本文主要是介绍Spark程序设计——accumulator、广播变量、cache,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(一)accumulator(累加器、计数器)
类似于MapReduce中的counter,将数据从一个节点发送到其他各个节点上去。
通常用于监控,调试,记录符合某类特征的数据数目等。
–分布式counter
Accumulator使用
import SparkContext._
val total_counter=sc.accumulator(OL,"total_counter")//第一个参数表示数字0和long,第二个参数是counter的名字
//定义两个累加器
val counter0=sc.accumulator(OL,"counter0")
val counter1=sc.accumulator(OL,"counter1")val count=sc.parallelize(1 to n,slices).map{i=>total_counter+=1
val x=random*2-1
val y=random*2-1
if(x*x+y*y<1){counter1 +=1 }//累加器counter1加1else{counter0 +=1//累加器counter0加1}if(x*x+y*y<1)1 else 0}.reduce(_+_)(二)广播变量
广播机制
– 高效分发大对象,比如字典(map),集合(set)等,每个executor一份,而不是每个task一份。
HttpBroadcast与TorrentBroadcast(基于ptop协议,例子电驴下载)
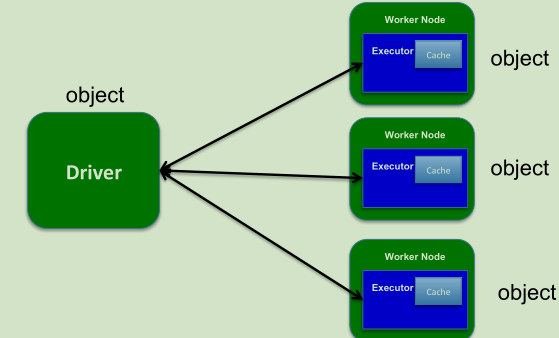
不使用广播–低效
val data=Set(1,2,4,6,.....)//大小为128MB
val rdd=sc.parallelize(1 to 6,2)
val observedSizes=rdd.map(_=>data.size)使用广播高效
val data=Set(1,2,4,6,....)//大小为128MB
val bdata=sc.broadcast(data)//将大小为128MB的Set广播出去
val rdd=sc.parallelize(1 to 1000000,100)
val observedSizes=rdd.map(_=>bdata.value.size.....)
//在各个task中,通过bdata.value获取广播的集合(三)cache基本概念和使用
Spark RDD Cache
__允许将RDD缓存到内存中或磁盘上,以便重用。
__Spark提供了多种缓存级别,以便于用户根据实际需求进行调整。

RDD cache的使用
val data=sc.textFile("hdfs://nn:8020/input")
data.cache()
//data.persist(StorageLevel.DISK_ONLY_2)深入cache
//下面两段代码的区别在于cache的使用:
val data=sc.textFile("hdfs://nn:8020/input")
data.cache()
data.filter(_.startWith("error")).count
data.filter(_.endWith("hadoop")).count
data.filter(_.startWith("hbase")).count
......从磁盘上读取1次,之后从内存中读取(在遇到action时执行,将数据加载到内存中)

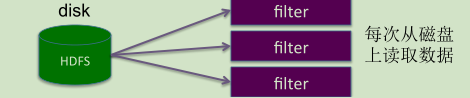
val data=sc.textFile("hdfs://nn:8020/input")
data.filter(_.startWith("error")).count
data.filter(_.endWith("hadoop")).count
data.filter(_.startWith("hbase")).count
......每次从磁盘上读取数据
这篇关于Spark程序设计——accumulator、广播变量、cache的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



