本文主要是介绍《LLM in a Flash: Efficient Large Language Model Inference with Limited Memory》论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Gary Li
时间:2024-1-9
(由于我不是研究大模型的,对AI也知之甚少,我主要关注存储相关的内容。并且本文并未正式发表有许多不规范和写作表达不清的地方,因此有许多我不理解的地方,也有许多我按照自己的理解记下的内容,如有错误请见谅。)
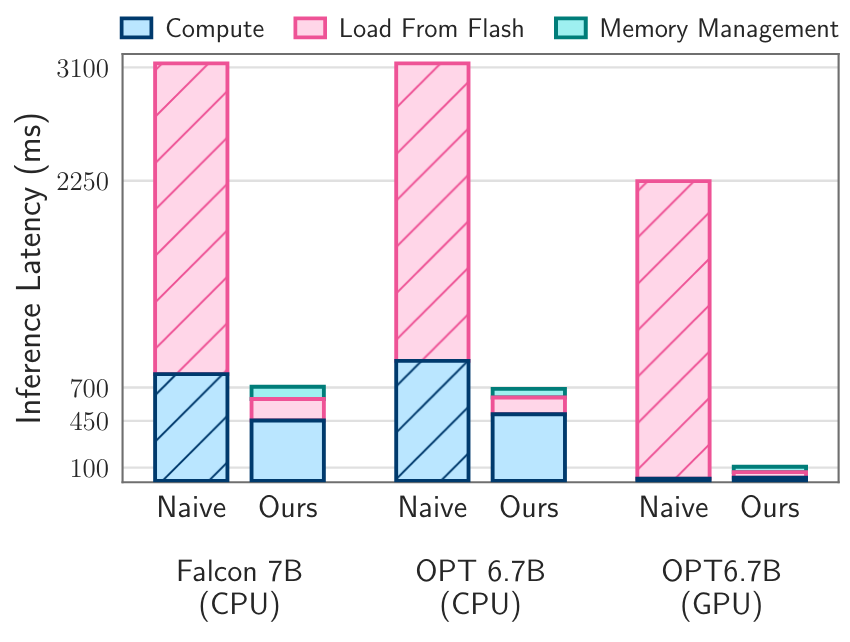
背景:大模型难以运行在内存受限的边端设备上(使用半浮点精度加载有7B参数的模型时需要约14GB内存)。当可用内存小于模型参数规模,会导致大量的I/O开销。如下图所示,当可用内存只有模型参数量大小一半时,IO加载占据了延迟中的绝大部分。因为在每次推理时,可能都重新加载整个模型(LRU会把最早的参数剔除,因此如果顺序读取参数,缓存永远都是miss)
机会:
- FFN具有90%以上的稀疏性(ReLU 激活函数自然会在 FFN 的中间输出中产生 90% 以上的稀疏性,利用这一特性可以减少这些稀疏输出的后续层的内存占用)。因此有些数据可以不用读取。
- 当充分利用Flash的性能时(大粒度连续读取并充分并发时),闪存的性能可以匹配上稀疏LLM模型的推理速度
思路:
总体思路就是减少数据读取量。主要有以下几个方法:
- 压缩:通过预测技术,不加载为0的参数或者输出为0的参数。
- 缓存:仅加载最近几个token的参数,并复用最近计算过的token的激活
- 提高读效率:将上投影层和下投影层的行和列连接起来存储,以便从闪存中读取更大的连续块。
具体方案:
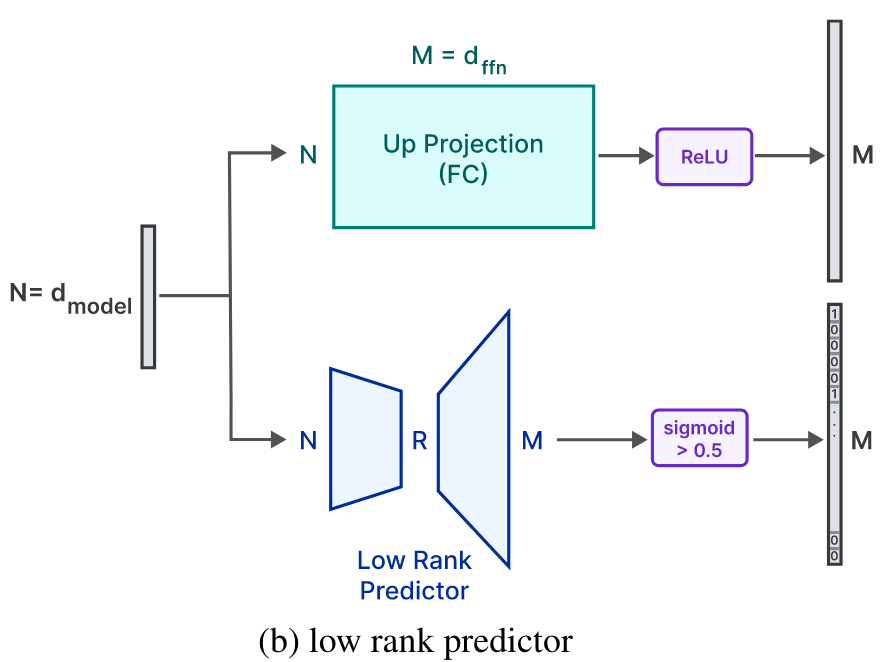
1. 压缩:动态加载FFN(Feed-Forward Network)的非稀疏段到内存中,注意力网络的权重驻留在内存中(约占1/3),避免加载整个模型。具体做法是通过一个低秩预测器(low-rank predictor)来确定0元素,如下图所示。(不是很懂具体原理和流程,原文介绍得很粗糙)
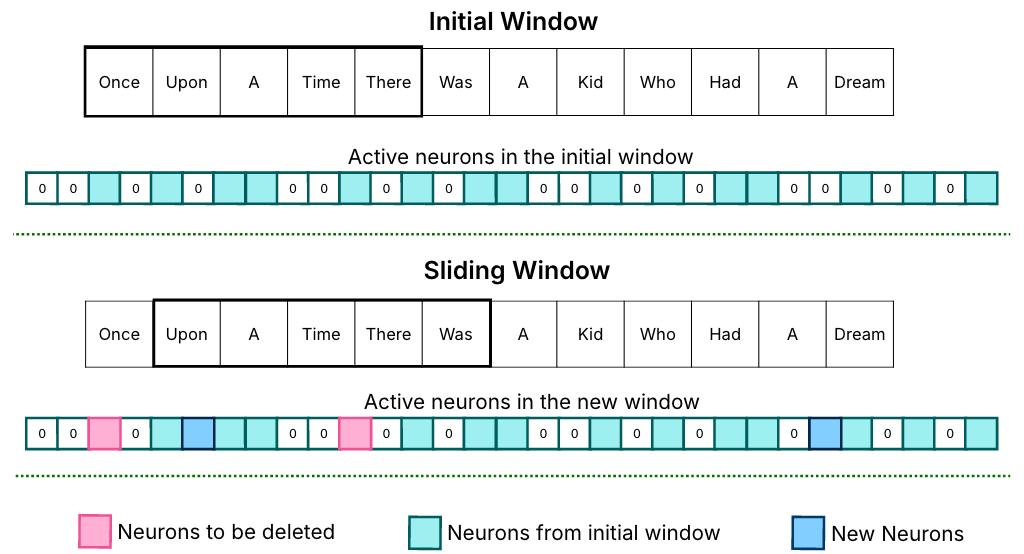
2. 缓存:采用了一个滑动窗口,如下图所示。滑动窗口的目的是仅在内存中保存最近几个输入数据的神经元数据(不懂指的什么,原文就写了一个neuron data)。以此做到选择性地加载神经元,并及时清理窗口外的非活动神经元。
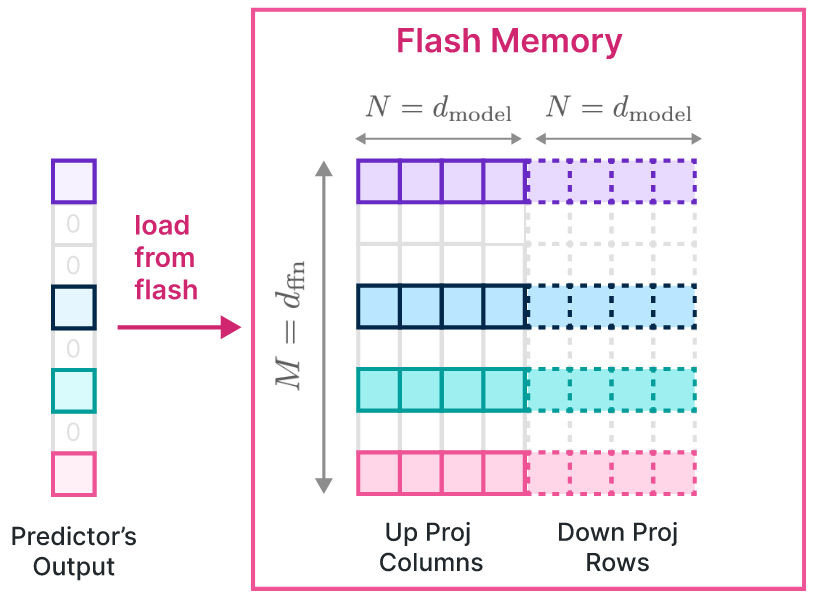
3. 大粒度:该论文观察到了一个现象,在一些模型(OPT、Falcon)中,上投影的第i列和下投影的第i行共享第i个中间神经元的激活一致(不懂)。因此为了提高I/O的粒度,将这些对应的列和行一起存储在闪存中,将数据合并为一个更大的块。
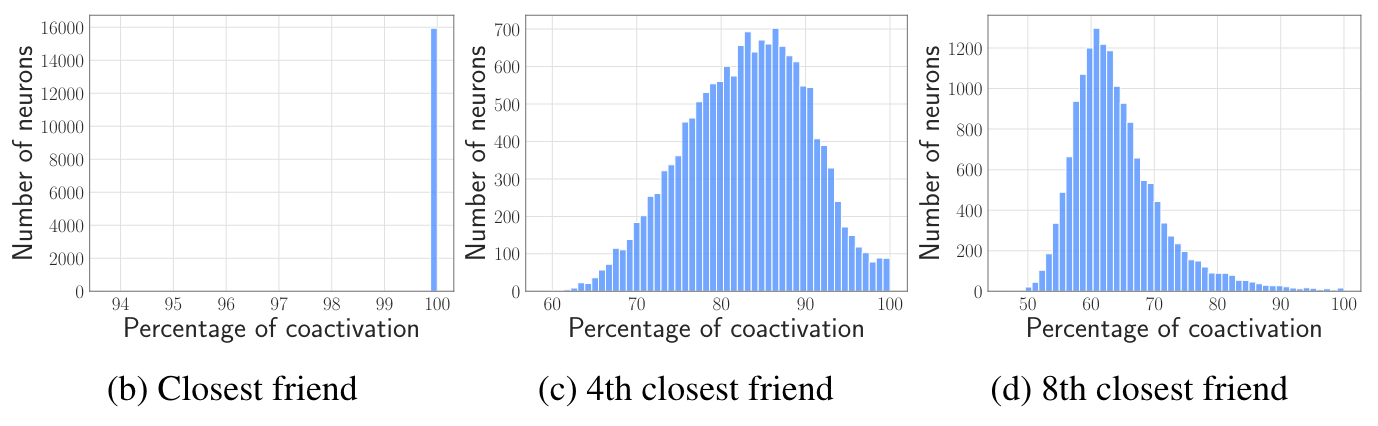
此外还观察到存在神经元同激活现象,即神经元总是与其他一些神经元共同激活。如下图所示,每个神经元有几乎100%的概率与第一个同激活神经元共同激活,第4个同激活神经元也有平均86%的概率共同得到激活。因此将他们集中存储起来,当一个神经元激活时同时预读共同激活的神经元。然而他们并没有使用这一特性,因为有一些极其活跃的神经元总是与其他神经元共同激活,因此会导致大量额外的读取,造成反作用。
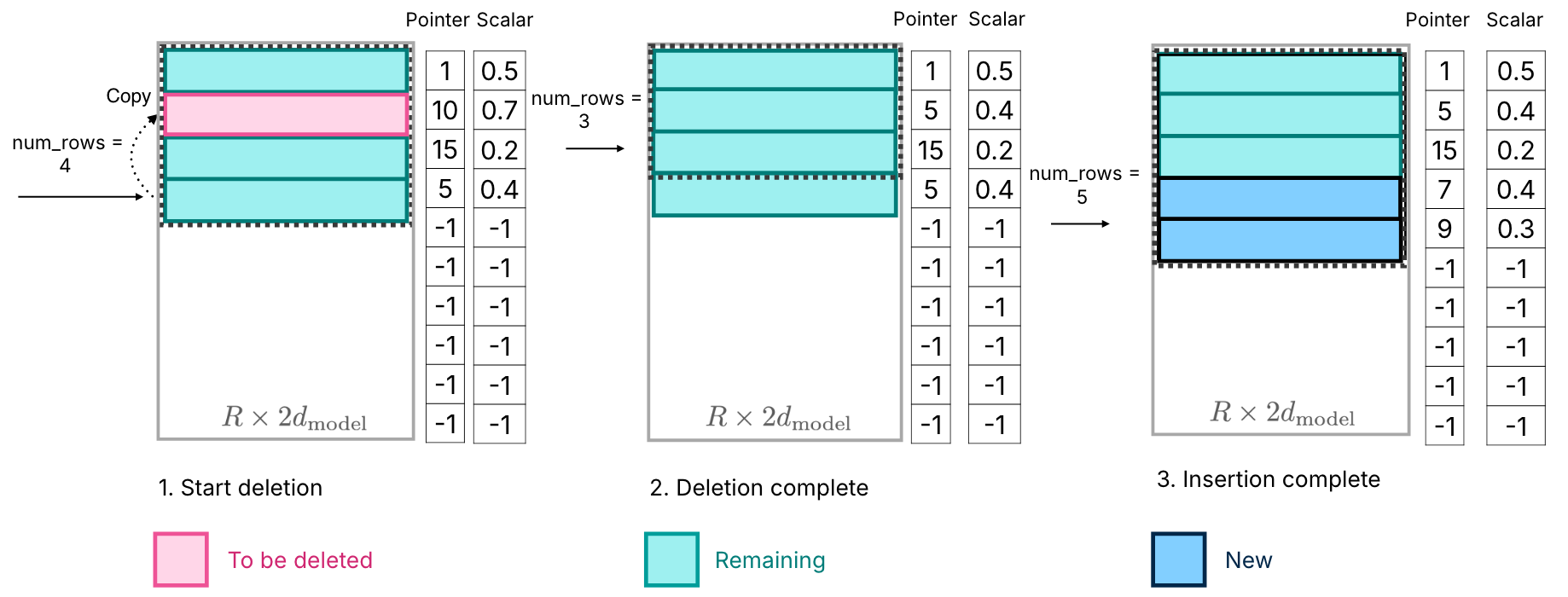
4. 为了提高内存管理的效率,避免内存中神经元删除和插入的开销,采用了一种简单低开销的神经元管理方法。如下图所示,用数组存储神经元。当删除了一个神经元时,从数组末尾拷贝一个神经元到删除位置,插入时就可以直接向末尾插入即可。(但是这样的话数据就是乱的,检索开销不会很高吗;而且还是会导致额外的数据拷贝,直接向空位插不是更好?)
实验:
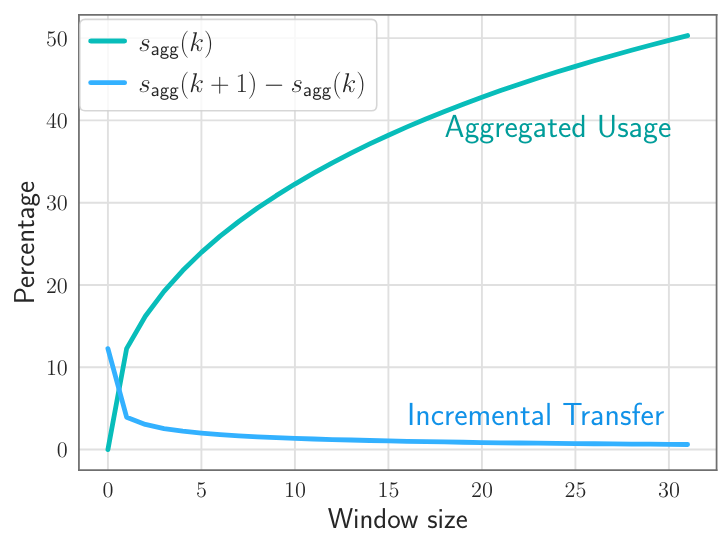
1. Sagg(k)代表在处理第k个输入token时的累计神经元使用量(不太理解k到底代表什么)。Sagg(k+1)-Sagg(k)代表窗口每向后滑动一次需要新加载的神经元。从下图可以看出,当窗口越大时,每次需要加载的新神经元就越少。这个很好理解,相当于缓存越大命中率就越高需要加载的数据就越少。因此在内存允许的情况下窗口大小越大越好。
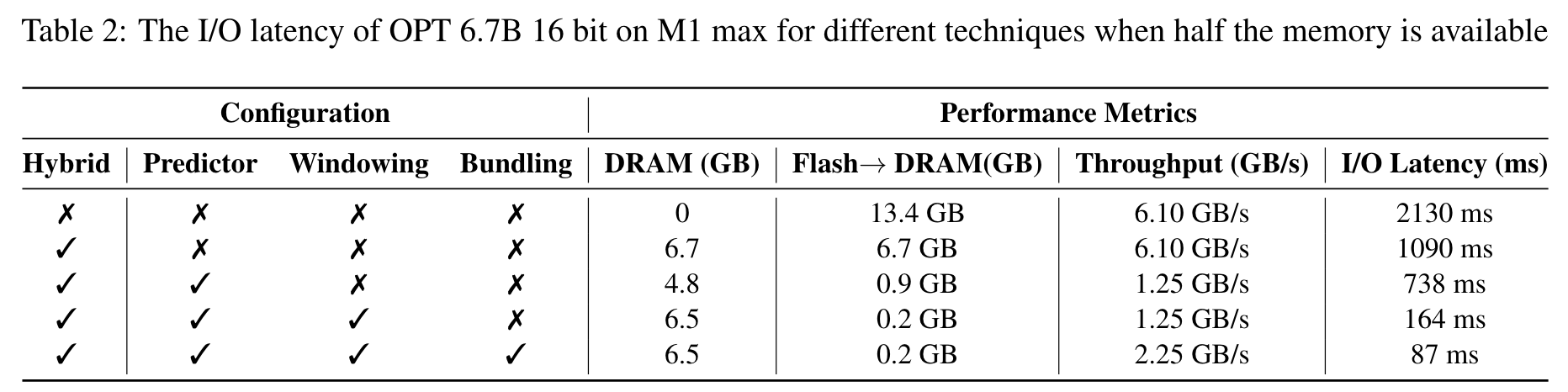
2. 实验平台:Apple M1 Max,1TB SSD,内存控制为模型大小的一半。可以看出本文的方法可以减少大量的数据传输(Flash->DRAM列),并且大量减少IO延迟。
思考:
- 这些技术看起来可以在通用场景下运用,比如不计算0的神经元?
- 具体的与大模型相关的部分有点难以理解,但是核心思想可以学习。首先是观察workload中是否有稀疏的数据或者可以重用的数据,降低数据的读取次数;其次是可以尝试通过降低结果精度或者额外的少量计算降低I/O次数提升总体性能;是否存在强局部性的数据,一是可以减少I/O次数,二是可以将他们集中存储提高读取速度。
这篇关于《LLM in a Flash: Efficient Large Language Model Inference with Limited Memory》论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








