本文主要是介绍一种使用热成像和自动编码器和 3D-CNN 模型堆叠集成进行跌倒检测的新方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A Novel Approach for Fall Detection Using Thermal Imaging and a Stacking Ensemble of Autoencoder and 3D-CNN Models
- A Novel Approach for Fall Detection Using Thermal Imaging and a Stacking Ensemble of Autoencoder and 3D-CNN Models:一种使用热成像和自动编码器和 3D-CNN 模型堆叠集成进行跌倒检测的新方法
- 摘要
- 一.介绍
- 二.文献综述
- 三.方法
- A、结构
- B、网络合理性
- 四.实验分析
- A. Environment
- B.数据集
- C.评估指标
- D.定量分析
- E.定性分析
- 五.结论
A Novel Approach for Fall Detection Using Thermal Imaging and a Stacking Ensemble of Autoencoder and 3D-CNN Models:一种使用热成像和自动编码器和 3D-CNN 模型堆叠集成进行跌倒检测的新方法
作者信息:

摘要
跌倒是造成伤害和死亡的重要原因,尤其是在老年人口中。及早发现跌倒对于减轻其影响至关重要。热成像是一种很有前途的检测跌倒的技术,因为它是非侵入性的,可以在弱光条件下运行。然而,由于这些图像的分辨率低且缺乏颜色信息,准确检测热图像中的跌落仍然具有挑战性。本文提出了一种改进热图像数据跌倒检测的新方法,该方法使用自动编码器 (AE) 和 3D 卷积神经网络 (3D-CNN) 模型的堆叠集成,这些模型被输入到元神经网络中,该神经网络经过训练以检测跌倒和非跌倒。通过对公开的基准数据集“热模拟跌落”的消融研究证明了所提出系统的有效性,其中模型的准确率为83%。对比分析表明,所提出的解决方案比基于AE的基线高出9.2%。AE 和 3D-CNN 的结合使我们能够利用有监督和无监督学习方法的强大功能,同时减轻每个模型的局限性和偏差,为热图像输入流中准确高效的跌倒检测提供有前途的解决方案。
一.介绍
目前使用计算机视觉(CV)和深度学习(DL)的基于视觉的任务的开发主要利用AE模型或3D-CNN模型,但通常不结合两者。然而,两者的整合可以提供最好的无监督和监督学习范式。因此,这项工作提出了一种新的基于热成像的跌倒检测框架,使用无监督AE和监督3D-CNN的堆叠集成。AE和3D-CNN的中间输出被馈送到高级神经网络分类器(称为元模型)中,用于最终改进的分类。本文的主要贡献如下。
- 它提出了一种独特的基于热成像的跌倒检测方法,通过堆叠集成方法结合了自动编码器和3D-CNN模型的优点。
- 它采用多层感知器(MLP)分类器来揭示监督和无监督模型之间的复杂关系,为跌倒检测领域的新奇铺平道路。
- 它在一个公开的基准数据集上进行了详尽的实验,展示了所提出的解决方案的有效性,以及如何扩展该解决方案以实现尖端性能
二.文献综述
A、监督模型
B、无监督模型
C、混合模型
三.方法
图1展示了所提出的人类跌倒检测模型。它由三个子网络组成:
(i)一个有监督的 3D-CNN 模型,用于检测视频数据中先前跌倒的跌倒
(ii)无监督AE模型,用于检测ADL活动的异常
(iii)元模型-将3D-CNN和AE的输出作为输入的MLP,最终将输入帧分类为跌倒或非跌倒。这种集成结构使我们能够利用每个模型的优势,同时通过元模型减轻单个模型的潜在问题和偏见。要查看有关数据预处理步骤以及使用的数据生成器的特定信息,请访问:https://github.com/Christopher-Silver/CCECE-Fall-Detection
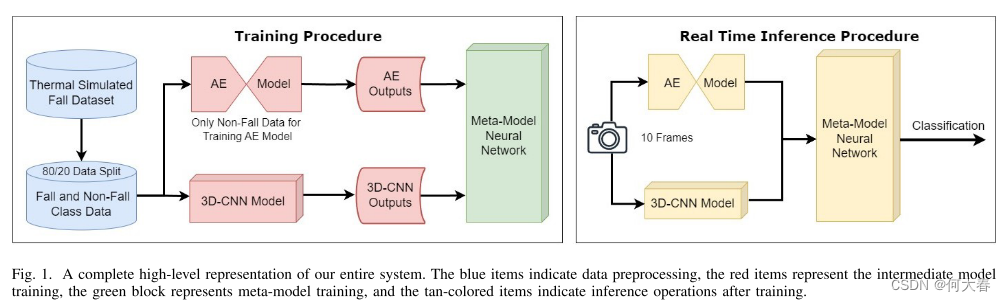
图1:对整个系统的一个完整的高级表示。蓝色项表示数据预处理,红色项表示中间模型训练,绿色块表示元模型训练,棕色项表示训练后的推理操作。
A、结构
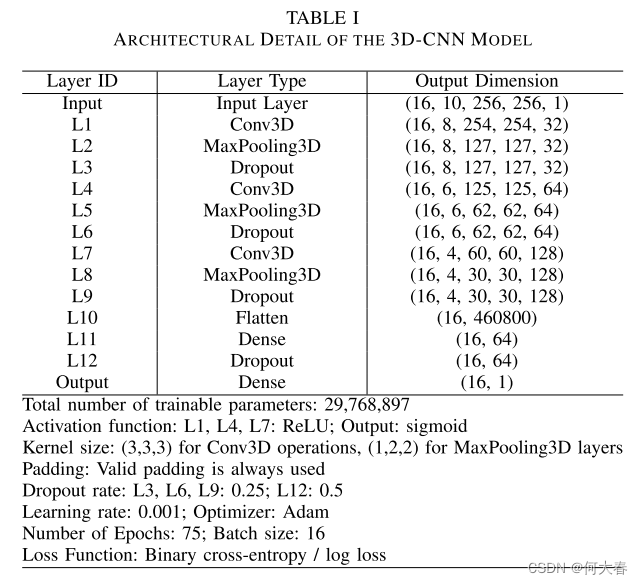
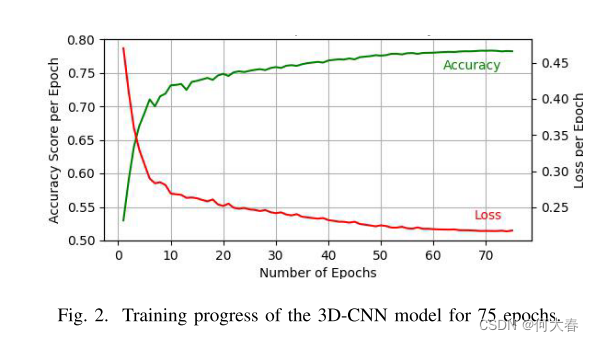
1)3D-CNN模型:表I提供了3D-CNN的逐层架构细节。它接收大小为256×256的10帧序列,并在表IV中总结的基准数据集中的跌倒和非跌倒视频样本上进行训练。为了克服类的不平衡,这项工作使用了基于滑动窗口的数据增强技术。当馈送一系列视频帧时,滑动窗口创建新的样本,每个样本相差一个时间单位。这意味着随后的帧系列将在时间维度上相差一个帧,从而成功地缓解了类不平衡问题。我们在非跌倒和跌倒之间使用50:50的比例,非跌倒被平均分为四个子类:一个空房间,一个坐着的人,一个走着的人和一个躺着的人。该子网络利用监督学习,能够看到跌倒和非跌倒样本,以便能够找到使每个类别可区分的模式。缺点是该系统可能相当复杂,需要许多数据样本才能准确。这种限制通过集成到所提出的解决方案中的非监督学习来解决。图2显示了3D-CNN模型的训练过程。该模型经过75个epoch的训练,达到模型最佳收敛到最佳精度和最低损失的程度。
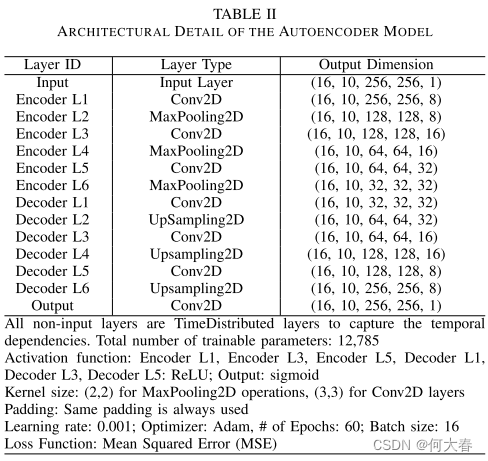
2)自动编码器模型:表II总结了在这项工作中开发的AE的结构。呈现给AE的数据与3D-CNN模型相同。AE基于使用卷积运算的空间参数共享的原理来实现,并且是对称的。编码器和解码器模块。该子网络利用无监督学习,其中AE仅在本研究中代表非跌倒视频的ADL样本上进行训练。因此,AE被视为异常检测器。AE学习重建它在训练过程中遇到的图像集,最大限度地减少这些图像上的重建误差。在推理过程中,跌倒和非跌倒视频都被呈现给模型。计算十个AE重建帧与输入帧之间的像素强度值的平均平方差以产生重建误差。如果一组帧的重建误差大于模型在对非跌倒事件进行训练期间通常经历的重建误差,则该序列被认为表示跌倒。在系统的当前实现中,模型的输出层采用Sigmoid激活函数。这是为了保持像素比较的输入-输出一致性,因为所有输入像素在预处理后都被限制在0和1之间。如果重建误差在训练中较大,则MSE损失函数允许系统相应地更新其参数。在模型的未来版本中,将针对该子网络测试线性输出激活函数。为了保持模型之间的数据集一致性,这里也使用了用于3D-CNN模型的相同滑动窗口技术。该模型的目的是在纯粹基于正常事件进行训练后检测输入视频中的异常。然而,如果该特定动作尚未在训练数据中表示,则该子网络可以将作为非跌倒事件的动作标记为跌倒。预计所提出的解决方案将通过整合监督3D-CNN和无监督AE生成的中间结果来共同学习输入到输出映射来克服这一点。
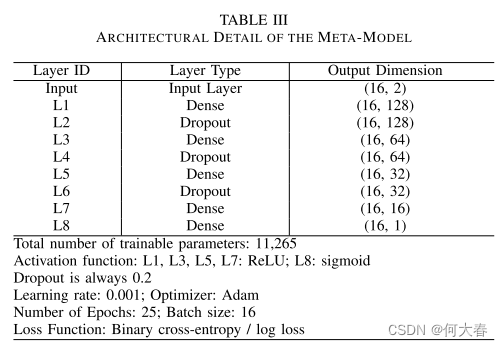
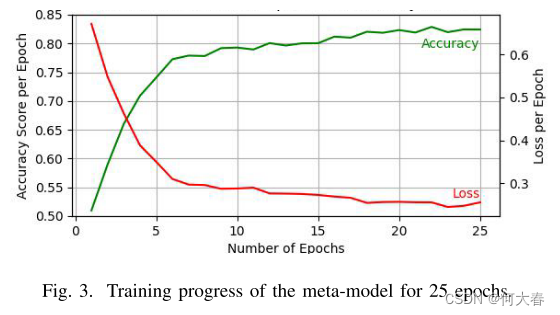
3)元模型:它是使用表III中描述的MLNN构建的最终分类器。它接收由前面提到的、先前训练的子网络产生的中间类概率分数,并生成识别输入视频中的跌倒和非跌倒事件的细化分类输出。单独训练模型可以避免来自元模型的任何可能影响3D-CNN和AE权重的潜在错误传播。图3显示了元模型训练过程中准确度、损失和历元数之间的关系。训练在25个时期内进行,因为超过这个时期,模型过拟合。
B、网络合理性
为了确定每个模型的最佳架构,对三个子网络中的每一个都采用了相同的方法,利用RandomSearchCV来削减潜在的超参数,即层数,它们的参数和激活函数等。为RandomSearchCV选择的初始值从当前最先进的解决方案中汲取灵感。在使用RandomSearchCV确定最有希望的超参数值之后,随后将GridSearch应用于压缩列表,从而确定最佳架构。
四.实验分析
A. Environment
所提出的模型是使用Python版本3.10.11及其开源原生库沿着DL库开发的,例如带有TensorFlow后端的Keras。模型开发、训练和测试是在一个系统上进行的,该系统配备了AMD Ryzen 7 5825U,Radeon Graphics 2.00 GHz处理器和16GB RAM(13.9GB可用),连接到Google Colab。训练GPU是NVIDIA Tesla K80,具有2496个CUDA核心和12GB VRAM。
B.数据集
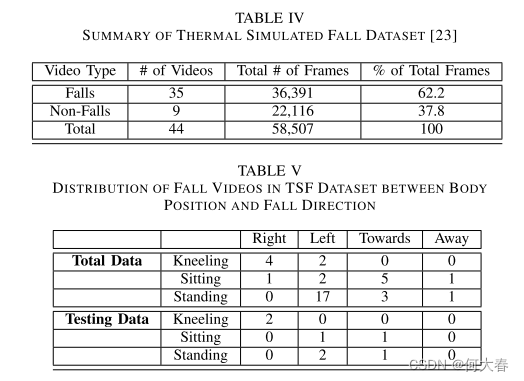
公开提供的“热模拟跌倒”[23]基准数据集(参见表IV)对提出的人体跌倒检测模型进行了验证。它包含构成热成像视频的连续.jpeg图像。每幅图像都是480x640像素的灰度格式。跌倒和非跌倒项目的框架分布分别为62.2%和37.8%。这表明样本中存在类别不平衡。应当注意,除了如前所述通过滑动窗口方法对数据进行上采样之外,不应用数据扩充。表V显示了基于每个视频中发现的动作的跌倒样本的分布。它们根据人在每次跌倒中的起始位置(垂直轴)以及它们相对于传感器的跌落位置(水平轴)进行分类。对于整个跌倒数据样本和测试数据都会显示此信息。
C.评估指标
这项工作利用公式(1)中定义的接受者工作特征曲线面积(ROC-AUC)度量来评估所提出模型的性能。
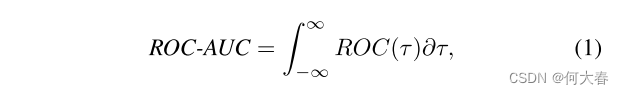
其中ROC(τ)表示给定阈值τ处的ROC曲线,dτ表示积分中的微分元素。ROC绘制方程(2)中的真阳性率(TPR)与方程(3)中的假阳性率(FPR)。
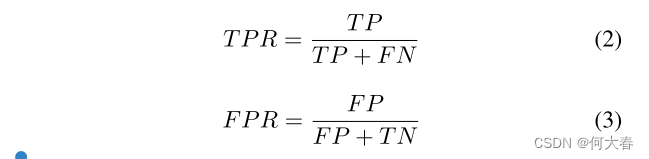
在(2)和(3)中,TP和FP分别代表被正确和错误分类为阳性(跌倒)的样本。因此,TN和FN分别代表被正确和错误分类为阴性(非跌倒)的样本。
D.定量分析
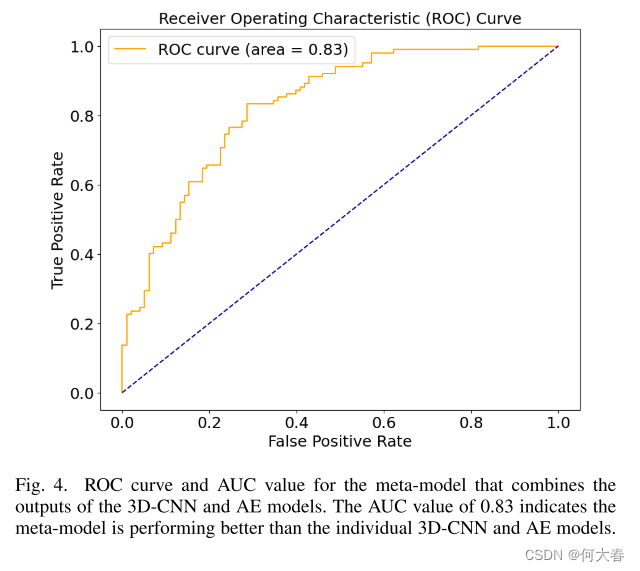
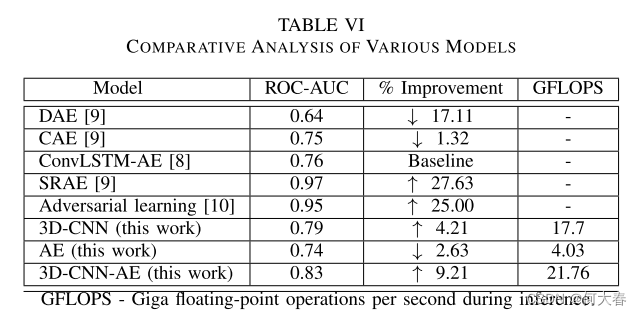
表VI将所提出的解决方案的性能与[8]中介绍的最近的跌倒检测基线模型进行了比较,该模型被认为是将重点从监督学习切换到人类跌倒检测的无监督方法的定义性工作。实验研究表明,所提出的方法具有良好的性能,AUC ROC得分为0.83。当与3D-CNN和AE相比时,集成模型分别超过了单个模型的4%和9%。AE模型本身记录的性能略差于基线,但它与现有的自动编码器解决方案相比具有竞争力,仅比[9]中的CAE模型差1%,比[8]中的ConvLSTM-AE模型差2%。3DCNN模型的性能比基线高出4.21%,并且在文献中没有与该数据集进行任何直接比较。集成模型超过基线9.21%,表现优于个体AE模型和3D-CNN模型。这证实了我们的预测,性能可以通过将不同模型的堆叠集成馈送到元模型分类器中来提高。图4中的ROC-AUC曲线表明,该模型可以获得高TPR,尽管代价是FPR升高。虽然所提出的解决方案显示出有竞争力的性能,但仍有改进的余地。子网络,可以通过利用迁移学习,将3D-CNN和AE替换为高度复杂的最新架构,而不是使用我们从零开始训练的简单网络。
E.定性分析
为了直观地检查所提出的模型的性能,我们使用从图5中可视化的测试集中随机选择的两组10个连续的不同图像。在这些测试用例中,模型正确地对样本进行了分类。这加强了我们的框架的隐私保护人体跌倒检测的适当性。在手动检查时,最常见的错误分类视频是包含有人从膝盖向右摔倒的摔倒样本,以及有人从坐着向左摔倒的样本。重新审视表V中给出的样本分布,数据明显偏向开始从站立位置向左的跌倒。测试数据和总体数据之间的比率对于人跪着并向右跌倒的情况以及当他们坐着并向左跌倒的情况是相当高的。这解释了常见的错误分类,因为训练集中可能没有足够的数据来充分表示这些类型的跌倒。站立导致的跌倒几乎总是被正确分类,遵循类似的逻辑,因为60%的跌倒视频包括站立导致的跌倒。该分析表明,错误分类主要是由数据分布引起的,而不是由3D-CNN,AE和元模型中的缺陷引起的。这个问题可以通过数据扩充和添加预处理步骤来解决,以便在每次迭代中随机化训练和测试样本。

五.结论
尽管现有的解决方案已经实现了RGB输入中高达99%的人体跌倒检测准确度和热成像中高达97%的人体跌倒检测准确度,但这些结果对于实时的潜在救生设备来说是不够的,因此持续改进跌倒检测算法至关重要。因此,这项工作提出了一种使用3D-CNN模型和AE的堆叠集合进行跌倒检测的新方法,以改善与单个模型相比的结果。消融研究展示了这些堆叠集成模型如何提高跌倒检测的准确性,同时保护有跌倒风险的人的隐私。未来的工作将致力于降低计算复杂度,同时提高精度,例如,通过使用背景减除技术和非局部多光纤网络。采用数据扩充的方法解决测试数据不平衡的问题,采用迁移学习的方法改进中间子网络。
个人总结:将有监督学习和无监督学习结合。
这篇关于一种使用热成像和自动编码器和 3D-CNN 模型堆叠集成进行跌倒检测的新方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




