本文主要是介绍.norm() 范数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
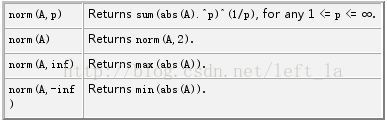
(A- B).norm().item()
是默认计算A与B的第二范数,如果你想计算差向量的第一范数(也称为L1范数),可以在norm()方法中传递p=1参数,这样就会计算出L1范数。例如:
(A- B).norm(p=1).item()
其中,使用.item()方法将结果转换为Python的标量(scalar)类型
这篇关于.norm() 范数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!