本文主要是介绍使用wandb/tensorboard管理、可视化卷积神经网络训练日志,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- wandb
- 训练参数配置
- 数据记录
- 硬件情况记录
- 数值记录
- 参数分布记录
- 特征图记录
- 误删训练的记录如何恢复
- tensorboard
- 数据记录
- 硬件数据
- 数值记录
- torchsummary
wandb
##安装注册
安装wandb库,输入wandb login命令获取API key(40位),或直接输入命令wandb login your_API_key登录个人wandb账号
pip install wandb
wandb login
训练参数配置
在wandb.init函数中指定项目名、团队名(可省略,注意项目对团队的权限)和训练参数,这些训练参数在wandb记录的日志中可以查看,方便直观地分析不同训练中参数的调整及其影响,也可以编辑每一个训练日志的Name和Notes对其进行标记。
wandb.init(project="pytorch-intro", # project_nameentity="neverbackdown", # team_nameconfig={ # training_config"learning_rate": 0.01,"batch_size": 16,"val_batch_size": 16,"freeze_epochs": 50,"epochs": 200,"depth": 50,"lr": 1e-5,"momentum": 0.1,"no_cuda": False,"seed": 42,"log_interval": 10,})
wandb.watch_called = False
config = wandb.config # Initialize config
数据记录
硬件情况记录
wandb自动记录硬件数据,如GPU使用率、磁盘访问等,可用于分析性能瓶颈。
数值记录
每一代训练结束后记录train_loss,验证结束后记录precision、recall、valid_loss等参数,并保存wandb日志文件和权重文件。
wandb.log({"epoch": epoch+1})# after trainingwandb.log({"training loss": np.mean(loss_hist)})# after validation
wandb.log({'val loss': float(classification_loss + regression_loss),'mAP': float(mAP),'precision': float(precision),'recall': float(recall)})# save weights.pt
torch.save(retinanet.module.state_dict(), f'logs/weights/{dataset_name}_retinanet_rotate_{epoch_num}.pt') # only paras
torch.save(net.module, f'logs/weights/{dataset_name}_pre-retinanet_rotate_jitter_labelsmooth_{epoch_num}.pt') # whole modulewandb.save(f'model_{epoch_num}.h5')
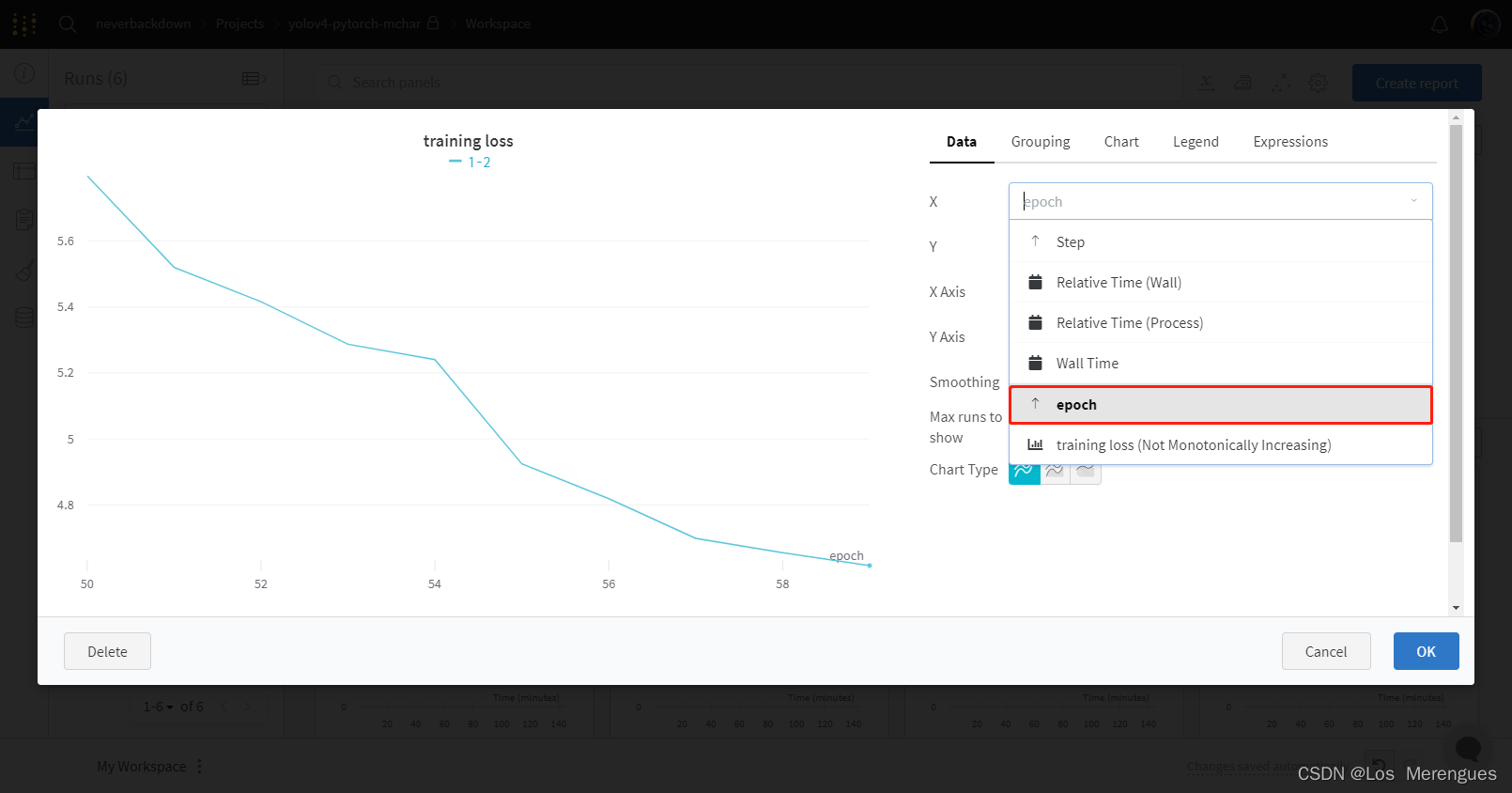
中断训练的损失函数查看方式
当训练中断或需要从指定epoch开始重新训练时,wandb默认的损失函数图横坐标为step,即从0开始绘制,无法直观看出损失函数的连续变化。解决办法是保存epoch值(代码第一行),并edit panel将横坐标改为epoch,即可按epoch查看损失函数。
参数分布记录
wandb.watch(model, log="all") # 观察所有参数
特征图记录
采用register_forward_pre_hook(hook: Callable[..., None])函数实现,括号中的参数是一个函数名,暂且称之为hook_func,函数内容需要自行实现。其参数module, input, output固定,分别代表模块名称、一个tensor组成的tuple输入和tensor输出。关于该函数详细解释可参考博文。
由于hook_func参数固定,故定义get_image_name_for_hook函数为不同特征图命名,并定义全局变量COUNT表示特征图在网络结构中的顺序。具体实现如下。
COUNT = 0 # global_para for featuremap naming
IMAGE_FOLDER = './save_image'
INSTANCE_FOLDER = Nonedef hook_func(module, input, output):image_name = get_image_name_for_hook(module)data = output.clone().detach().permute(1, 0, 2, 3)# torchvision.utils.save_image(data, image_name, pad_value=0.5)from PIL import Imagefrom torchvision.utils import make_gridgrid = make_grid(data, nrow=8, padding=2, pad_value=0.5, normalize=False, range=None, scale_each=False)ndarr = grid.mul_(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()im = Image.fromarray(ndarr)# wandb save from jpg/png filewandb.log({f"{image_name}": wandb.Image(im)})# save locally# im.save(image_path)def get_image_name_for_hook(module):os.makedirs(INSTANCE_FOLDER, exist_ok=True)base_name = str(module).split('(')[0]image_name = '.' # '.' is surely exist, to make first loop condition Trueglobal COUNTwhile os.path.exists(image_name):COUNT += 1image_name = '%d_%s' % (COUNT, base_name)return image_nameif __name__ == '__main__':# clear output folderif os.path.exists(IMAGE_FOLDER):shutil.rmtree(IMAGE_FOLDER)# TODO: wandb & model initializationmodel.eval()# layers to logmodules_for_plot = (torch.nn.LeakyReLU, torch.nn.BatchNorm2d, torch.nn.Conv2d)for name, module in model.named_modules():if isinstance(module, modules_for_plot):module.register_forward_hook(hook_func)index = 1for idx, batch in enumerate(val_loader):# global COUNTCOUNT = 1INSTANCE_FOLDER = os.path.join(IMAGE_FOLDER, f'{index}_pic')# forwardimages_val = Variable(torch.from_numpy(batch[0]).type(torch.FloatTensor)).cuda()outputs = model(images_val)
误删训练的记录如何恢复
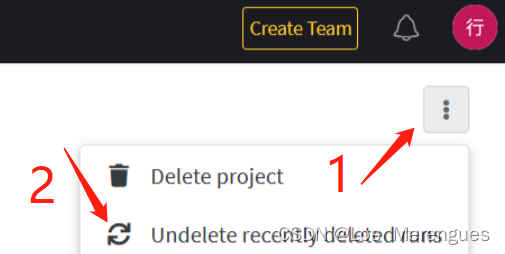
误删记录后,再用本地记录上传的方式行不通,会显示“run XXX was previously created and deleted; try a new run name (<Response [409]>)”。
只需要进入该项目的 Overview 界面,点开右上角的按钮会显示“Undelete recently deleteed runs”,单击即可恢复该项目所有的runs。
tensorboard
数据记录
硬件数据
命令行输入nvidia-smi查看GPU使用情况,或在 任务管理器(Ctrl+Alt+Delete)-性能 中查看。
数值记录
每一代训练结束后记录train_loss,验证结束后记录precision、recall、valid_loss等参数,并保存权重文件。
def train(model, yolo_loss, epoch, writer):# after trainwriter.add_scalars('Train/loss', {'total loss': float(loss),'classification loss': float(classification_loss),'regression loss': float(regression_loss)}, epoch_num)# after validwriter.add_scalars('Validation/loss', {'classification_loss': float(classification_loss),'regression_loss': float(regression_loss),'total_loss': float(classification_loss + regression_loss)}, epoch_num)writer.add_scalar('Validation/mAP', float(mAP), epoch_num)writer.add_scalars('Validation/PR_curve', {'precision': float(precision),'recall': float(recall)}, epoch_num)# save weights.pttorch.save(retinanet.module.state_dict(), f'logs/weights/{dataset_name}_retinanet_rotate_{epoch_num}.pt') # only parastorch.save(net.module, f'logs/weights/{dataset_name}_pre-retinanet_rotate_jitter_labelsmooth_{epoch_num}.pt') # whole moduleif __name__ == "__main__":log_writer = SummaryWriter('logs/tensorboard/FPN/')train(model, yolo_loss, epoch, log_writer)
在SummaryWriter记录的文件夹父目录下用命令行打开tensorboard查看训练日志。
tensorboard --logdir "log_filepath"
torchsummary
可以在网络定义文件的main函数里查看网络结构,包括每一层的输出尺寸、参数量和网络总参数量等。
from torchsummary import summaryif __name__ == "__main__":device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = YoloBody(9, 3).cuda()summary(model, input_size=(3, 416, 416))
这篇关于使用wandb/tensorboard管理、可视化卷积神经网络训练日志的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





