本文主要是介绍初步处理爬取到的150708个单词的数据(原始网页文档格式,包含注音、释义与例句,等等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言:
正文:
前言:
在正式介绍处理数据前先放出本次实验所用服务器与笔记本的配置以及其他一些工具的版本信息。服务器配置:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
Stepping: 1
CPU MHz: 2494.222
BogoMIPS: 4988.44
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 40960K
NUMA node0 CPU(s): 0
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
笔记本配置:
Host Name: DESKTOP-UBDN0UL
OS Name: Microsoft Windows 10 Pro N for Workstations
OS Version: 10.0.18363 N/A Build 18363
OS Manufacturer: Microsoft Corporation
OS Configuration: Standalone Workstation
OS Build Type: Multiprocessor Free
Registered Owner: hadoop001
Registered Organization:
Product ID: 00392-30000-00001-AA159
Original Install Date: 2020-01-29, 07:48:44
System Boot Time: 2020-05-02, 00:37:38
System Manufacturer: Dell Inc.
System Model: G3 3579
System Type: x64-based PC
Processor(s): 1 Processor(s) Installed.[01]: Intel64 Family 6 Model 158 Stepping 10 GenuineIntel ~2304 Mhz
BIOS Version: Dell Inc. 1.2.1, 2018-07-18
Windows Directory: C:\Windows
System Directory: C:\Windows\system32
Boot Device: \Device\HarddiskVolume5
System Locale: en-us;English (United States)
Input Locale: en-us;English (United States)
Time Zone: (UTC+08:00) Beijing, Chongqing, Hong Kong, Urumqi
Total Physical Memory: 16,245 MB
Available Physical Memory: 7,745 MB
Virtual Memory: Max Size: 20,484 MB
Virtual Memory: Available: 3,122 MB
Virtual Memory: In Use: 17,362 MB
Page File Location(s): C:\pagefile.sys
Domain: WORKGROUP
Logon Server: \\DESKTOP-UBDN0UL
Hotfix(s): 12 Hotfix(s) Installed.[01]: KB4537572[02]: KB4513661[03]: KB4516115[04]: KB4517245[05]: KB4521863[06]: KB4524244[07]: KB4528759[08]: KB4537759[09]: KB4538674[10]: KB4541338[11]: KB4552152[12]: KB4549951
Network Card(s): 3 NIC(s) Installed.[01]: Realtek PCIe GbE Family ControllerConnection Name: EthernetStatus: Media disconnected[02]: Intel(R) Wireless-AC 9462Connection Name: Wi-FiDHCP Enabled: YesDHCP Server: 192.168.43.1IP address(es)[01]: 192.168.43.58[02]: fe80::852e:ffd6:7cee:e82[03]: Bluetooth Device (Personal Area Network)Connection Name: Bluetooth Network ConnectionStatus: Media disconnected
Hyper-V Requirements: VM Monitor Mode Extensions: YesVirtualization Enabled In Firmware: YesSecond Level Address Translation: YesData Execution Prevention Available: Yes
PyCharm版本信息:
PyCharm 2019.3.4 (Professional Edition)
Build #PY-193.6911.25, built on March 18, 2020
Licensed to hadoop001Runtime version: 11.0.6+8-b520.43 amd64
VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Windows 10 10.0
GC: ParNew, ConcurrentMarkSweep
Memory: 1963M
Cores: 8
Registry:
Non-Bundled Plugins: R4Intellij, aws.toolkit
Python版本信息:
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Oracle与PL/SQL版本信息:
PL/SQL DeveloperVersion 13.0.6.1911 (64 bit)01.226959 - Unlimited user licenseService Contract: 9999-12-31Windows 10 Build 18362Physical memory : 16,634,436 kB (8,109,864 available)Paging file : 20,975,672 kB (3,284,548 available)Virtual memory : 137,438,953,344 kB (137,433,621,920 available)ParametersD:\PLSQL Developer 13\plsqldev.exePreferencesSession mode: MultiOCI Library: <none>Use OCI7: FalseAllow Multiple Connections: TruePreference FilesD:\PLSQL Developer 13\Preferences\Default\Default.iniC:\Users\hadoop001\AppData\Roaming\PLSQL Developer 13\Preferences\hadoop001\default.iniLicense FileC:\Users\hadoop001\AppData\Roaming\PLSQL Developer 13\aalf.datDebug fileD:\PLSQL Developer 13\PlSqlDev.elfPlug-Ins*Active Query Builder (D:\PLSQL Developer 13\PlugIns\ActiveQueryBuilder.dll)*PL/SQL Documentation (plsqldoc) (D:\PLSQL Developer 13\PlugIns\plsqldoc.dll)(* is Active)AliasesLISTENER_ORCLORACLR_CONNECTION_DATAORCLHomesOraDB19Home1 (D:\WINDOWS.X64_193000_db_home)DLLsD:\WINDOWS.X64_193000_db_home\bin\oci.dllTNS FileD:\instantclient_19_5\tnsnames.oraUsingHome: OraDB19Home1DLL: D:\WINDOWS.X64_193000_db_home\bin\oci.dllOCI: version 12.1 (19.3.0.0.0)Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 Character SetsCharacter size: 4 byte(s)CharSetID: 873NCharSetID: 2000Unicode Support: TrueNLS_LANG: AMERICAN_AMERICA.AL32UTF8NLS_NCHAR_CHARACTERSET: AL16UTF16NLS_CHARACTERSET: AL32UTF8ProcessWorking Set = 132,890,624Memory = 33,325,392GDI Objects = 1525User Objects = 547Handles = 1065MonitorPixelsPerInch = 120Id = 0PPI = 120Primary = TrueHandle = 65537Left = 0Top = 0Width = 1920Height = 1080MainFormOnTaskbar = True
正文:
在服务器上运行一段很简单的爬虫,爬取了必应在线词典的150708个单词搜索结果的网页,具体的代码与步骤已经在上一篇博文
里面介绍过了,此处不赘述。最终所得结果是150708个TXT文档,博主将其按照原始单词的数字前缀放到不同的文件夹,如图1所
示。

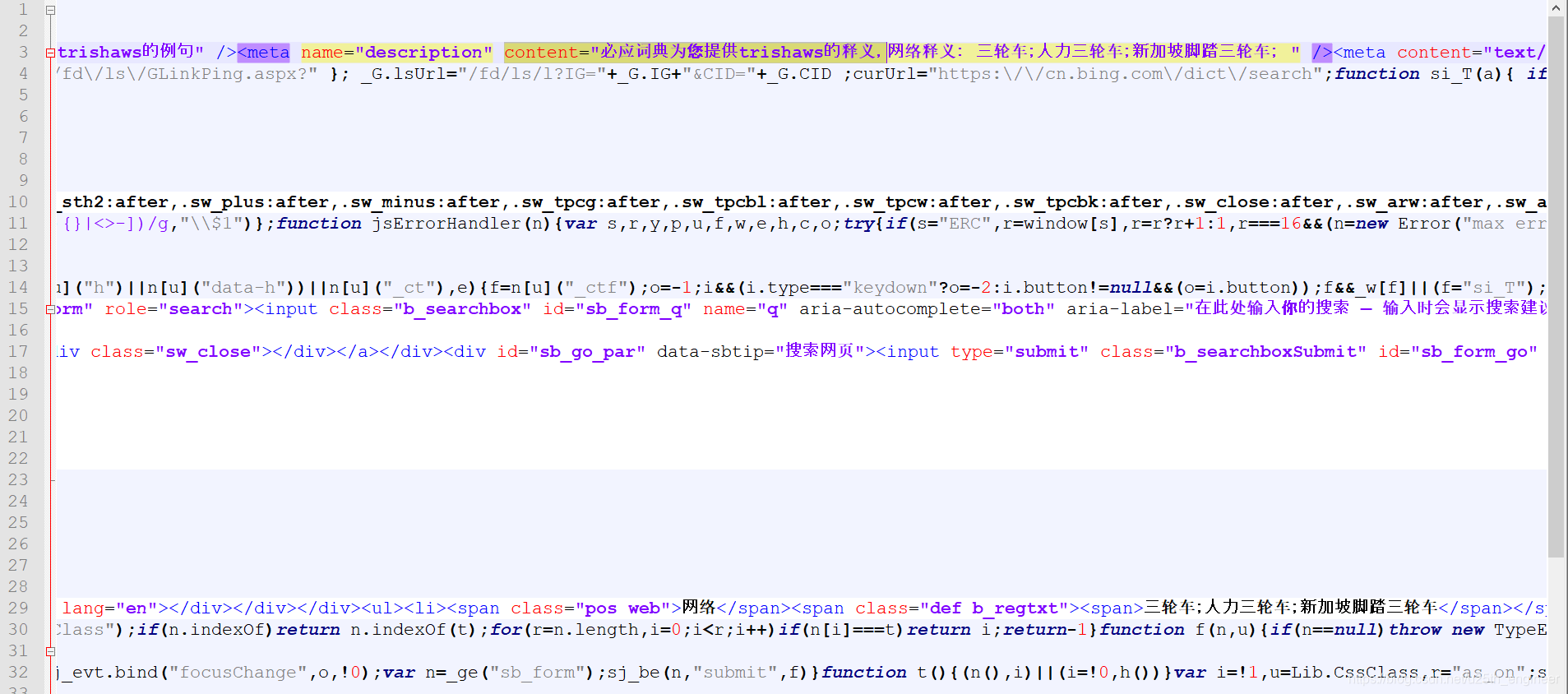
因如上一篇博文所述,我只是简单地爬取了网页的页面HTML源代码,没有仔细处理JS等所包含的内容,因此文本中所含有效信
息很少,经过筛查发现:只有单词的读音和释义是完整的信息,方便提取,例句等其他内容夹杂在很多标签里面,如图2与图3所示。

为了提取各个文件中单词的读音与释义,博主使用了如下代码来处理,主要使用了正则表达式来匹配,代码中有相应注释。
#-*- coding : utf-8 -*-
# coding: utf-8import re
import osdef openFile(path):fileNames = os.listdir(path)files = [] #目录下所有文件的内容所构成的列表,形式为:13_phytochemical.txtvocabularyList = [] #所有单词组成的列表,也即文件名去掉前缀之后的形式prefixList = [] #所有文件名的前缀构成的列表cnt = 0for fileName in fileNames:file = open(path + fileName, encoding='UTF-8')vocabularyList.append(fileName.replace(".txt", ""))pretfix = re.search(r'^\d.*[_]', fileName, flags = 0) #匹配前缀prefixList.append(pretfix.group())st = file.read() #读取整个文件cnt += 1files.append(st) #将新的文件内容添加到列表中return files, vocabularyList, prefixList #返回的是3个列表def filterFiles(path):rule_name = r'content="必应词典为您提供.*; "''''因为我直接爬取的纯HTML页面,没有处理cookie等内容(里面包含了完整的例句、单词联想等),所以得到的文本很简陋。看了之后发现只有給出的单词释义和读音还比较完整,因此此处的正则表达式仅仅对其进行匹配。'''removeFiles = []'''我本来想着将单词释义与读音提出出来另存为文件后就把原来的文件删了,但发现有些文件里面包含了单词释义但并未被提取出来,还被直接給删了。试了几种方法,最终决定:先尝试将存储在文件夹A中的所有文件的单词释义提取出来,并以相同的文件名存储在B文件夹,接着判断在A文件夹中是否含有与B文件夹文件名相同的文件,如有则删除。删除操作应在单词释义提取之后立刻判断是否进行,否则复制的文件会越来越多,最终可能超过服务器的承载极限。'''compile_name = re.compile(rule_name, re.M) #正则表达式匹配files, vocabularyList, prefixList = openFile(path)result = []for st in files:removeFiles.append(st)res_name = compile_name.findall(str(st))result += res_namereturn result, vocabularyList, prefixList, removeFiles #返回的是4个列表def deleteFiles(removeFilePath, storageFilePath): #两个路径removeFiles = os.listdir(removeFilePath)for file in removeFiles:fuckFile = storageFilePath + fileif os.path.exists(fuckFile):os.remove(fuckFile)if __name__ == '__main__':for cnt in range(0, 21):removeFilePath = "/home/crawler/" + str(cnt) + "/" #store the original datastorageFilePath = "/home/crawler/" + str(cnt) + "_result/" #store the accessed datalines, vocabularyList, prefixList, removeFiles = filterFiles(removeFilePath)for st in lines:mylog = open(storageFilePath + vocabularyList[cnt] + ".txt", mode = 'w', encoding = 'utf-8') #以相同文件名存储在另一个文件夹print("word=" + "\"" + vocabularyList[cnt].replace(prefixList[cnt], "") + "\"" + "\n" + st, file = mylog)mylog.close() #关闭文件deleteFiles(storageFilePath, removeFilePath) #提取完可能存在的单词释义后,立即将原文件删除cnt += 1 #接着使用余下的单词与文件名前缀
值得一提的是,如上所示代码在服务器上运行的过程中,极为容易“卡死”——程序莫名其妙就不运行了,试了几次都是如此。
博主曾经让程序运行了一个晚上,到第二天早上还是没有跑出什么结果来,再次运行时居然还会报“列表访问越界”的错。因此,索
性便对代码进行了简单的修改:不用循环遍历文件夹,而是每次执行完毕后手动修改再运行,如下所示。
#-*- coding : utf-8 -*-
# coding: utf-8import re
import osdef openFile(path):fileNames = os.listdir(path)files = [] #目录下所有文件的内容所构成的列表,形式为:13_phytochemical.txtvocabularyList = [] #所有单词组成的列表,也即文件名去掉前缀之后的形式prefixList = [] #所有文件名的前缀构成的列表cnt = 0for fileName in fileNames:file = open(path + fileName, encoding='UTF-8')vocabularyList.append(fileName.replace(".txt", ""))pretfix = re.search(r'^\d.*[_]', fileName, flags = 0) #匹配前缀prefixList.append(pretfix.group())st = file.read() #读取整个文件cnt += 1files.append(st) #将新的文件内容添加到列表中return files, vocabularyList, prefixList #返回的是3个列表def filterFiles(path):rule_name = r'content="必应词典为您提供.*; "''''因为我直接爬取的纯HTML页面,没有处理cookie等内容(里面包含了完整的例句、单词联想等),所以得到的文本很简陋。看了之后发现只有給出的单词释义和读音还比较完整,因此此处的正则表达式仅仅对其进行匹配。'''removeFiles = []'''我本来想着将单词释义与读音提出出来另存为文件后就把原来的文件删了,但发现有些文件里面包含了单词释义但并未被提取出来,还被直接給删了。试了几种方法,最终决定:先尝试将存储在文件夹A中的所有文件的单词释义提取出来,并以相同的文件名存储在B文件夹,接着判断在A文件夹中是否含有与B文件夹文件名相同的文件,如有则删除。删除操作应在单词释义提取之后立刻判断是否进行,否则复制的文件会越来越多,最终可能超过服务器的承载极限。'''compile_name = re.compile(rule_name, re.M) #正则表达式匹配files, vocabularyList, prefixList = openFile(path)result = []for st in files:removeFiles.append(st)res_name = compile_name.findall(str(st))result += res_namereturn result, vocabularyList, prefixList, removeFiles #返回的是4个列表def deleteFiles(removeFilePath, storageFilePath): #两个路径removeFiles = os.listdir(removeFilePath)for file in removeFiles:fuckFile = storageFilePath + fileif os.path.exists(fuckFile):os.remove(fuckFile)if __name__ == '__main__':for cnt in range(0, 21):removeFilePath = "/home/crawler/" + str(cnt) + "/" #store the original datastorageFilePath = "/home/crawler/" + str(cnt) + "_result/" #store the accessed datalines, vocabularyList, prefixList, removeFiles = filterFiles(removeFilePath)for st in lines:mylog = open(storageFilePath + vocabularyList[cnt] + ".txt", mode = 'w', encoding = 'utf-8') #以相同文件名存储在另一个文件夹print("word=" + "\"" + vocabularyList[cnt].replace(prefixList[cnt], "") + "\"" + "\n" + st, file = mylog)mylog.close() #关闭文件deleteFiles(storageFilePath, removeFilePath) #提取完可能存在的单词释义后,立即将原文件删除cnt += 1 #接着使用余下的单词与文件名前缀
如上所示代码的不足就是每次运行都需要再手动修改程序中的变量值,即使如此,程序还是无法一次性将既定文件夹下的文件全
部处理完。
博主原意拟生成的包含提取出的单词注音与释义的文件的格式是:
文件名:
5_grallatores.txt
文件内容:
word="grallatores"
content="必应词典为您提供steinbock的释义,美[s'taɪnbɒk],英[s'taɪnbɒk],abbr. 同“ibex”;同“steenbok”; 网络释义: 北山羊;史坦巴克;摩羯星座; "
在服务器上初步处理的结果与我的预想基本一致,但如处理代码的注释所述,有些文本本身含有单词的注音与释义,但程序每次
提取的过程中都会遗漏掉若干个文件:少则几个,多则几百个。不论实验多少次,结果都是会有文本被遗漏。为了图省事,在服务器
上对所有文件处理了一遍之后,博主就将所有已经成功处理出的结果与遗漏的文件打包压缩,下载到本地(使用工具FileZilla),再
另寻他法。
对如上所示的第二段代码稍作修改,便用在了本地提取内容的操作中,为了避免遗漏处理的情况再次出现(但结果还是出现了)
和图省事,博主索性将所有功能写成一个“大杂烩”而不再写成函数,具体如下所示。
#-*- coding : utf-8 -*-
# coding: utf-8import re
import os
import syspath = "E://Document/English_Learning_Materials/crawler/large/"files = []
vocabularyList = []
# removeFiles = []
prefixList = []tot = 0
fileNames = os.listdir(path)
for fileName in fileNames:file = open(path + fileName, encoding='UTF-8')vocabularyList.append(fileName.replace(".txt", ""))prefix = re.search(r'^\d.*[_]', fileName, flags=0) # 匹配前缀prefixList.append(prefix.group())st = file.read()files.append(st)print(tot + 1)tot += 1# print(files)
rule_name = r'content="必应词典为您提供.*; "'
result = []
compile_name = re.compile(rule_name, re.M)
for st in files:res_name = compile_name.findall(str(st))result += res_nameprint(result)
cnt = 0
for s1 in result:mylog = open(path + vocabularyList[cnt] + ".log", mode='w', encoding='utf-8')print("word=" + "\"" + vocabularyList[cnt].replace(prefixList[cnt], "") + "\"" + "\n" + s1, file = mylog)# removeFiles.append(vocabularyList[cnt] + ".txt")print("************")mylog.close()cnt += 1# for x in removeFiles:
# print(x)
# fuckFile = str( path + x )
# if os.path.exists(fuckFile):
# os.remove(fuckFile)
每次执行完毕后,都必须将.log文件及其与之同名的.txt文件移动到另一个文件夹,再运行代码处理剩余的TXT文件,几个来回才
把所有文件处理完,本地运行预想的结果也是如上所示的格式。然而,这次却出问题了,如图4所示。

问题很明显:所得的结果文件的标题与提取到的内容不匹配,同前几次的经历一样,博主又反复进行了几次实验,但结果依然如
此——太打击蒟蒻了。不过幸亏博主从原始文件提取的是内容都是如下所示的格式:
content="必应单词为您提供..."
而不是直接将“单纯”的释义,这样一来博主可以在“content”的内容中依次将单词及其注音与释义提取处理。思路和前面的差不
多,即:打开文件、正则表达式匹配、新建文件读回提取到的内容,同时本次操作不再将每个单词及其注音与释义分别存放在不同的
文件,而是统一放在一个文件里面。所用代码如下所示。
#-*- coding : utf-8 -*-
# coding: utf-8import re
import os
import syssourcePath = "E://Document/English_Learning_Materials/crawler/result/"
errorPath = "E://Document/English_Learning_Materials/crawler/"
resultPath = "E://Document/English_Learning_Materials/crawler/"result = []
vocabularyList = []
removeFiles = []rule_name = r'content="必应词典为您提供.*; "'
tot = 0
i = 0
compile_name = re.compile(rule_name, re.M)fileNames = os.listdir(sourcePath)
# print(fileNames)
OMG_flag = -1for fileName in fileNames:file = open(sourcePath + fileName, encoding='UTF-8')vocabularyList.append(fileName.replace(".txt", ""))prefix = re.search(r'^\d.*[_]', fileName, flags=0) # 匹配前缀st = file.read()if( OMG_flag == -1 and st.find( "'", 0, len(st) ) ):print("OMG! NO!")OMG_flag += 1res_name = compile_name.findall(str(st))# print("res_name: " + str(res_name))if( len(res_name) != 0 ):result.append(res_name)if(len(res_name) == 0):removeFiles.append( fileName )print(tot + 1)print(vocabularyList[i])tot += 1print("Preprocessing: " + str(i + 1) )i += 1# if(tot > 3):# breakcnt = 0
for s1 in removeFiles:mylog = open(errorPath + "error.log", mode='a', encoding='utf-8')print( str(cnt + 1) + "\n" + str(s1), file = mylog)#print("************")# print("s1 = " + s1)mylog.close()cnt += 1myRule2 = r'content=.*释义,'
compile_name2 = re.compile(myRule2, re.M)myRule3 = r' "'
compile_name3 = re.compile(myRule3, re.M)flag = -1;# testDic = {}finishCNT = 1for s2 in result:myList = open(resultPath + "myDicts.csv", mode='a', encoding='utf-8')if(flag == -1):print("word,meaning,source", file=myList)flag += 1myDict = compile_name2.findall(str(s2))singleWord = str(myDict).replace("content=\"必应词典为您提供", "").replace("的释义,","")# print(singleWord)crab = compile_name2.findall(str(s2))# print("crab: " + str(crab) )# print( "s2: " + str(s2) )OMG = compile_name3.search(str(s2))# print(OMG.group())meaning = str(s2).replace( crab[0], "" ).replace(OMG.group(), "")# testDic[singleWord] = meaning# print(meaning)print( str(finishCNT) + "\t" + str(singleWord) + "\t" + str(meaning) + "\t", file = myList) #为了便于后续将.csv文件导入Oracle中,因此要在每行的末尾增加一个制表符“\t”myList.close()print("Finishing: " + str(finishCNT) )finishCNT += 1
运行过程如图5与图6所示,运行正则表达式匹配(Processing计数)时的电脑硬件资源消耗如图7所示,文件回写(Finishing计
数)时的电脑硬件消耗情况如图8所示。


得到的.csv文件的部分结果如图9与图10所示。
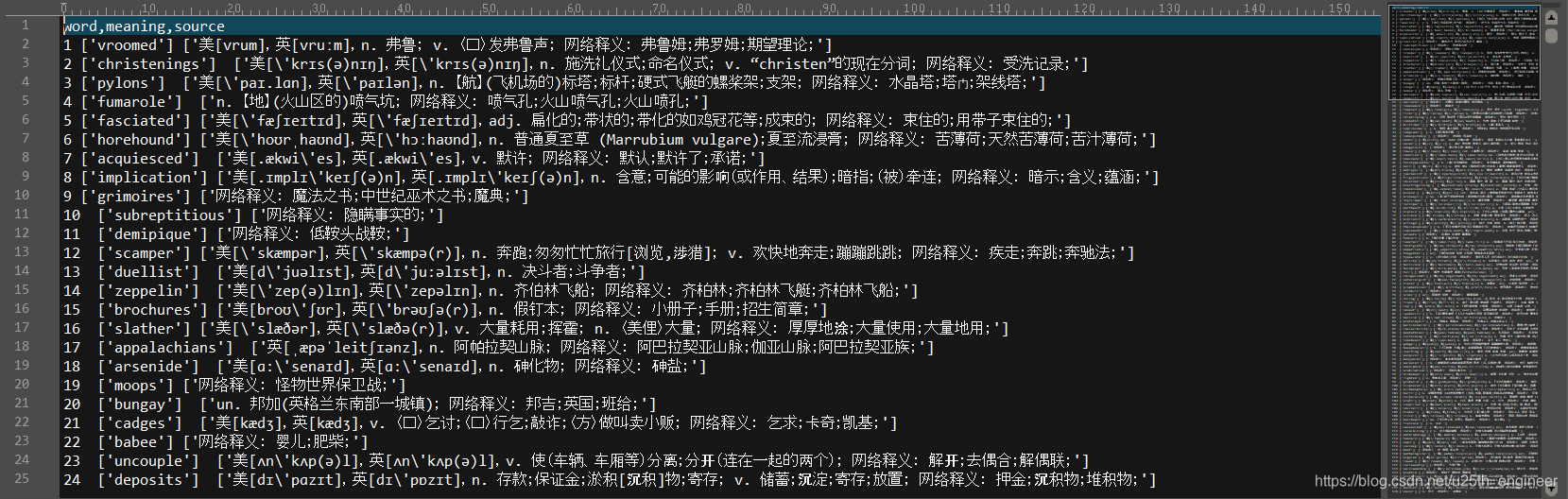
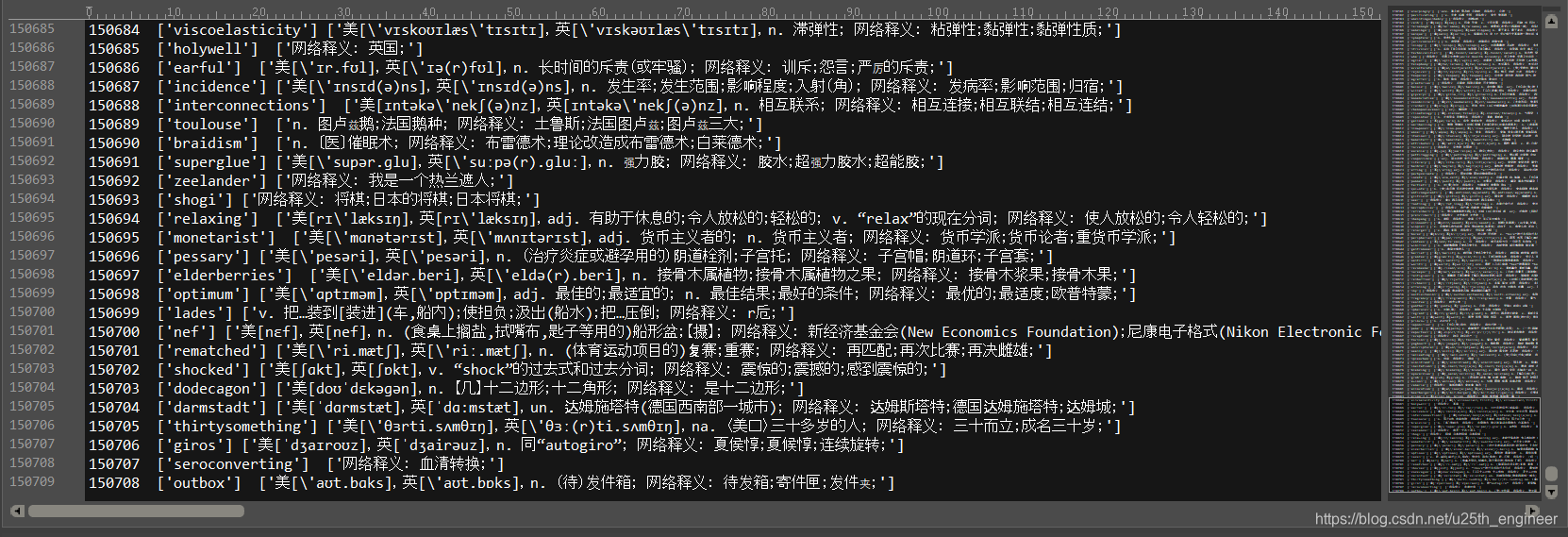
从图9和图10可以看出,由于在程序中直接将本应输出到控制台的信息写到文本中,因此内容含有多余的符号:“['”、"']"与
“\”,将这几个符号完全剔除后的结果如图11所示。

细心的朋友可能注音到了,生成的.csv文件中只有3个数据项,本应有2个制表符“\t”,但文本中每一行的末尾都还有1个制表
符“\t”,这主要是为了方便后续将.csv文件导入到|Oracle数据中。
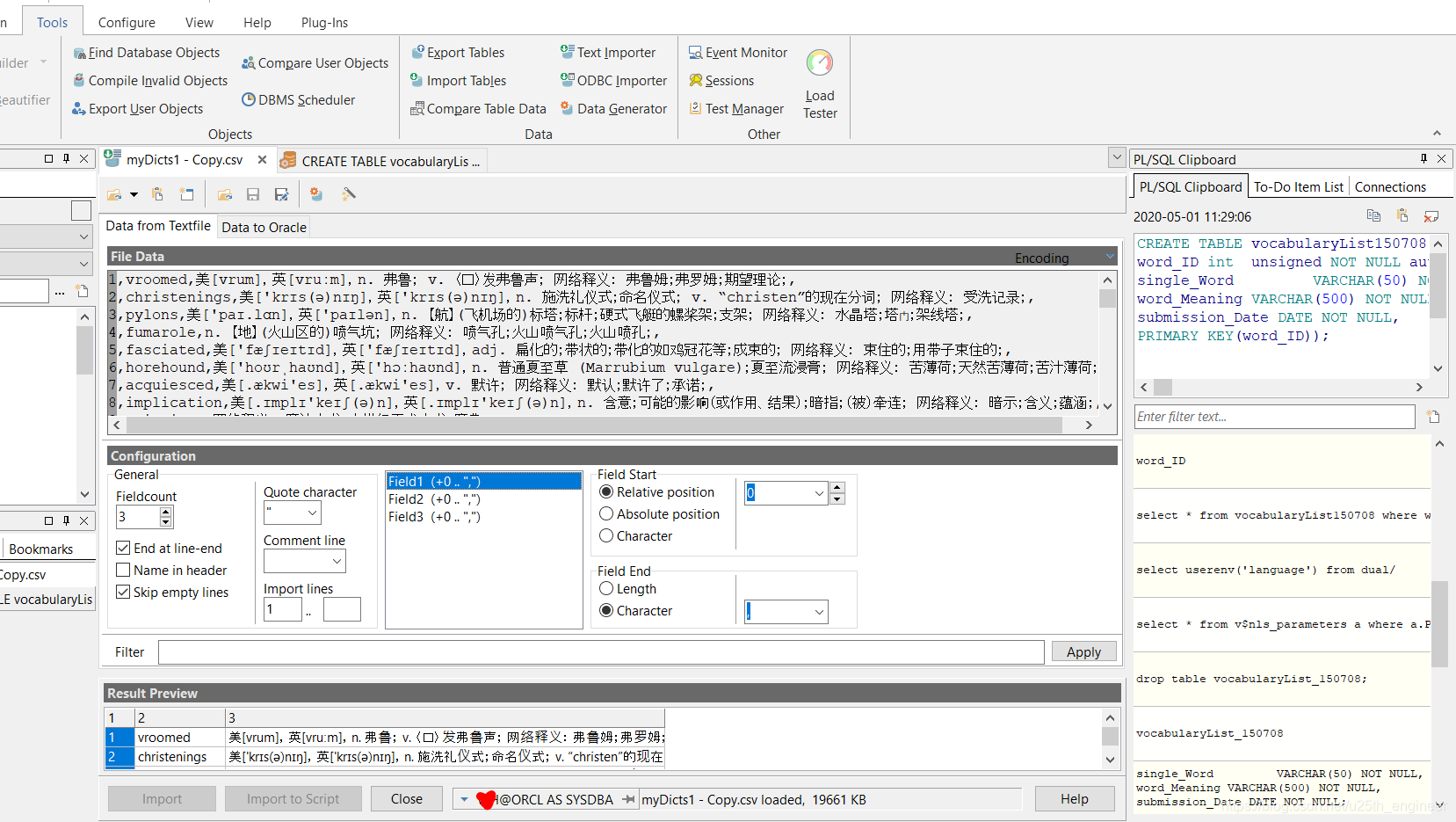
用以下命令在Oracle数据库中新建一张数据表,用于存储单词序号及其注音与释义。注意:我为了图省事,并未将单词的序号设
置为自增主键(Oracle中凡是owner是sys的表都不能设置触发器,而这是在Oracle中设置自增主键较为简单的办法之一)。
CREATE TABLE vocabularyList150708(
word_ID number NOT NULL PRIMARY KEY,
single_Word VARCHAR(100) NOT NULL,
word_Meaning VARCHAR(1000) NOT NULL
);
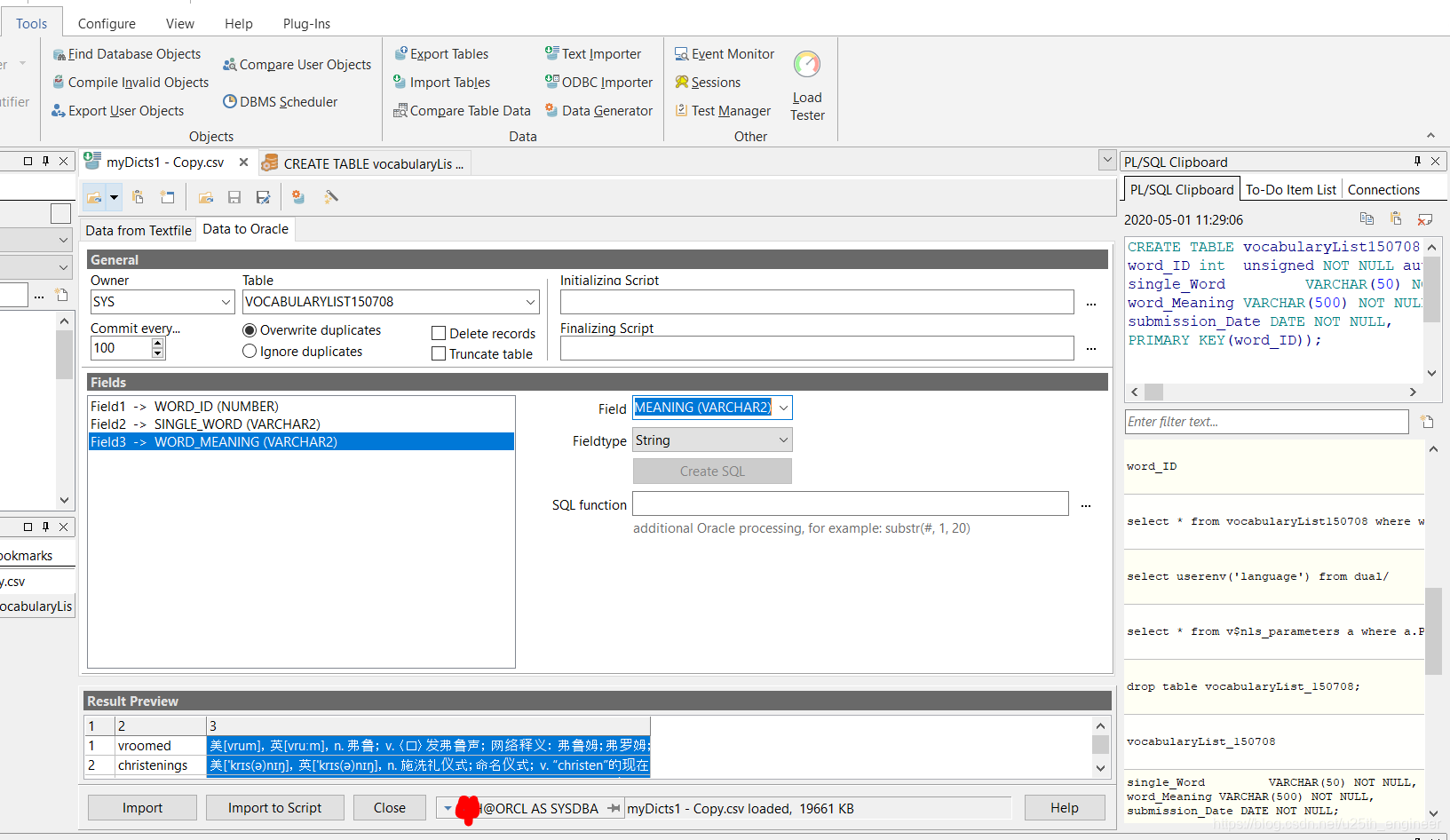
成功新建数据表后,使用PL/SQL的Text Importer工具将.csv文件导入到其中,过程非常简单,不详述。下面給出操作的截图,
如图12与图13所示。
经过一番折腾,终于搞出含有150708个英语单词及其释义与注音(少部分单词无注音)的.sql文件,如图14与图15所示。后面可
能会考虑继续完善,譬如添加例句等。
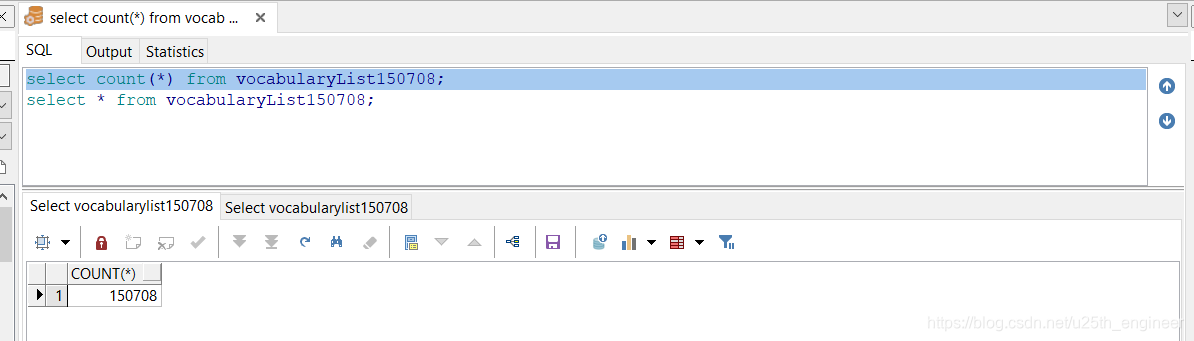
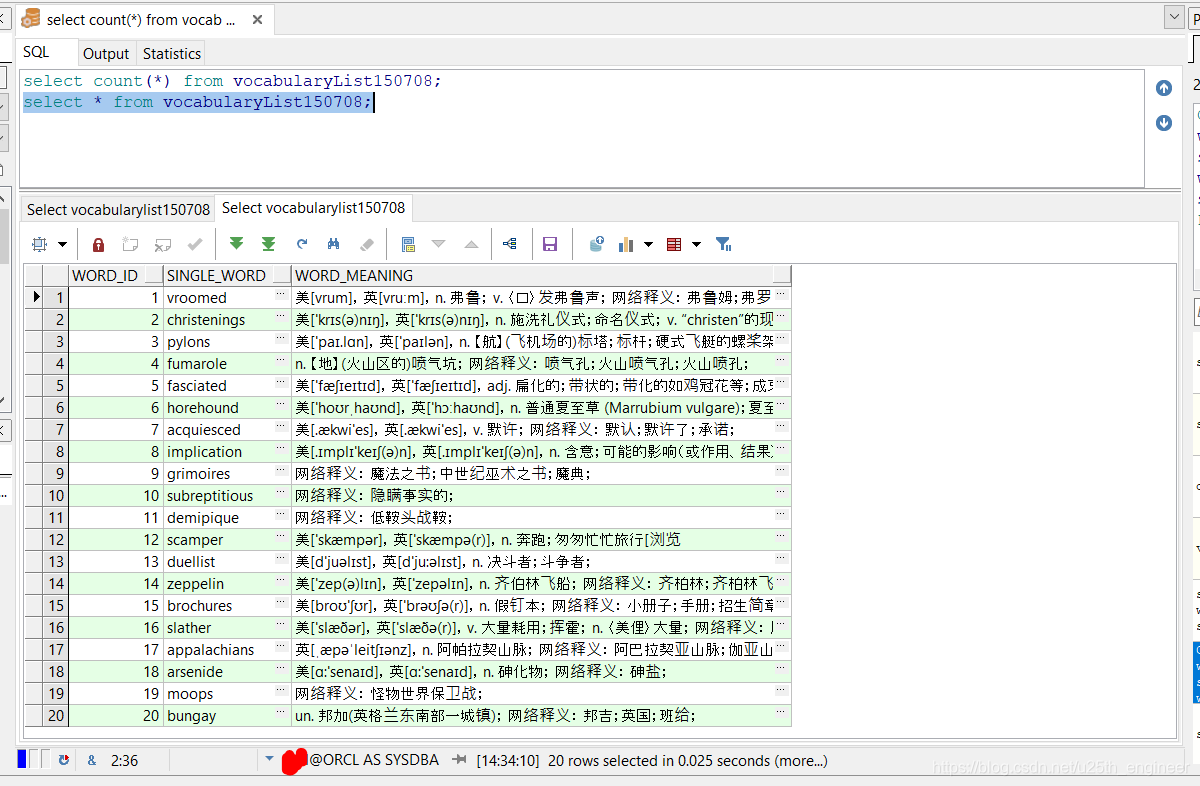
一番折腾,终于得到了.sql文件。
这篇关于初步处理爬取到的150708个单词的数据(原始网页文档格式,包含注音、释义与例句,等等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




