本文主要是介绍【大厂AI课学习笔记NO.52】2.3深度学习开发任务实例(5)需求采集考虑维度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天来学习,怎么做需求分析,如何明确数据采集需求。
我把自己考试通过的学习笔记,都分享到这里了,另外还有一个比较全的思维脑图,我导出为JPG文件了。下载地址在这里:https://download.csdn.net/download/giszz/88868909
本系列都是基于腾讯人工智能AI课的内容,学习笔记,分享给大家,需要更看全面任务的,去腾讯云官网看原文。
详细见下表:
| 待确认 | 说明 | 确认结果 |
|---|---|---|
| 赛道样式 | 明确赛道样式,看是否有和标志类似的图案 | 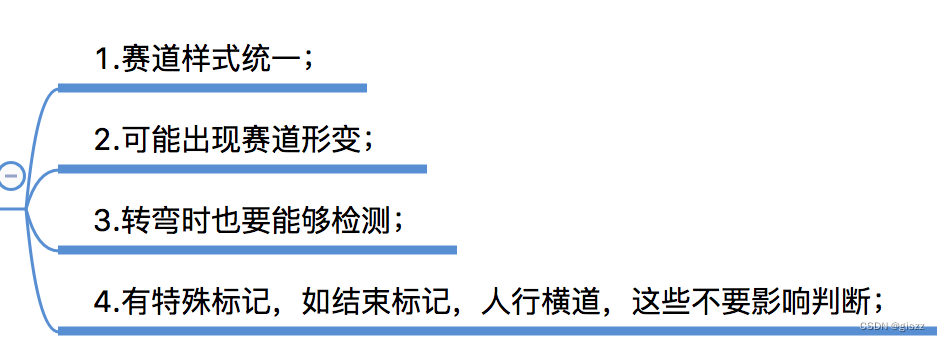 |
| 使用场地与光照情况 | 明确模型使用场景与光照情况 |
|
| 明确交通标志倾斜角度范围 | 需要检测的交通标志的俯仰角(pitch)、偏航角(yaw)、翻滚角(roll) |
这里要有空间想象力,就是注意一点,不是以地面作为xy平面坐标,而是以这个标志牌为平面,再想象出一个z轴,就清晰了。 如上图,x为轴——俯仰角 y为轴——偏航角 z为轴——翻滚角 |
| 明确需要检测的交通标志包含哪些 | 明确需要检测的交通标志包含哪些;1.需要详细列举所有要被检测的交通标志,未被列举的标志不会被识别;2.交通标志的数量越多采集工作量越大; |  |
| 检测框覆盖范围 | 需要明确范围细节,如:1.是否包含杆体2.边缘出框情况等等 | 1.对于交通标志牌子,标注范围是交通标志牌所处范围即可; 2.对于交通信号灯,标注范围是灯亮的区域; 3.对于行人,标注范围是整个行人范围; 4.对于边缘出框的场景,如果出框范围不超过50%,也应当予以检测(如图 2最左侧和最右侧的标志应当能够检出); |
| 检出框分类 | 是否要对每个框体单独检出 | 不需要,只需要输出对应检测框即可
|
| 需要检测的交通标志的最小框 | 需要检测的交通标志的最小框最小框越小,运算量越大,执行效率越低;同时,太小的检测框容易使标注误差变大 | 玩具车速度较快,需要检测到距离车2米的标志,为后续的小车操控预留时间。 |
| 对图片模糊程度的要求 | 实际操作中摄像头模糊效果容忍程度怎样 | 玩具车摄像头帧率较高,且有处理算法,糊程度实际测试下来最大模糊程度如图 |
| 设备色差情况 | 是否存在设备色差 | 摄像头较好,无需考虑摄像头色差,但是在部分场景下可能产生由环境光引起的色域变化和噪点,如图
|



把上面这个表格理解透彻,基本就知道计算机视觉的需求采集,要考虑哪些内容了。
延伸学习:
在计算机视觉中进行需求采集时,需要考虑的维度和注意事项较多。以下是一些主要的维度和注意事项,以及相应的解决思路:
一、考虑的维度:
- 应用场景:明确计算机视觉系统的应用场景,如安防监控、自动驾驶、医疗诊断等,有助于确定所需的数据类型和处理方式。
- 数据类型:根据应用场景,确定需要采集的数据类型,如图像、视频、深度信息等。
- 数据量:评估所需的数据量,以确保训练出的模型具有足够的泛化能力。
- 数据质量:关注数据的清晰度、准确性、完整性和多样性,以提高模型的性能。
- 实时性要求:对于需要实时处理的应用场景,应关注算法的运算速度和效率。
二、公认的注意事项:
- 数据隐私和安全:在采集和处理数据时,应遵守相关法律法规,确保用户隐私和数据安全。
- 数据标注准确性:对于需要人工标注的数据集,应确保标注的准确性和一致性,以提高模型的训练效果。
- 数据偏差和不平衡问题:注意数据集中可能存在的偏差和不平衡问题,如类别不均衡、场景偏差等,这些问题可能导致模型在特定情况下的性能下降。
三、解决思路:
- 针对应用场景和数据类型,选择合适的采集设备和方案,确保数据的准确性和完整性。
- 对于数据量需求,可以通过数据增强、迁移学习等技术来扩充数据集,提高模型的泛化能力。
- 关注数据质量,采用图像预处理、去噪等技术改善图像质量,提高模型的性能。
- 针对实时性要求,优化算法和计算资源,提高处理速度。
- 遵守相关法律法规,加强数据加密和访问控制,确保数据隐私和安全。
- 建立完善的数据标注流程和质量控制机制,提高数据标注的准确性。
- 采用采样策略、数据扩充等技术解决数据偏差和不平衡问题,提高模型在各种情况下的性能。
总之,在计算机视觉中进行需求采集时,需要全面考虑应用场景、数据类型、数据量、数据质量和实时性要求等维度,并关注数据隐私、安全、标注准确性以及偏差和不平衡等问题。通过选择合适的采集方案、优化算法和计算资源以及加强质量控制等措施,可以有效地解决这些问题,提高计算机视觉系统的性能和可靠性。
这篇关于【大厂AI课学习笔记NO.52】2.3深度学习开发任务实例(5)需求采集考虑维度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








