本文主要是介绍Elasticsearch搜索引擎第六篇-分词器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 认识分词器
- 测试分词器
- Character Filter 字符过滤器
- Tokenizer 分词器
- Token Filter 词项过滤器
- 同义词过滤器
- Analyzer 分析器
- 为索引指定分析器
- 为索引指定默认分词器
- 为字段指定分析器
- Analyzer使用顺序
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html
认识分词器
在ES中一个Analyzer 由下面三种组件组合而成:
- character filter:字符过滤器,对文本进行字符过滤处理,如处理文本中的html标签字符。处理完后再交给tokenizer进行分词。一个analyzer中可包含0个或多个字符过滤器,多个按配置顺序依次进行处理。
- tokenizer:分词器,对文本进行分词。一个analyzer必需且只可包含一个tokenizer。
- token filter:词项过滤器,对tokenizer分出的词进行过滤处理。如转小写、停用词处理、同义词处理。一个analyzer可包含0个或多个词项过滤器,按配置顺序进行过滤。
测试分词器
- 示例一
返回结果如下:POST _analyze {"analyzer": "whitespace","text": "The quick brown fox." }{"tokens": [{"token": "The","start_offset": 0,"end_offset": 3,"type": "word","position": 0},{"token": "quick","start_offset": 4,"end_offset": 9,"type": "word","position": 1},{"token": "brown","start_offset": 10,"end_offset": 15,"type": "word","position": 2},{"token": "fox.","start_offset": 16,"end_offset": 20,"type": "word","position": 3}] } - 示例二
返回结果:POST _analyze {"tokenizer": "standard","filter": [ "lowercase", "asciifolding" ],"text": "Is this deja vu?" }{"tokens": [{"token": "is","start_offset": 0,"end_offset": 2,"type": "<ALPHANUM>","position": 0},{"token": "this","start_offset": 3,"end_offset": 7,"type": "<ALPHANUM>","position": 1},{"token": "deja","start_offset": 8,"end_offset": 12,"type": "<ALPHANUM>","position": 2},{"token": "vu","start_offset": 13,"end_offset": 15,"type": "<ALPHANUM>","position": 3}] }
Character Filter 字符过滤器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
当一段内容提交时,字符过滤器会按照规则过滤一些特殊字符,ES提供了几种常用的字符过滤器,如下:
-
HTML Strip Character Filter
用来过滤html标签
测试:
POST _analyze {"tokenizer": "keyword", "char_filter": [ "html_strip" ],"text": "<p>I'm so <b>happy</b>!</p>" }返回结果:
I'm so happy!在索引中配置如下:
PUT my_index {"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "html_strip","escaped_tags": ["b"]}}}} }- char_filter中定义自己的字符过滤器
- escaped_tags用来指定例外的标签。如果没有例外标签需配置,则不需要在此进行定义
- analyzer中定义自己的分析器,分析器有一系列的分词器或过滤器构成,在这里引用了my_char_filter过滤器
-
Mapping Character Filter
用指定的字符串替换文本中的某字符串
-
Pattern Replace Character Filter
进行正则表达式替换
Tokenizer 分词器
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
ES内部提供了很多分词器,基本可以满足日常使用。

但是ES中没有提供中文分词器,集成中文分词器请跳转:Elasticsearch搜索引擎第三篇-ES集成IKAnalyzer中文分词器
集成的中文分词器IKAnalyzer中提供的tokenizer名称为:ik_smart、ik_max_word
测试tokenizer:
POST _analyze
{"tokenizer": "standard", "text": "张三说的确实在理"
}POST _analyze
{"tokenizer": "ik_smart", "text": "张三说的确实在理"
}
Token Filter 词项过滤器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
ES内部提供了很多Token分词过滤器,主要用于分词或查询过后,如何进行后续的处理和过滤,如转小写过滤器、停用词过滤器、同义词过滤器等等。
IKAnalyzer中文分词器中自带有停用词过滤功能。
同义词过滤器
这里举个例子说明同义词过滤器如何工作的。
定义一个带有同义词过滤器功能的索引:
PUT /test_index
{"settings": {"index" : {"analysis" : {"analyzer" : {"my_ik_synonym" : {"tokenizer" : "ik_smart","filter" : ["synonym"]}},"filter" : {"synonym" : {"type" : "synonym","synonyms_path" : "analysis/synonym.txt"}}}}}
}
在analysis/synonym.txt文件中定义同义词:
张三,李四
电饭煲,电饭锅 => 电饭煲
电脑 => 计算机,computer
- 文件一定要UTF-8编码
- 一行一类同义词,=>表示标准化为后面的词
紧接着测试如下:
POST test_index/_analyze
{"analyzer": "my_ik_synonym","text": "张三说的确实在理"
}POST test_index/_analyze
{"analyzer": "my_ik_synonym","text": "我想买个电饭锅和一个电脑"
}
Analyzer 分析器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
Analyzer是字符过滤器、分词器、词项过滤器的集合,ES内建的和集成的analyzer都可以直接使用,如果不能满足我们的需求,则我们可以自己组合字符过滤器、分词器、词项过滤器来定义自定义的analyzer。
ES内部提供的analyzer:
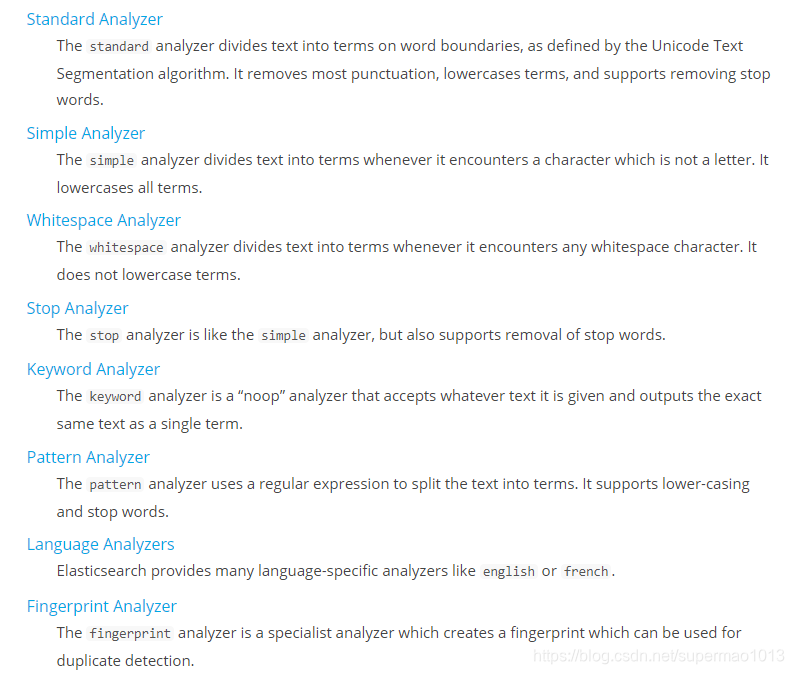
自定义analyzer需要遵守以下规则:
- 字符过滤器:0或多个
- 分词器:必须有且只有一个
- 词项过滤器:0或多个
为索引指定分析器
PUT my_index8
{"settings": {"analysis": {"analyzer": {"my_ik_analyzer": {"type": "custom","tokenizer": "ik_smart","char_filter": ["html_strip"],"filter": ["synonym"]}},"filter": {"synonym": {"type": "synonym","synonyms_path": "analysis/synonym.txt"}} } }
}
- tokenizer:指定分词器
- char_filter:指定字符过滤器
- filter:指定词项过滤器
为索引指定默认分词器
PUT /my_index10
{"settings": {"analysis": {"analyzer": {"default": {"tokenizer": "ik_smart","filter": ["synonym"]}},"filter": {"synonym": {"type": "synonym","synonyms_path": "analysis/synonym.txt"}}}},"mappings": {"_doc": {"properties": {"title": {"type": "text"}}}}
}
测试一下:
PUT my_index10/_doc/1
{"title": "张三说的确实在理"
}GET /my_index10/_search
{"query": {"term": {"title": "张三"}}
}
为字段指定分析器
很多时候,希望指定字段使用不同的分析器,而不是这个索引,因此可以按照如下定义:
PUT my_index8/_mapping/_doc
{"properties": {"title": {"type": "text","analyzer": "my_ik_analyzer"}}
}
如果指定该字段在查询的时候使用不同的分析器,则可以这样定义:
PUT my_index8/_mapping/_doc
{"properties": {"title": {"type": "text","analyzer": "my_ik_analyzer","search_analyzer": "other_analyzer" }}
}
测试:
PUT my_index8/_doc/1
{"title": "张三说的确实在理"
}GET /my_index8/_search
{"query": {"term": {"title": "张三"}}
}
Analyzer使用顺序
可以为每个查询、每个字段、每个索引指定分词器。
-
在索引阶段ES按照如下顺序选用分词:
- 首先选用字段mapping定义中指定的analyzer
- 字段定义中没有指定analyzer,则选用 index settings中定义的名字为default 的analyzer
- 如index setting中没有定义default分词器,则使用 standard analyzer
-
在查询阶段ES按照如下顺序需用分词
- 在查询语句中指定的analyzer
- 在字段mapping的search_analyzer中定义的analyzer
- 在字段mapping中定义的analyzer
- 在index settings中名为default_search的analyzer
- 在index settings中名为default的analyzer
- standard analyzer
这篇关于Elasticsearch搜索引擎第六篇-分词器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








