json|-- sample.json|-- sample_annotation.json|-- sample_data.json|-- scene.json|-- sensor.json`-- visibility.json
2.3 可视化点云
2.3.1 代码实现可视化
import numpy as np
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm# 0. 首先,数据来源是v1.0-mini数据集内的 sweeps/LIDAR_TOP
file = "D:/Dataset/public/v1.0-mini/sweeps/LIDAR_TOP/n008-2018-08-01-15-16-36-0400__LIDAR_TOP__1533151603898164.pcd.bin"
pc = np.frombuffer(open(file, "rb").read(), dtype=np.float32)
# print(pc.shape) # (173760,)# 1. 了解数据结构,数据由5个部分组成# Data is stored as (x, y, z, intensity, ring index).# x y z 就是基于激光雷达的3d坐标系# intensity 反射强度,指的是,激光接收器接收的 1激光的反射次数# ring index 第几条线,激光有32线, 他就是1-32的数字。 课程中不用# 所以改变下形状输出print(pc.reshape(-1, 5)[0]) # [-2.942755 -0.59551746 -1.7575045 20. 0. ]
print(pc.reshape(-1, 5)[10]) # [-4.5377426 -0.5805964 -1.4302253 36. 10. ]pc = pc.reshape(-1, 5)[:, :4] # ring index 不用体现在代码中就是
pc.tofile("kitti.format.pcd.bin"这篇关于BevFusion (2): nuScenes 数据介绍及点云可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




