本文主要是介绍python爬取去哪网数据_利用Python爬取全国250m精度的人口数据、房价数据和公交站(线路)等数据(二)...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

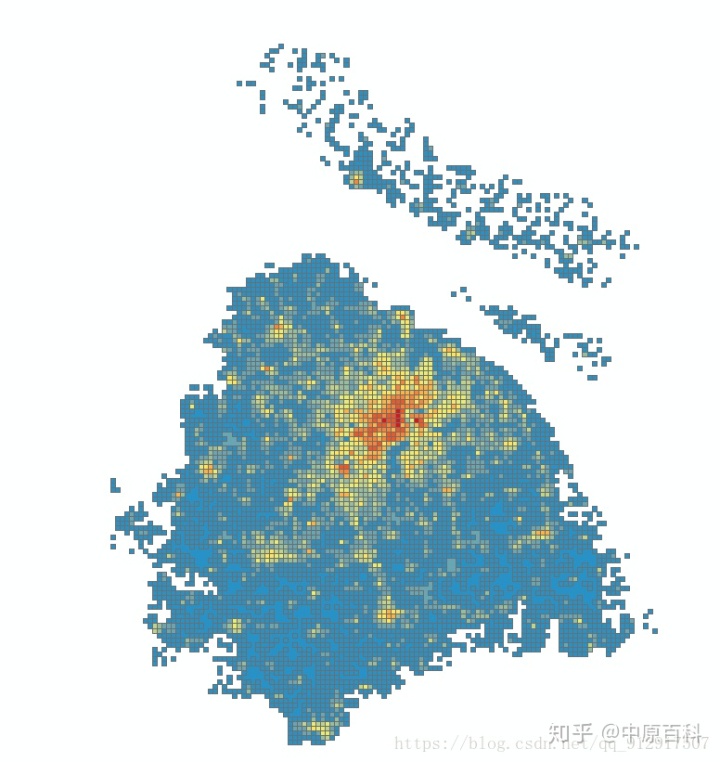
上一篇文章 利用Python爬取全国250m精度的人口数据、房价数据和公交站(线路)等数据(一) 介绍了如何爬取数据,但是没有介绍如何爬取全国数据,这篇文章具体介绍下。
import requests
import json
import pandas as pd
import time #地图范围 73.063112,2.995764,135.172386,53.802238header = {'Accept': '*/*','Accept-Language': 'en-US,en;q=0.8','Cache-Control': 'max-age=0','origin':'origin: https://editor.geoq.cn','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36','Connection': 'keep-alive','Referer': '你自己创建的链接'}
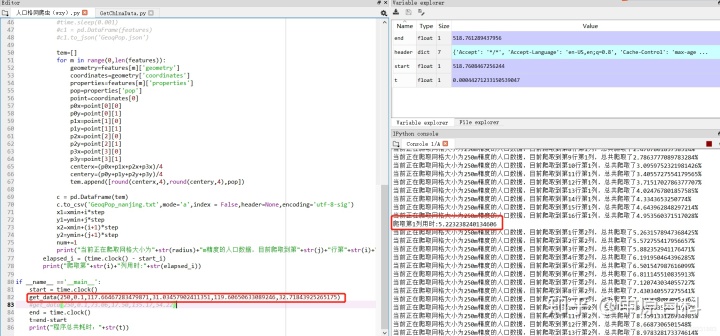
def get_data(radius=250,step=0.1,xmin=73.06,xmax=135.17,ymin=2.99,ymax=53.81):xlen=round((xmax-xmin)/step)ylen=round((ymax-ymin)/step)print(xlen)print(ylen)x1=xminx2=xmin+stepy1=yminy2=ymin+stepnum=0for i in range(1,xlen):start_i = time.clock()for j in range(1,ylen):time.sleep(0.001)values={"citycode":"000000","extent":"["+str(x1)+","+str(y1)+","+str(x2)+","+str(y2)+"]","inSR":"4326","outSR":"4326","grid":"square","radius":str(radius),"f":"geojson","condition":'{"pop":[]}'}url='https://editor.geoq.cn/editormobile/proxy.do?type=GeoDataService&handle=filterservice/regionfilter'response = requests.request('POST', url, data=values,headers = header)datas=response.textdictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式result=dictdatas['result']features=result['features']#time.sleep(0.001)#c1 = pd.DataFrame(features)#c1.to_json('GeoqPop.json')tem=[]for m in range(0,len(features)):geometry=features[m]['geometry']coordinates=geometry['coordinates']properties=features[m]['properties']pop=properties['pop']point=coordinates[0]p0x=point[0][0]p0y=point[0][1]p1x=point[1][0]p1y=point[1][1]p2x=point[2][0]p2y=point[2][1]p3x=point[3][0]p3y=point[3][1]centerx=(p0x+p1x+p2x+p3x)/4centery=(p0y+p1y+p2y+p3y)/4 tem.append([round(centerx,4),round(centery,4),pop])c = pd.DataFrame(tem)c.to_csv('GeoqChinaPop.txt',mode='a',index = False,header=None,encoding='utf-8-sig')x1=xmin+i*stepy1=ymin+j*stepx2=xmin+(i+1)*stepy2=ymin+(j+1)*stepnum+=1print("当前正在爬取网格大小为"+str(radius)+"m精度的人口数据,目前爬取到第"+str(j)+"行第"+str(i)+"列,"+"总共爬取了"+str(100*num/(xlen*ylen))+"%")elapsed_i = (time.clock() - start_i)print("爬取第"+str(i)+"列用时:"+str(elapsed_i))if __name__ =='__main__':start = time.clock()get_data(250,0.1,73.06,135.17,17.50,54.22)end = time.clock()t=end-startprint("程序总共耗时:"+str(t))可以利用get_data(250,0.1,73.06,135.17,17.50,54.22)这个函数来爬取全国的数据,范围是全国,为了避免漏掉数据,所以extent范围还是主动扩大了一些(这导致一开始可能会爬到很多空数据,消耗时间)按照全国这个范围,0.1度 循环下去,一共621列367行,一行测试出来爬取时间是262秒,如果要爬取全部一共要691天哈哈。
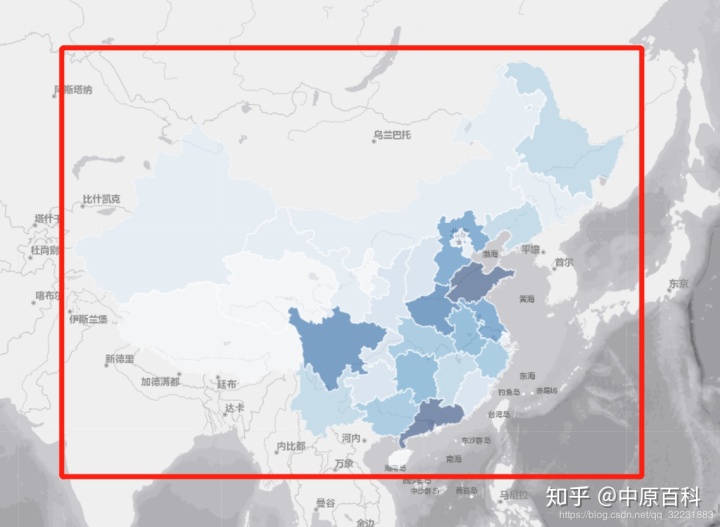
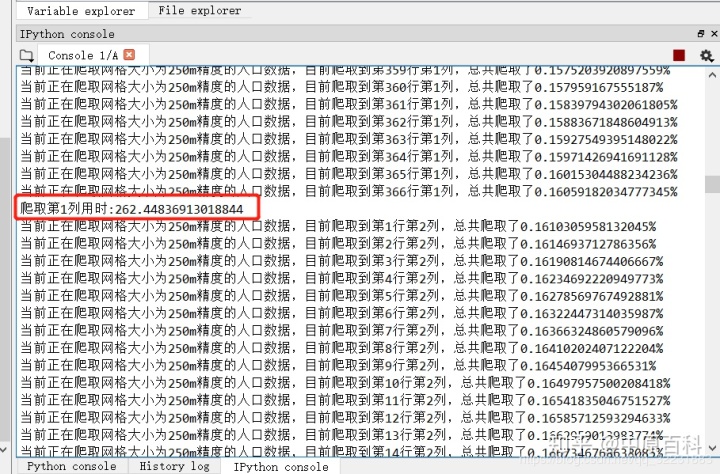
看来应该搞一个分布式了,这样太慢了,这里暂时先不管了,以后有时间再说。
还是先搞一个南京的吧,其他城市的我暂时也不需要,按照城市来的话挺快的。爬取第18列用时:6.261595580461972s
程序总共耗时:156.5806489491781s
其实如果想爬其他数据也很简单,只要把参数换一下,然后查看其response数据格式,和人口的一模一样

# -*- coding: utf-8 -*-
"""
Created on Thu Mar 28 17:11:01 2019@author: 武状元
"""
import requests
import json
import pandas as pd
import time #地图范围 73.063112,2.995764,135.172386,53.802238header = {'Accept': '*/*','Accept-Language': 'en-US,en;q=0.8','Cache-Control': 'max-age=0','origin':'origin: https://editor.geoq.cn','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36','Connection': 'keep-alive','Referer': '你自己的链接'}
def get_data(radius=250,step=0.1,xmin=73.06,ymin=2.99,xmax=135.17,ymax=53.81):xlen=round((xmax-xmin)/step)ylen=round((ymax-ymin)/step)print(xlen)print(ylen)x1=xminx2=xmin+stepy1=yminy2=ymin+stepnum=0for i in range(1,xlen):start_i = time.clock()for j in range(1,ylen):time.sleep(0.001)values={"citycode":"000000","extent":"["+str(x1)+","+str(y1)+","+str(x2)+","+str(y2)+"]","inSR":"4326","outSR":"4326","grid":"square","radius":str(radius),"f":"geojson","condition":'{"estate_avg_price":[]}'}url='https://editor.geoq.cn/editormobile/proxy.do?type=GeoDataService&handle=filterservice/regionfilter'response = requests.request('POST', url, data=values,headers = header)datas=response.textdictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict格式result=dictdatas['result']features=result['features']tem=[]for m in range(0,len(features)):geometry=features[m]['geometry']coordinates=geometry['coordinates']properties=features[m]['properties']estate_avg_price=properties['estate_avg_price']point=coordinates[0]p0x=point[0][0]p0y=point[0][1]p1x=point[1][0]p1y=point[1][1]p2x=point[2][0]p2y=point[2][1]p3x=point[3][0]p3y=point[3][1]centerx=(p0x+p1x+p2x+p3x)/4centery=(p0y+p1y+p2y+p3y)/4 tem.append([round(centerx,4),round(centery,4),estate_avg_price])c = pd.DataFrame(tem)c.to_csv('GeoqPrice_nanjing.txt',mode='a',index = False,header=None,encoding='utf-8-sig')x1=xmin+i*stepy1=ymin+j*stepx2=xmin+(i+1)*stepy2=ymin+(j+1)*stepnum+=1print("当前正在爬取网格大小为"+str(radius)+"m精度的平均房价数据,目前爬取到第"+str(j)+"行第"+str(i)+"列,"+"总共爬取了"+str(100*num/(xlen*ylen))+"%")elapsed_i = (time.clock() - start_i)print("爬取第"+str(i)+"列用时:"+str(elapsed_i))if __name__ =='__main__':start = time.clock()get_data(250,0.1,117.66467283479871,31.03457902411351,119.60650633089246,32.71843925265175)#get_data(250,0.1,73.06,17.50,135.17,54.22)end = time.clock()t=end-startprint("程序总共耗时:"+str(t))之后测试大概用了178秒,南京250m格网房价数据爬取完毕。
这篇关于python爬取去哪网数据_利用Python爬取全国250m精度的人口数据、房价数据和公交站(线路)等数据(二)...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





