本文主要是介绍创新性3D数据合成模型,微软推出EgoGen,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着AR、VR等设备的广泛应用,第一人称的应用开始增多。但在研发方面面临不同的挑战,例如,图像模糊、视觉混乱、遮挡更严重等,给视觉模型的训练带来重大挑战。
一方面,人工标注真实第一视角数据集,来培训深度学习模型的成本和难度都很高。另一方面,以往用于第三人称视角的虚拟渲染数据,无法很好地模拟第一视角下的真实人体运动与环境交互过程。
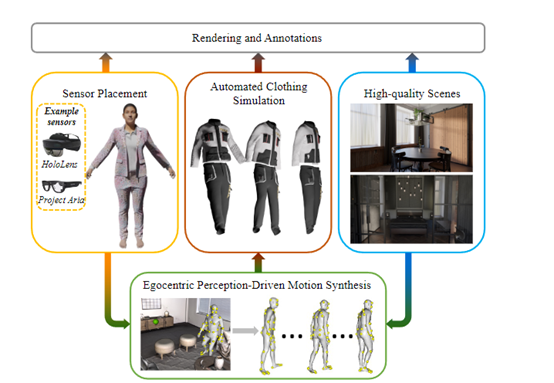
为了解决这些难题,微软和苏黎世联邦理工学院的研究人员推出了EgoGen,这是一个用于生成第一视角训练数据的模型。
EgoGen不仅具有高效的数据生成流程,还能够适用于多个自我中心感知任务,例如,生成的数据可以用于恢复自我中心视角下的人体网格。
论文地址:https://arxiv.org/abs/2401.08739
即将开源地址:https://github.com/ligengen/EgoGen

EgoGen使用了一种创新的人体运动合成模型来合成高数据。该模型通过直接利用虚拟人的自我中心视觉输入,来感知周围3D环境。
与先前的方法相比,EgoGen的模型消除了对预定义全局路径的需求,并且可以直接应用于动态环境。
生成模型训练
EgoGen模型的第一阶段,研究人员使用了一种生成模型来训练虚拟人物的行为,将身体运动和感知过程无缝地结合起来。
身体运动与感知的关键点是使虚拟人能够通过自我感知的视觉输入看到他们的环境,并通过学习控制一组避免碰撞的运动基元的策略来做出相应的反应,这些基元可以组合以合成长期的多样化人类动作。
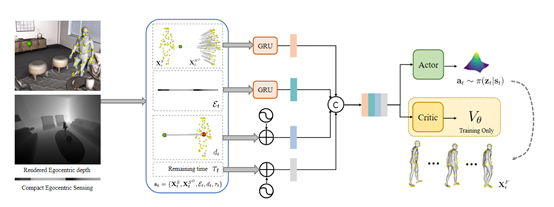
通常我们生成的运动基元模型具有无界和高维的潜在动作空间,直接通过渲染的自我感知图像进行策略训练是很不稳定的。
所以,EgoGen使用了一种高效的自我感知视觉代理的双阶段强化学习方案,无缝地将自我感知视觉线索和身体运动相结合,同时使用了“注意”奖励来激励自我感知行为。
强化学习优化
研究人员使用了强化学习优化方法对生成模型进行性能优化,可以让虚拟人物能够以最佳方式感知环境、规避障碍并达到目的地。
主要通过奖励函数的引导,使虚拟人物的运动变得更加自然和逼真。具体来说,当虚拟人物在生成过程中朝着期望的方向观察时,将受到"注意"奖励的正向反馈。
这意味着如果虚拟人物能够集中注意力并关注与任务相关的对象或区域,将获得额外的奖励信号。这鼓励虚拟人物在感知任务中更加专注和准确。
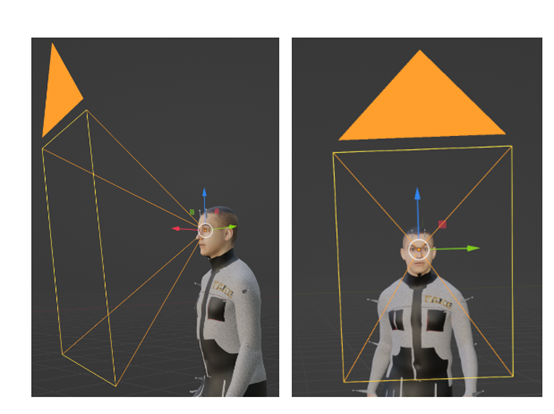
"注意"奖励的实现方式可以根据具体情况进行调整。例如,在训练过程中,可以通过监测虚拟人物的视觉输入和目标方向之间的一致性来计算奖励值。
如果虚拟人物的注意力与任务目标的位置或运动方向相一致,奖励值将增加;反之,如果虚拟人物的注意力偏离了任务目标,奖励值将减少或为负值。

通过不断优化生成模型,并利用这些奖励信号进行反馈,逐步改进了虚拟人物的行为,使其能够准确地感知和适应复杂的环境。

为了验证EgoGen方法的有效性,研究人员在三个第一人称的感知任务上进行了综合评估:头戴式摄像头的建图和定位、摄像头跟踪以及从第一视角恢复人体网格。
通过使用EgoGen生成的高质量合成数据,并提供精确的地面真实标注,现有的最先进算法在这些任务上的性能全部得到了大幅度增强。
本文素材来源EgoGen论文,如有侵权请联系删除
END
这篇关于创新性3D数据合成模型,微软推出EgoGen的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








