本文主要是介绍谷歌连发 Gemini1.5、Gemma两种大模型,Groq让模型输出速度快18倍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本周,我们观察到以下AI领域的新动向和新趋势:
1.谷歌连发Gemini1.5和Gemma两种大模型, 其中Gemini1.5采用MoE架构,并拥有100万token上下文长度,相比Gemini 1.0性能大幅提升。Gemma是谷歌新推出的开源模型,采用Gemini同源技术,性能比同参数尺寸的Llama 2更强。
2.Groq的LPU让其模型输出速度比GPT-4快18倍, 用LPU集群推理的速度超快,但在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
3.Stable Diffusion 3发布,文字渲染和多主题生成能力提升。 它采用了与Sora同样的Diffusion Transformer架构,能够正确的生成文字效果,大大减少拼写错误和“胡编滥造”。
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了NLP&大模型面试与技术交流群, 想要进交流群、获取完整源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
- 用通俗易懂的方式讲解:大模型微调方法总结
- 用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
- 用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
- 用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了
人工智能产品和技术的新突破
1.谷歌Gemini1.5上线:MoE架构,100万上下文
谷歌最新推出的Gemini 1.5基于先进的专家混合(MoE)架构,旨在提高训练和服务效率。其首个版本Gemini 1.5 Pro是一款中型多模态模型,针对多任务扩展进行了优化,性能与Gemini 1.0 Ultra相似,该模型能够无缝分析、分类和总结大量内容,提供跨模态的复杂理解和推理能力。

Gemini 1.5 Pro的上下文窗口容量大幅增加,现在可以处理多达100万个token,意味着模型能够一次性处理大量信息,如1小时视频、11小时音频、超过30,000行代码或超过700,000单词的文本。
Gemini 1.5 Pro在文本、代码、图像、音频和视频的大语言模型的基准测试中,87%的性能优于Gemini 1.0 Pro,与Gemini 1.0 Ultra的表现大致相似。谷歌正在不断开发新的评估和基准来测试Gemini 1.5 Pro的新颖功能,并计划将其推广给全球数十亿用户、开发者和企业客户。
2.谷歌发布开源大模型Gemma,笔记本可跑,可商用
谷歌推出全新开源模型系列"Gemma",Gemma系列包括Gemma 2B和Gemma 7B两种尺寸的模型,每种尺寸都提供了预训练和指令微调版本,用户可以通过Kaggle、谷歌的Colab Notebook或Google Cloud访问这些模型。这一系列模型不仅免费可用,还允许商用,权重也一并开源。
Gemma模型在关键基准测试中已经明显超越了更大的模型,如Llama-2 7B和13B,以及Mistral 7B,而且能够直接在开发人员的笔记本电脑或台式电脑上运行。

Gemma模型在18个基于文本的任务中的11个优于相似参数规模的开源模型,尤其在数学和编码基准测试中表现突出。Gemma 7B模型在GSM8K和MATH基准上的表现超过其他模型至少10分,在HumanEval上的表现比其他开源模型至少高出6分。
Gemma模型的架构基于Transformer,采用了多查询注意力、RoPE嵌入、GeGLU激活等改进技术,训练基础设施使用了自研AI芯片TPUv5e。
Gemma模型的预训练在来自网络文档、数学和代码的2T和6T主要英语数据上进行,通过监督微调和RLHF对模型进行微调和对齐,以提高下游自动评估和模型输出的人类偏好评估性能。Gemma模型的发布,标志着谷歌在开源大模型领域的重要一步。
3.Stable Diffusion 3发布,采用Sora同源技术,文字终于不乱码了
Stability AI最近发布了其最新的文生图模型—Stable Diffusion 3,这一版本采用了与OpenAI的Sora同源的Diffusion Transformer架构。

相比上一代,Stable Diffusion 3进化了三大能力,首先是文字能力,它能够正确的生成文字效果,大大减少拼写错误和“胡编滥造”;其次,是多主题提示能力,多个主题和元素搭配在一起,也不会混乱;最后是图像质量,分辨率和逼真程度再上一个台阶。
Stable Diffusion 3背后的关键技术包括Diffusion Transformer和Flow Matching。Diffusion Transformer框架允许模型在像素空间进行高分辨率训练,而Flow Matching技术则提升了采样效率。
目前,Stable Diffusion 3还没有全面开放,权重也未公布。团队表示,他们正在采取一些安全措施以防止不法分子滥用。对于想要尝鲜的用户,可以通过提交申请来获取早期访问权限。Stability AI首席执行官Emad Mostaque表示,待收到反馈并进行改进后,他们计划将该模型开源。
4.Transformer作者创立独角兽推出超强多模态LLM,性能超Gemini Pro
由Transformer论文作者创立的Adept AI近日推出新的多模态大模型Fuyu-Heavy,它的性能在多模态领域甚至超过了Gemini Pro,并且尺寸不到前者的10%。
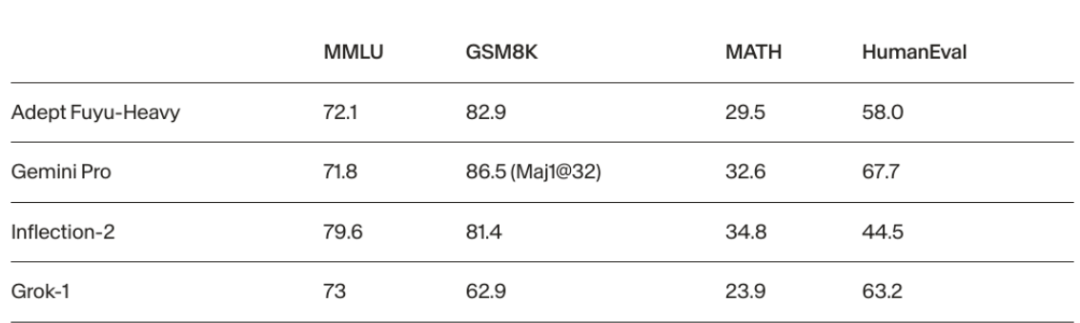
Adept AI的目标是开发能够提高工作效率的AI智能体,Fuyu-Heavy将作为其未来产品的基础模型。通过特定的测试题目,Fuyu-Heavy能够进行复杂的计算和逻辑推理,显示出其在多模态任务中的强大数理能力。Fuyu-Heavy的性能在多模态性能评估中超过了Gemini Pro,并在长对话能力的评估中超过了Claude 2。
Fuyu-Heavy的开发过程面临了多种挑战,包括处理原生多模态大模型在文本和图像数据上的各种问题,以及图像数据对模型带来的压力。Adept团队投入了大量精力收集、整理甚至创建高质量的图像预训练数据,并对Fuyu的架构和训练过程进行了大幅调整以应对图像模型的不稳定性。
5.比GPT-4快18倍,世界最快大模型Groq登场!每秒500 token破纪录,自研LPU速度是英伟达GPU 10倍
Groq模型以每秒输出近500个token(ChatGPT-3.5的速度是每秒40个token)的速度刷新了大语言模型的生成速度纪录,成为“世界上速度最快的LLM”。在一项简单代码调试问题的测试中,Groq的输出速度比Gemini快10倍,比GPT-4快18倍,尽管在答案质量上Gemini表现更佳。
Groq模型的高速性能得益于其背后的自研语言处理单元(LPU),而非传统的GPU。Groq公司开发的这种LPU,名为张量流处理器(TSP),采用时序指令集计算机架构,避免了频繁的数据加载需求,从而降低了成本并提高了效率。
不同于NVIDIA GPU需要依赖高速数据传输,Groq的LPU在其系统中没有采用高带宽存储器(HBM)。它使用的是SRAM,其速度比GPU所用的存储器快约20倍。
Groq模型的推理引擎在基准测试中表现出色,其LPU推理性能比顶级云提供商快。但是AI专家贾扬清算了一笔账,因为Groq的内存容量只有230MB,在运行Llama-2 70b模型时,需要305张Groq卡才足够,而用H100则只需要8张卡。从目前的价格来看,这意味着在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
6.NVIDIA推出新工具,允许在PC上运行AI模型
NVIDIA发布了一款新工具“Chat with RTX”,使得GeForce RTX 30系列和40系列显卡的拥有者能够在Windows PC上离线运行一个AI驱动的聊天机器人。
这个工具允许用户自定义一个AI模型,并将其连接到可以查询的文档、文件和笔记。“Chat with RTX”默认使用Mistral的开源模型,但也支持其他基于文本的模型,包括Meta的Llama 2。NVIDIA提醒,下载所有必要的文件将占用相当大的存储空间—根据所选模型,需要50GB到100GB不等。
目前,“Chat with RTX”能将应用指向包含任何支持文件的文件夹将把这些文件加载到模型的微调数据集中。此外,“Chat with RTX”还可以获取YouTube播放列表的URL,加载播放列表中视频的转录,使所选模型能够查询其内容。
然而,需要注意的是,“Chat with RTX”不能记住上下文,应用的回应相关性可能受到多种因素的影响。因此,“Chat with RTX”目前更像是一个玩具,而不是用于生产的工具。尽管如此,使运行AI模型本地化的应用程序还是值得称赞的,这是一个日益增长的趋势。世界经济论坛预测,能够离线运行GenAI模型的设备将会“戏剧性”增长,包括PC、智能手机、物联网设备和网络设备。
7.普林斯顿DeepMind用数学证明:LLM不是随机鹦鹉!「规模越大能力越强」有理论根据
普林斯顿大学和DeepMind的科学家Sanjeev Arora和Anirudh Goyal通过数学方法证明了大语言模型并非仅是随机组合训练数据的“随机鹦鹉”,而是随着模型规模的增大,其能力确实会得到提升。
他们的研究基于随机图理论,特别是二分图的概念,来模拟大语言模型的工作原理。在这种模型中,一类节点代表文本片段,另一类节点代表理解这些文本所需的技能。通过分析这些节点之间的连接,研究人员发现,随着大语言模型规模的增加,模型能够更好地组合多种技能来生成文本,即使这些技能组合在训练数据中未曾出现。
这一发现揭示了大语言模型的“涌现能力”,即在没有直接训练的情况下发展出新的能力。研究人员进一步利用神经缩放定律,这是一种描述模型规模、训练数据量与测试损失之间关系的方程,来支持他们的理论。他们的实验结果表明,更大的大语言模型在技能混合测试中表现更好,能够展示出更高的泛化能力。这项研究不仅为大语言模型的工作机制提供了数学上的解释,也为未来大语言模型的设计和应用提供了理论指导。
这篇关于谷歌连发 Gemini1.5、Gemma两种大模型,Groq让模型输出速度快18倍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






