本文主要是介绍【土堆】目标检测の入门实战——手把手教你使用 Make Sense 和 CVAT 在线标注 VOC 数据集与 COCO 数据集 用 PyTorch 读取自制 COCO 数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
一、什么是目标检测
二、VOC 数据集
1、下载 VOC 数据集
2、介绍 VOC 数据集
三、COCO 数据集
1、下载 COCO 数据集
2、介绍 COCO 数据集
四、在线标注数据集
1、Make Sense
2、CVAT
五、本地标注数据集
1、精灵标注助手
六、论 Python 的元组、字典与数组
七、用 PyTorch 加载 COCO 数据集
八、用 PyTorch 读取自己的 COCO 数据集
前言
视频教程为 B 站我是土堆的 PyTorch 深度学习目标检测入门实战系列,所有代码均为视频演示版本,非本人原创。
一、什么是目标检测
目标检测 Object Detection :检测,不仅要找到图片上的所关心的目标 位置 ,同时还要识别出这个目标是什么 类别 。目标,根据我们应用的场景进行定义。比如在人脸检测场景中,我们可以把 人脸 当作目标。在文字检测场景中,我们可以把 文字 当作目标。如今,更多的科研研究都是聚焦于自然场景中的目标检测,检测的目标主要就是生活中常见的物体类别,这类检测问题的特点是目标种类多,目标位置较为复杂多样。
【补充】主流的目标检测都是以 矩阵框 的形式进行输出的,而语义分割比目标检测的精度更高。
二、VOC 数据集
PASCAL VOC 官网:The PASCAL Visual Object Classes Homepage
torchvision.datasets.VOCDetection 官方文档:VOCDetection — Torchvision 0.16 documentation
torchvision.datasets.VOCSegmentation 官方文档:VOCSegmentation — Torchvision 0.16 documentation
【补充】推荐使用 Google 浏览器,在 Microsoft Bing 网站中搜索 PASCAL VOC ,点击进入PASCAL VOC 官网。
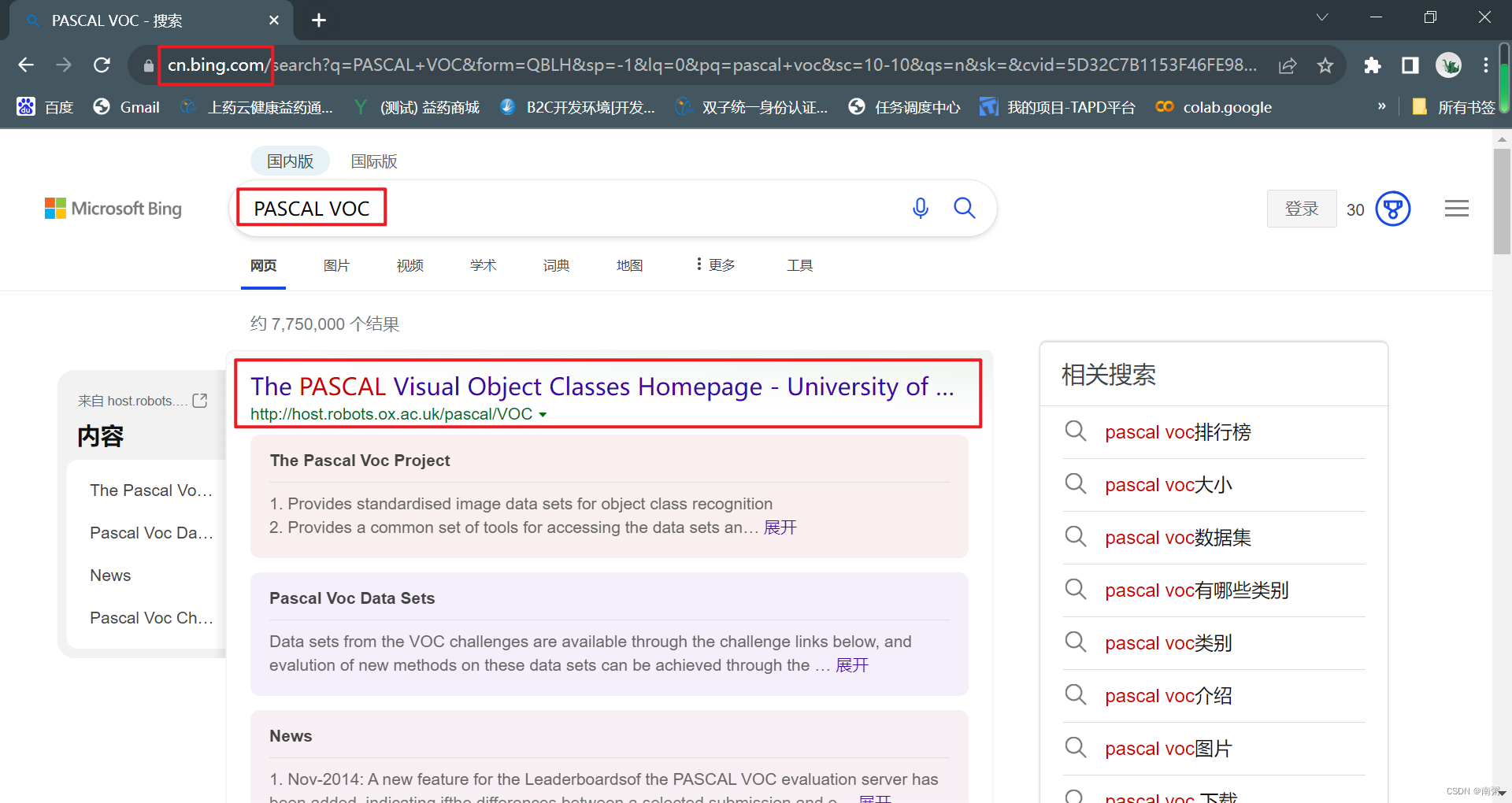
1、下载 VOC 数据集
我们通常使用 VOC 2007 数据集和 VOC 2012 数据集,具体原因见下图:

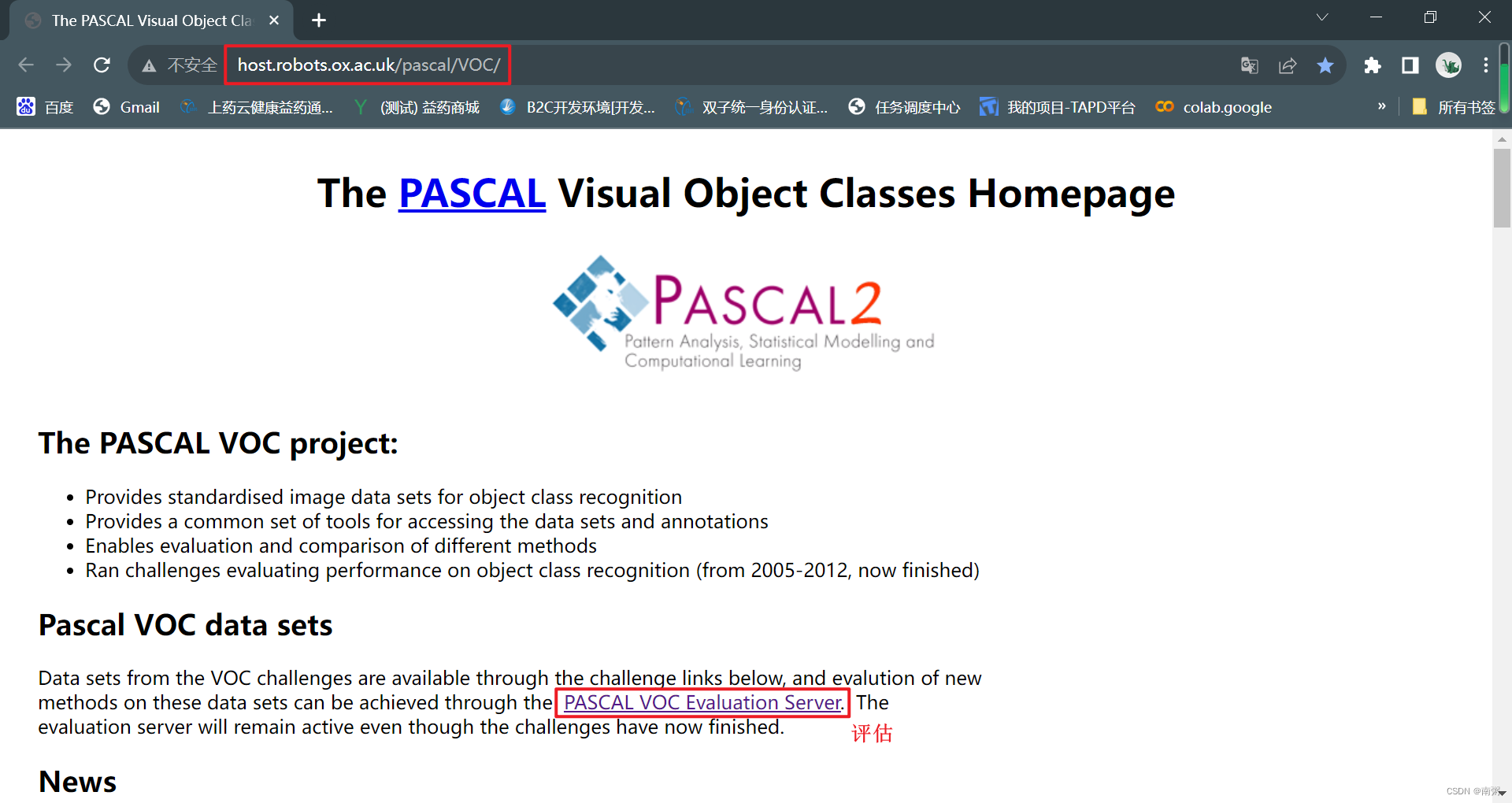
VOC 2007 版:The PASCAL Visual Object Classes Challenge 2007 (VOC2007)

VOC 2012 版:The PASCAL Visual Object Classes Challenge 2012 (VOC2012)

2、介绍 VOC 数据集
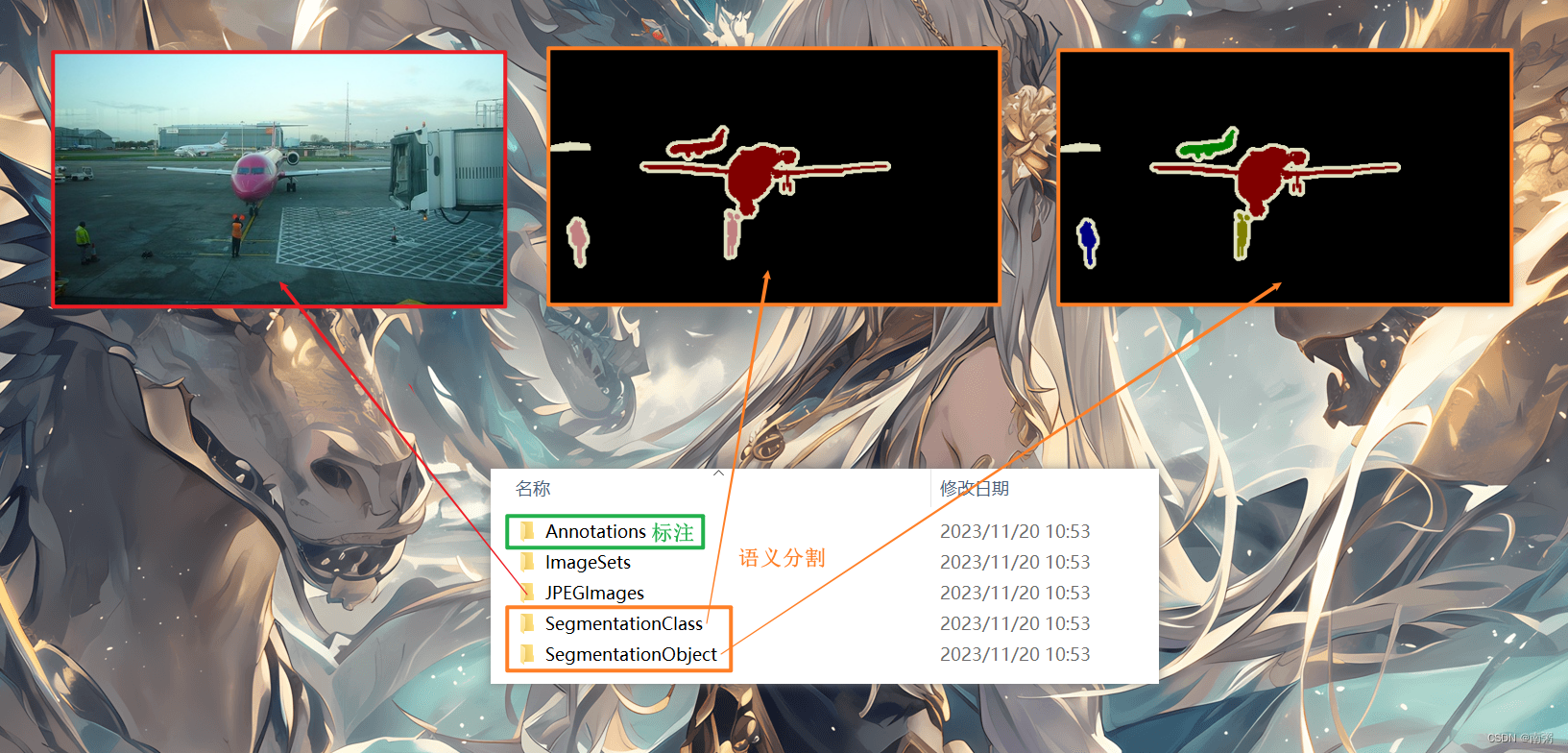
在官网下载 VOC 数据集后,我们需要大致了解 VOC 数据集的文件夹结构:
- Annotations :包含 xml 文件,描述了图片的各种信息,特别是目标的位置坐标
- ImageSets :主要关注 Main 文件夹的内容,里面的文件包含了不同类别目标的训练数据集与验证数据集图片名称
- JPEGImages :原图片
- SegmentationClass :用于语义分割
- SegmentationObject :用于语义分割
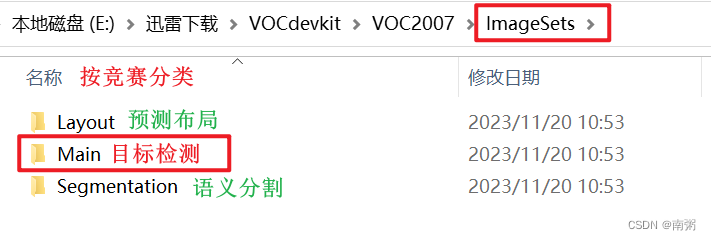
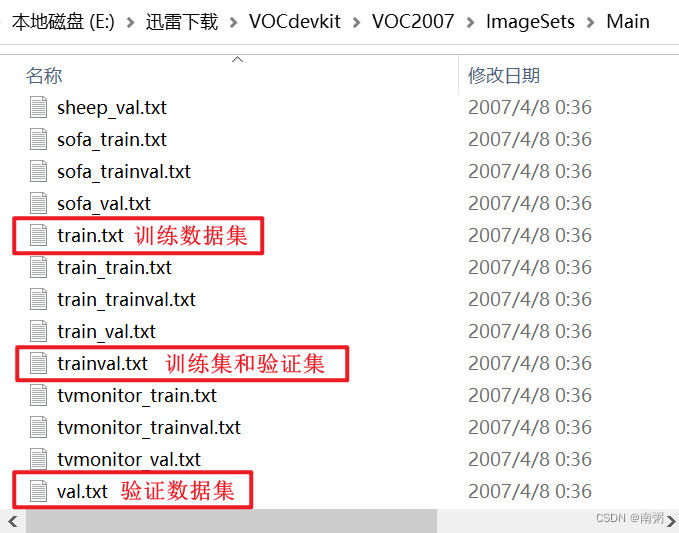
【操作1】在进入 ImageSets 文件夹后,我们可以发现里面有三个按竞赛分类的文件夹,其中 Main 文件夹是需要我们在做 目标检测 时重点关注的:
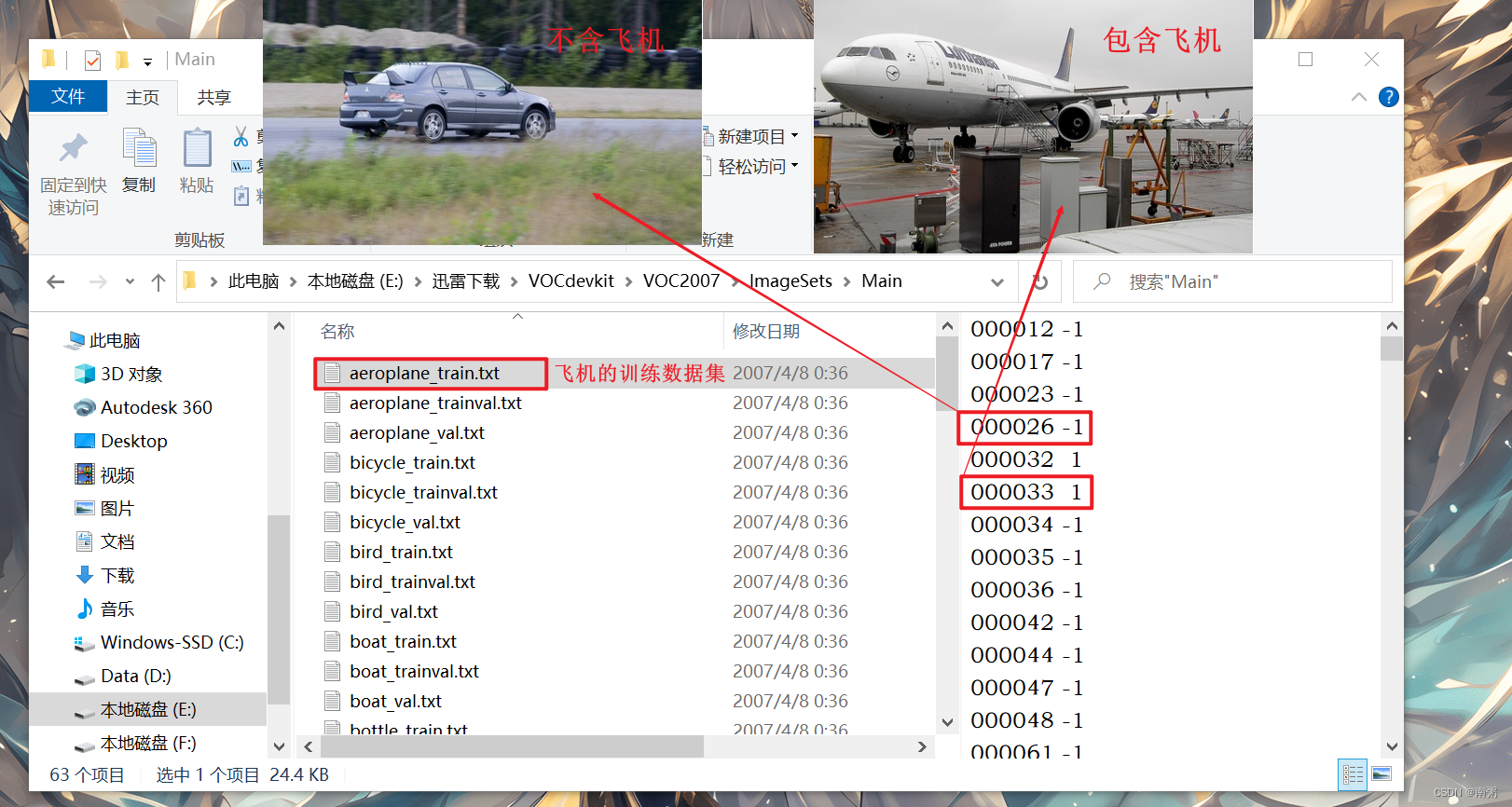
【操作2】在进入 Main 文件夹后,可以看到有 train.txt 训练数据集、 val.txt 验证数据集和 trainval.txt 训练与验证数据集三类。
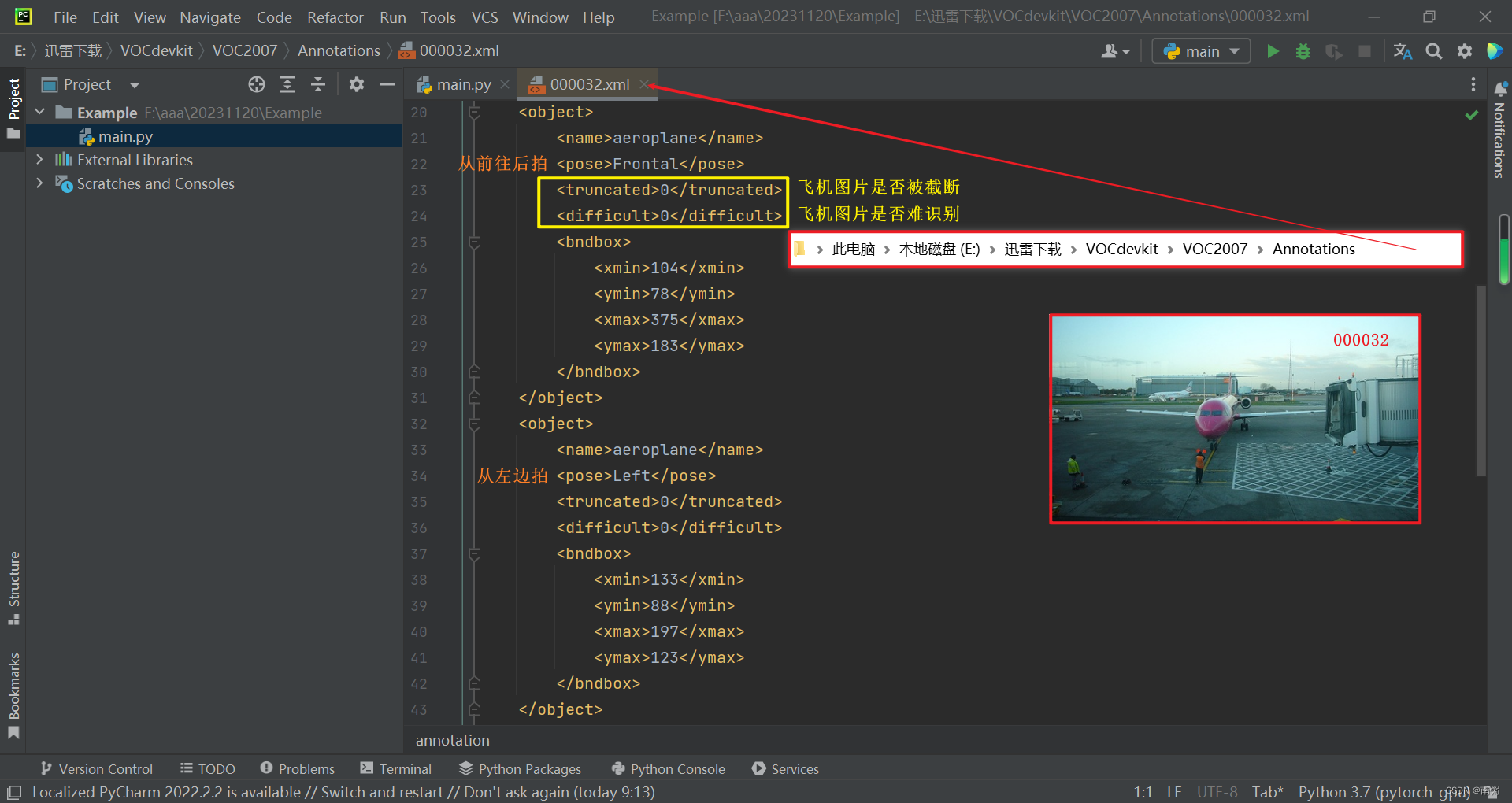
【操作3】在 PyCharm 中打开 Annotations 标注文件夹中的任意 .xml 文件,查看文件内容:
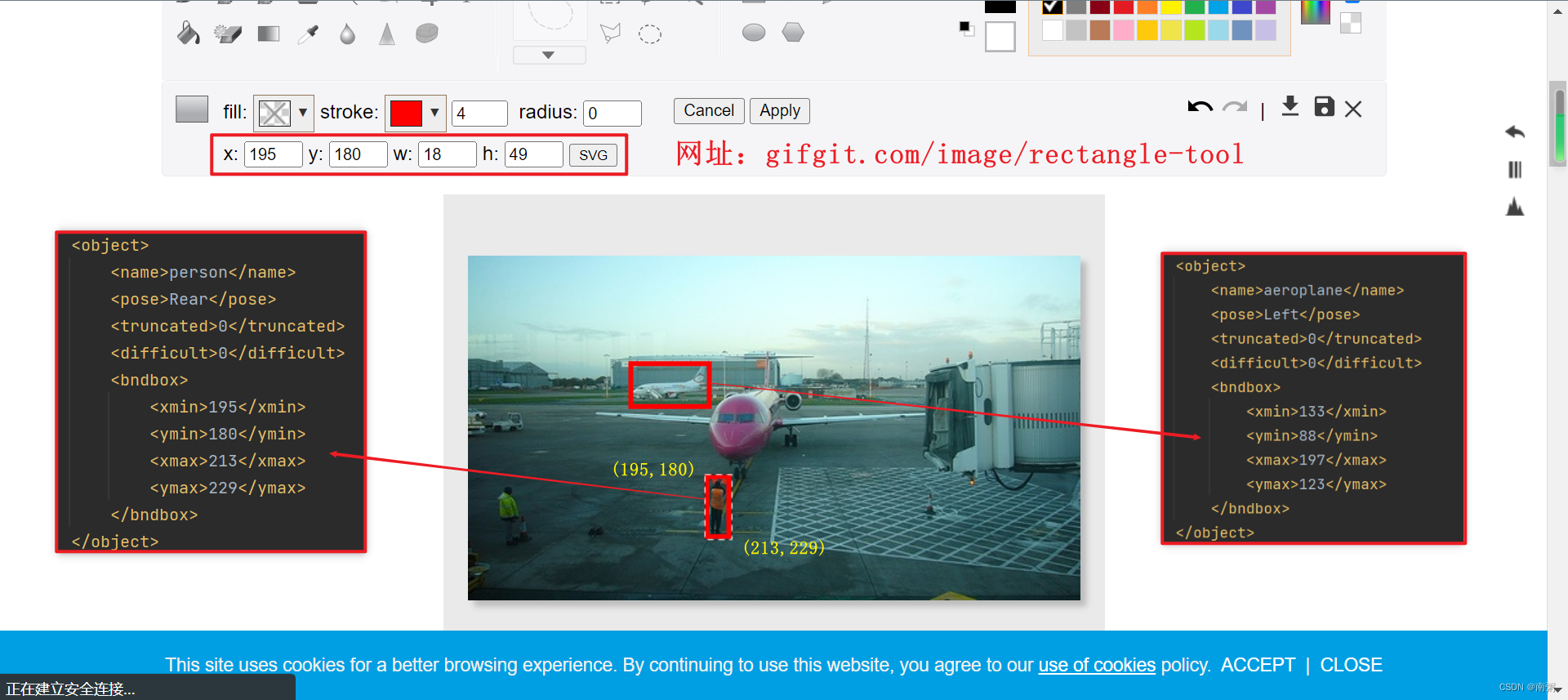
【操作4】可以借助 Gifgit 网站来验证 .xml 文件中 xmin 、ymin 、xmax 、ymax 所确定的标注框的位置。
三、COCO 数据集
COCO 官网:COCO - Common Objects in Context
【补充】VOC 数据集和 COCO 数据集是使用较多的数据集,COCO 数据集比 VOC 数据集大,适用于大型项目。
1、下载 COCO 数据集
我们通常使用 COCO 2017 数据集,具体的下载地址可以参考下表,推荐使用迅雷下载:
| 2017 Train Images 训练集 | http://images.cocodataset.org/zips/train2017.zip |
| 2017 Val Images 验证集 | http://images.cocodataset.org/zips/val2017.zip |
| 2017 Test Images 测试集 | http://images.cocodataset.org/zips/test2017.zip |
| 2017 训练集与验证集的对应标注 | http://images.cocodataset.org/annotations/annotations_trainval2017.zip |
因为我进入 COCO 官网后加载不出 DownLoad 页面,所以我只能根据官网提供的 GitHub 找到数据集的下载地址:
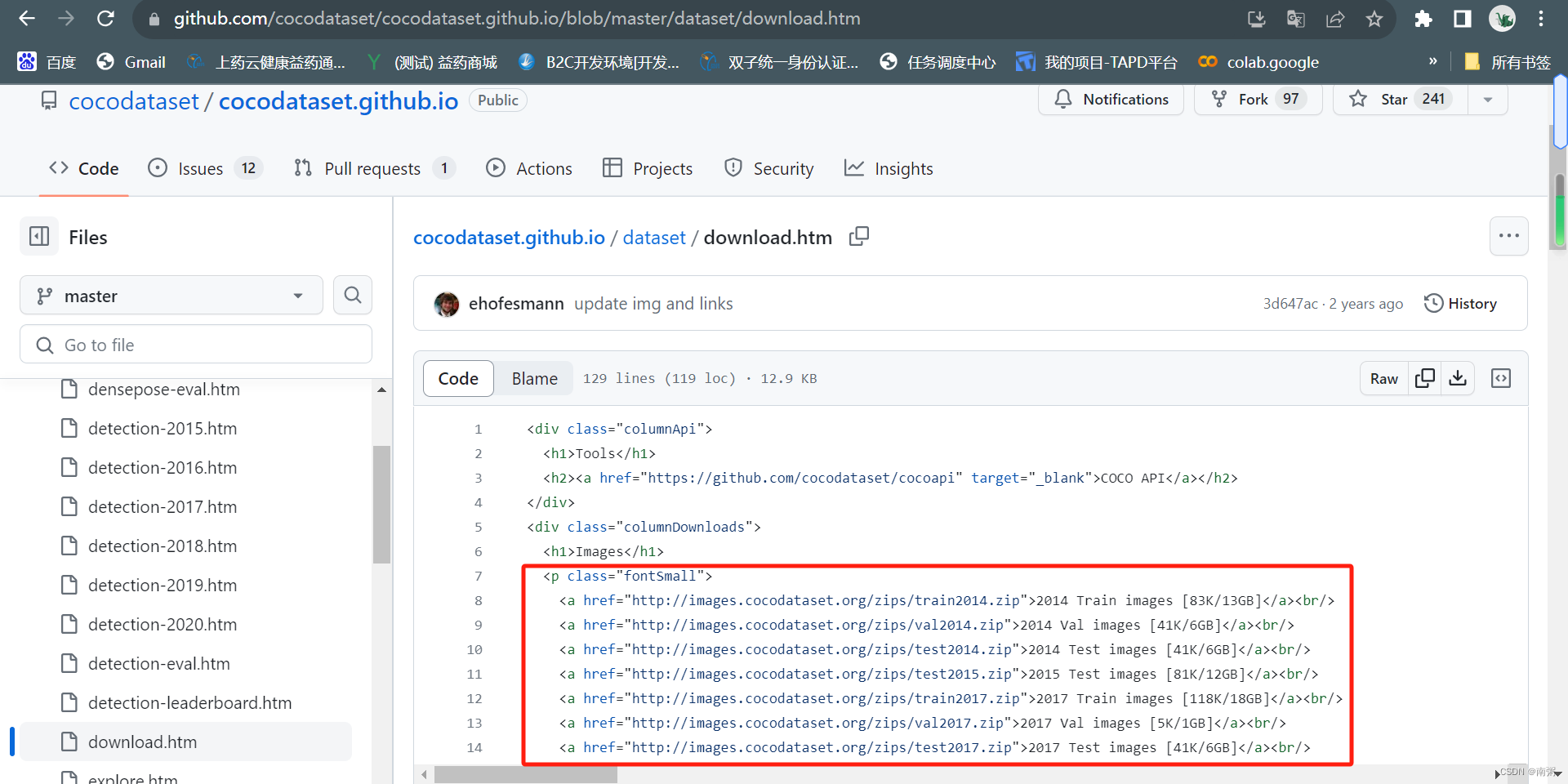
2、介绍 COCO 数据集
由于电脑存储空间的限制,我只下载了 COCO 2017 的验证集和对应标注,标注文件夹的结构大致如下:

由于 intances_val2017.json 文件内容比较多,所以我选用土堆的视频教程的截图来讲解两个示例,相关文字已经展示在图中,不再赘述。
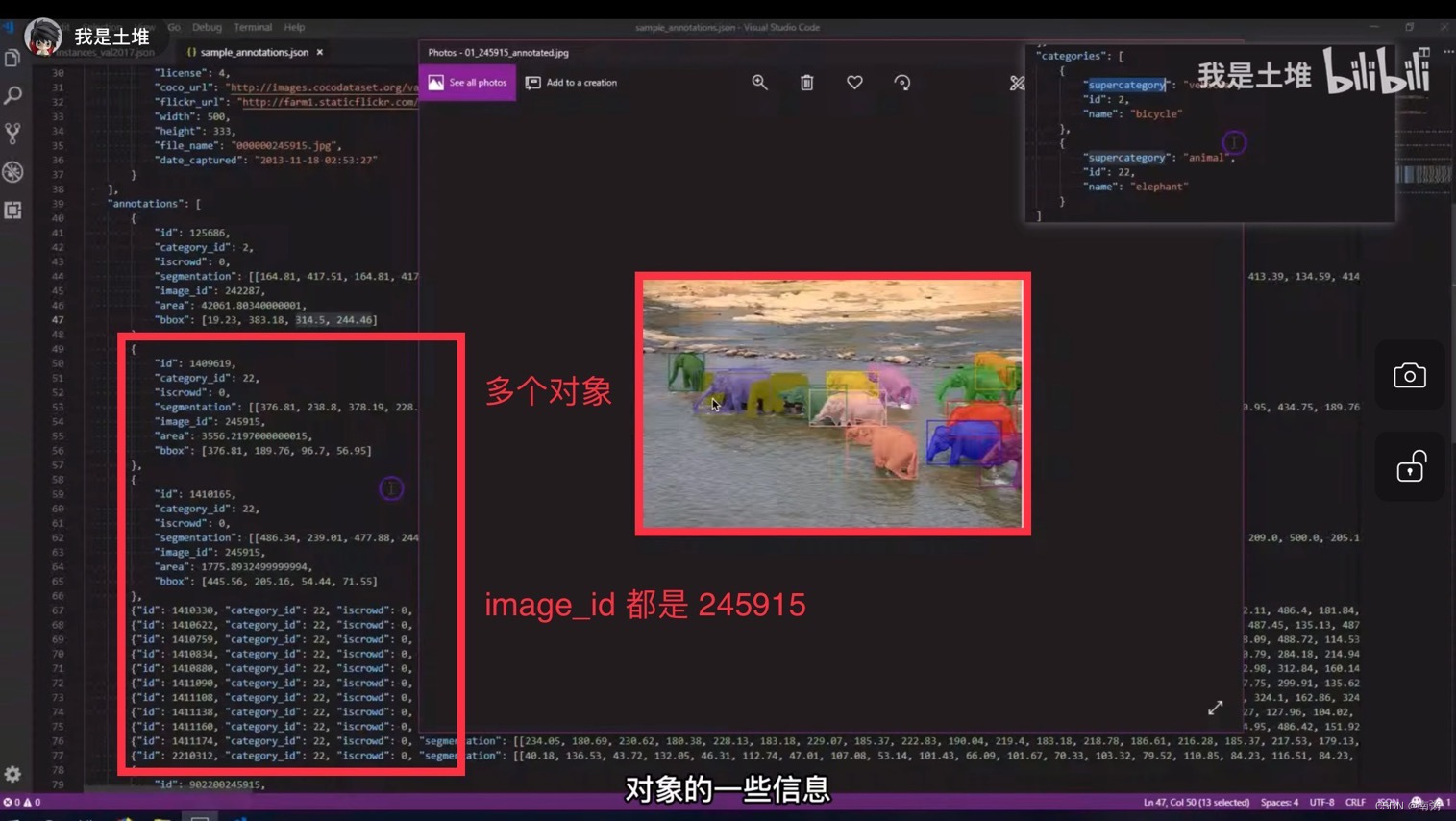
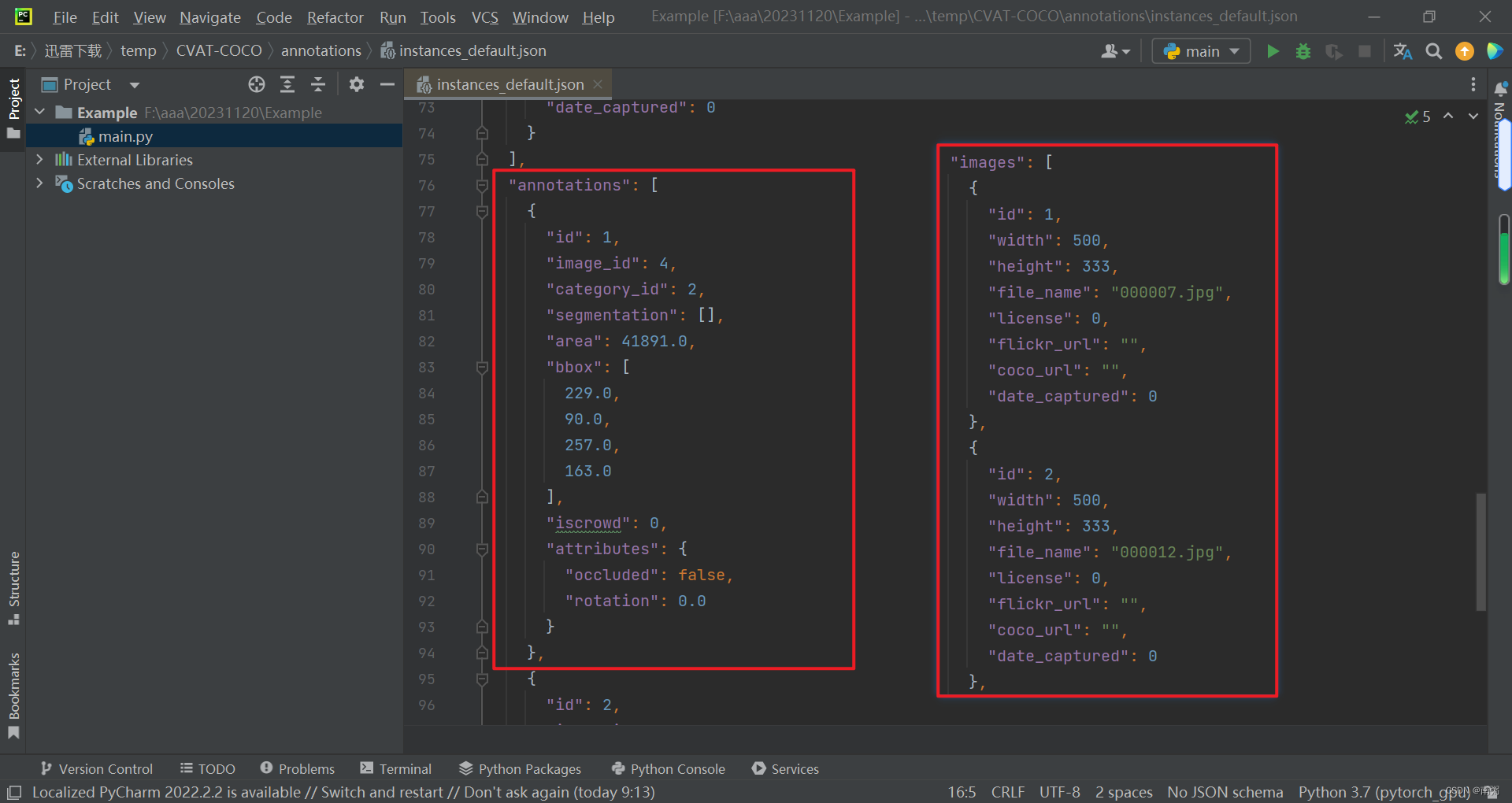
【示例1】重点关注 images 和 annotations 两部分的内容,annotations 中的 image_id 与 images 中的 id 相对应。
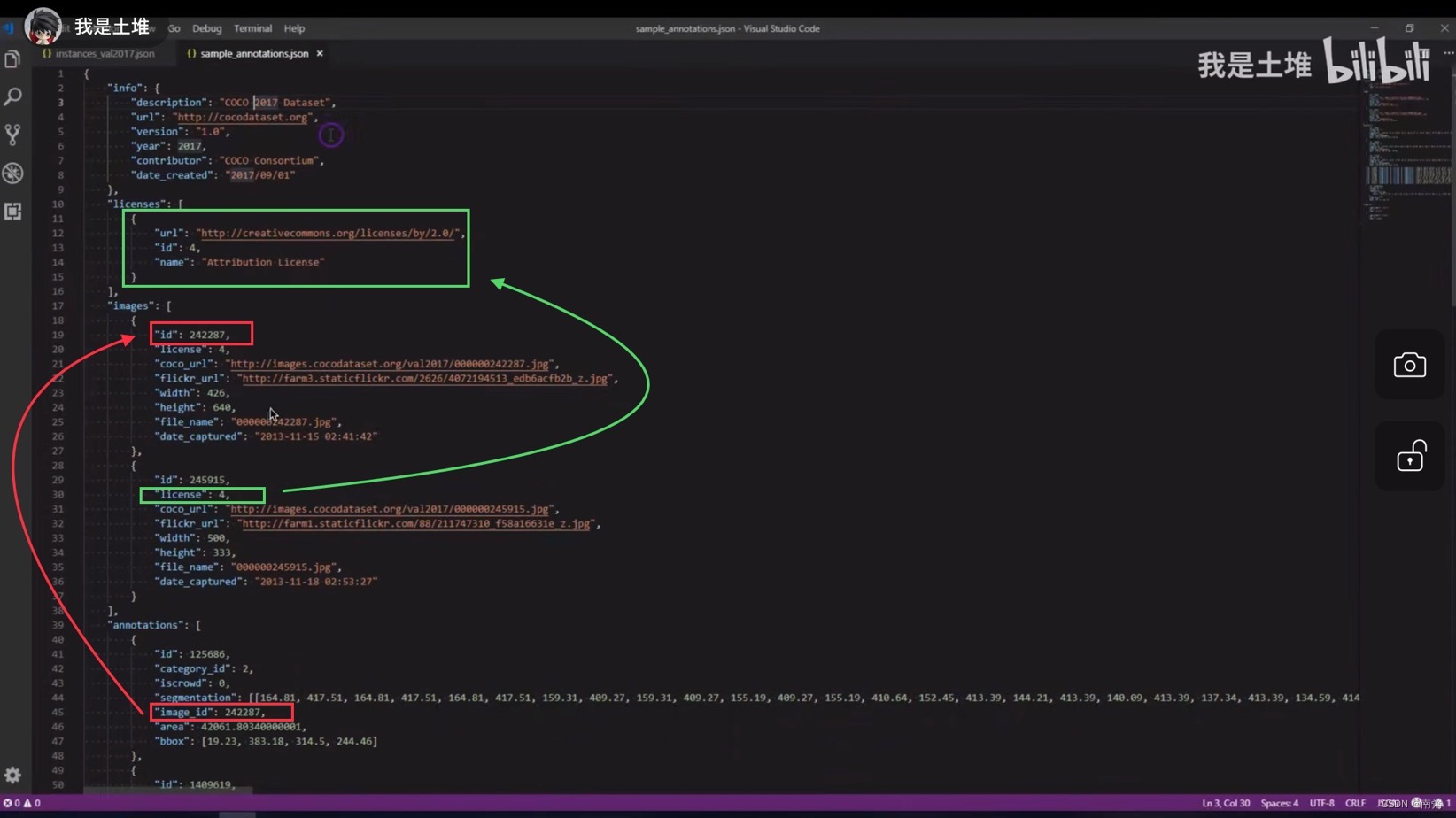
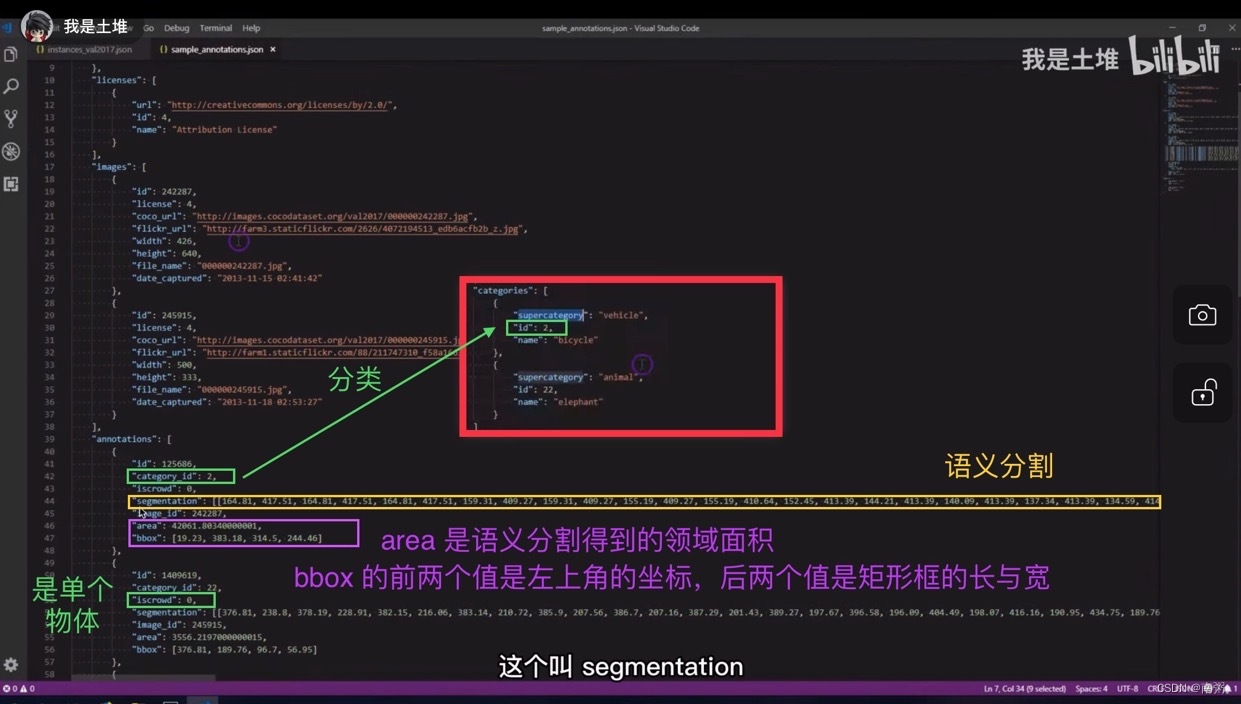
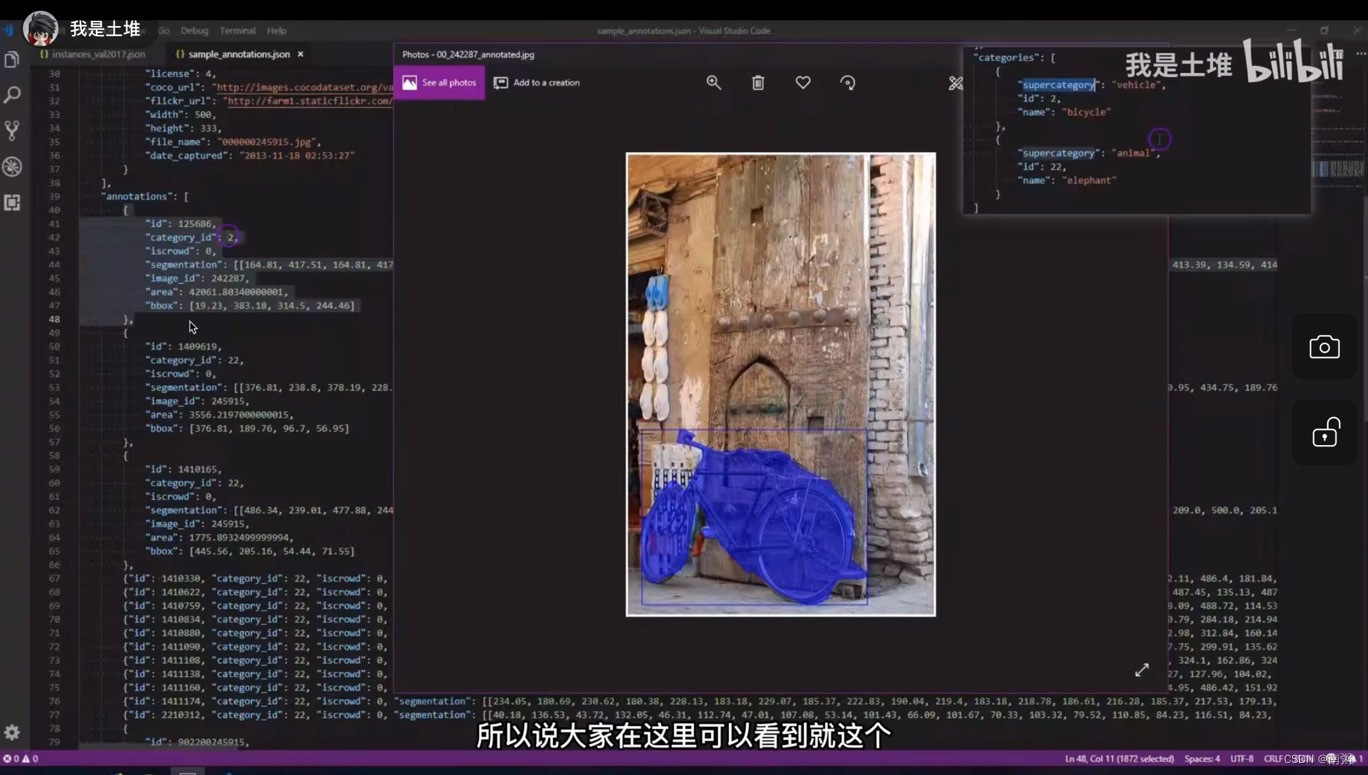
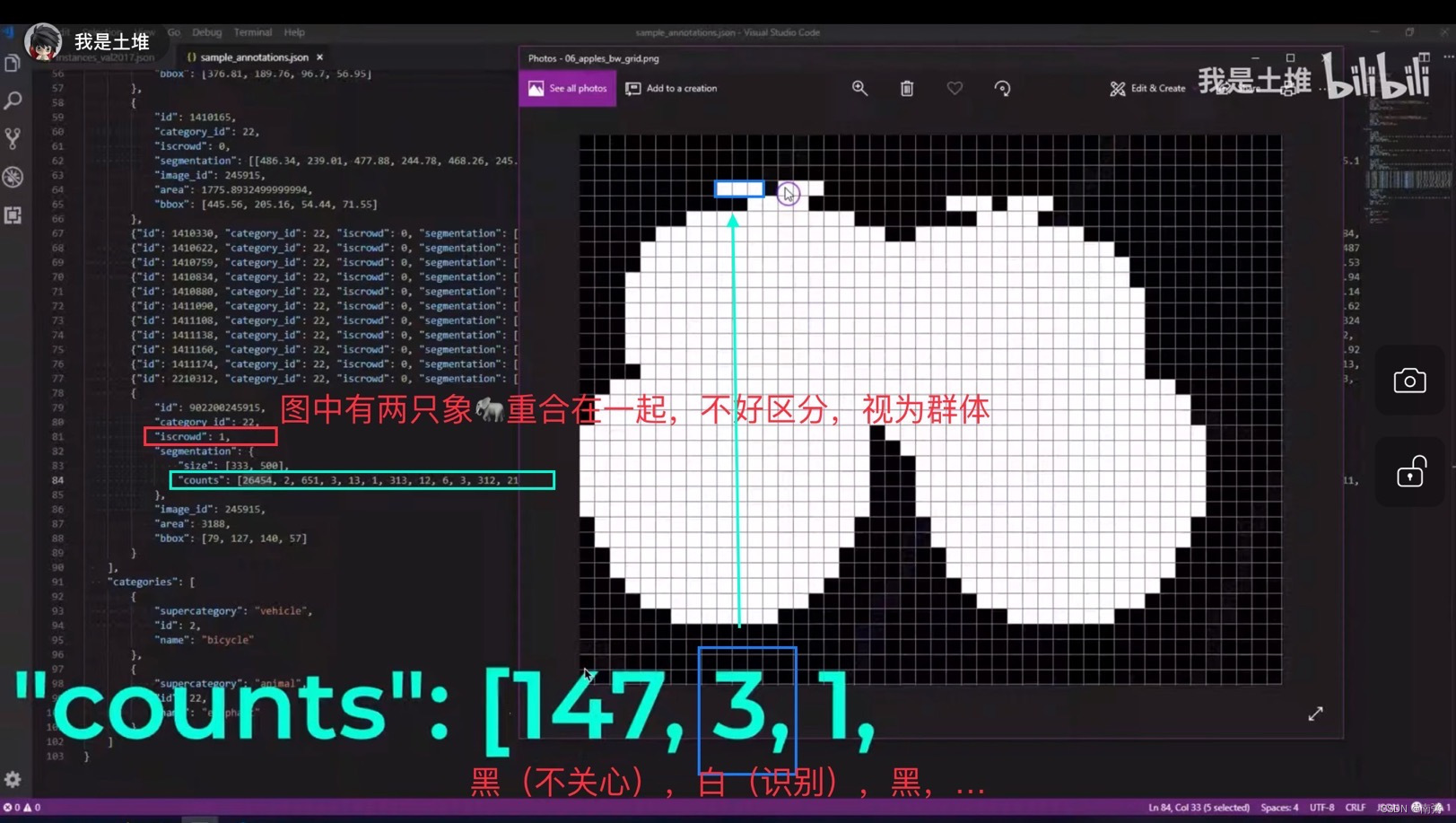
【示例2】上面讲的是单个物体的 json 内容,现在来讲多个物体的 json 内容,多个物体可以分 多个单物体 和 群体 两种形式,需要关注 iscrowd 字段和语义分割 segmentation 中的 counts 字段。
四、在线标注数据集
1、Make Sense
Make Sense 官网:Make Sense

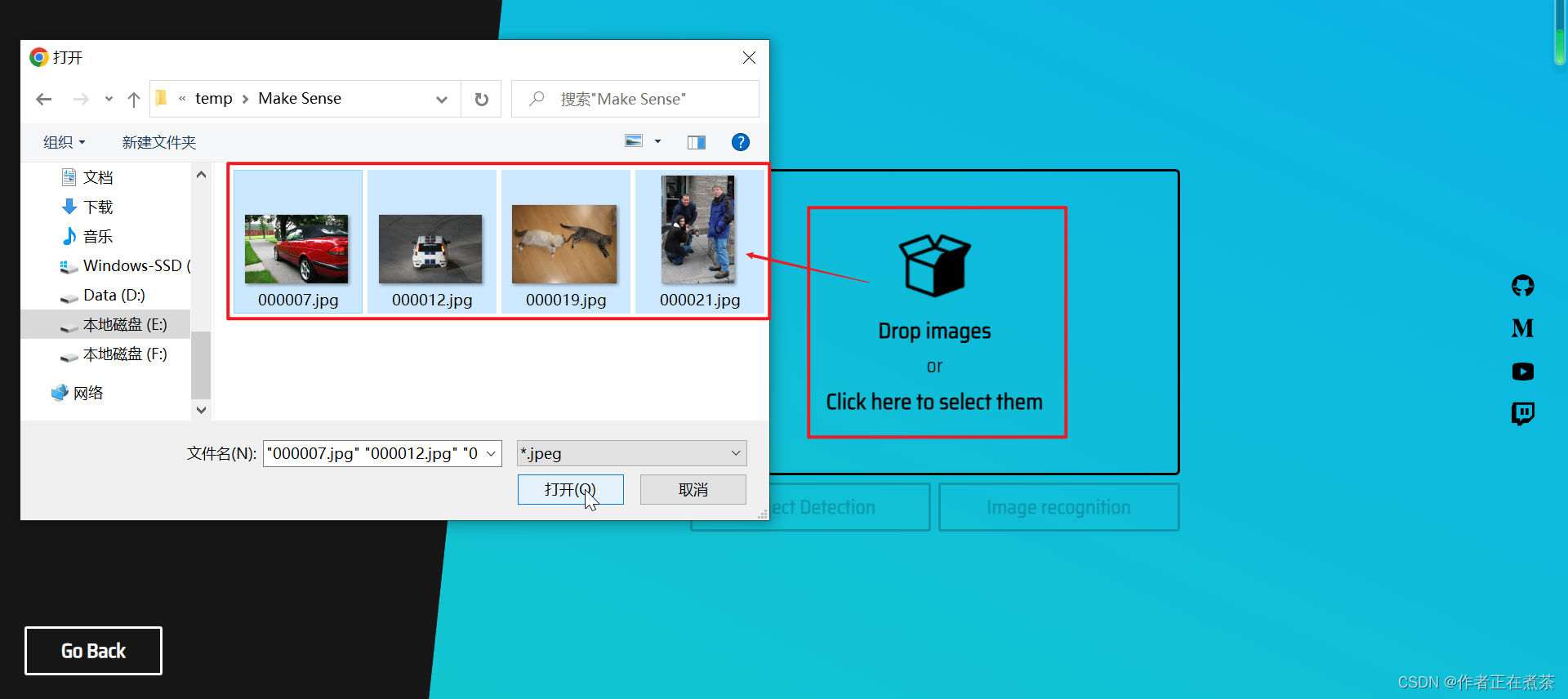
【操作1】在 Make Sense 官网点击 Get Started 快速开始,将准备的 Images 上传至平台。
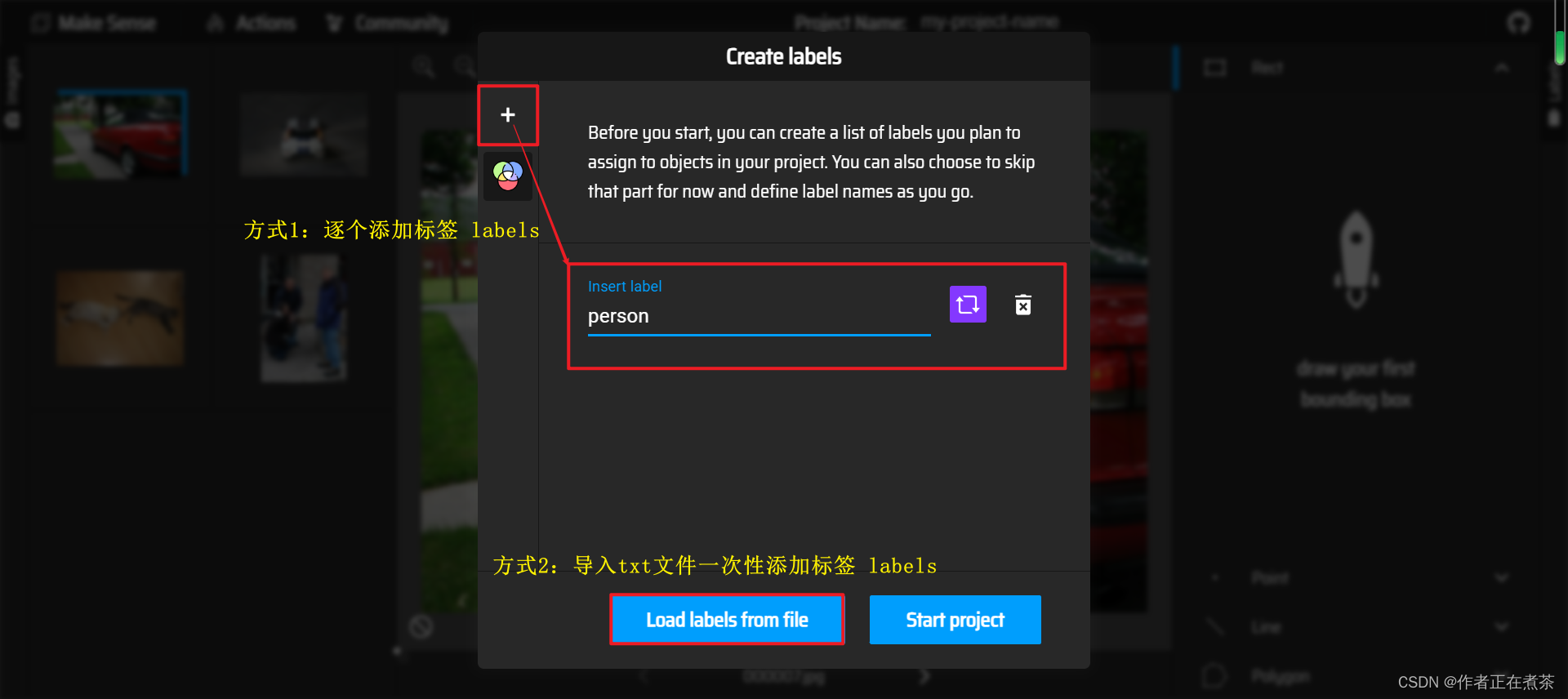
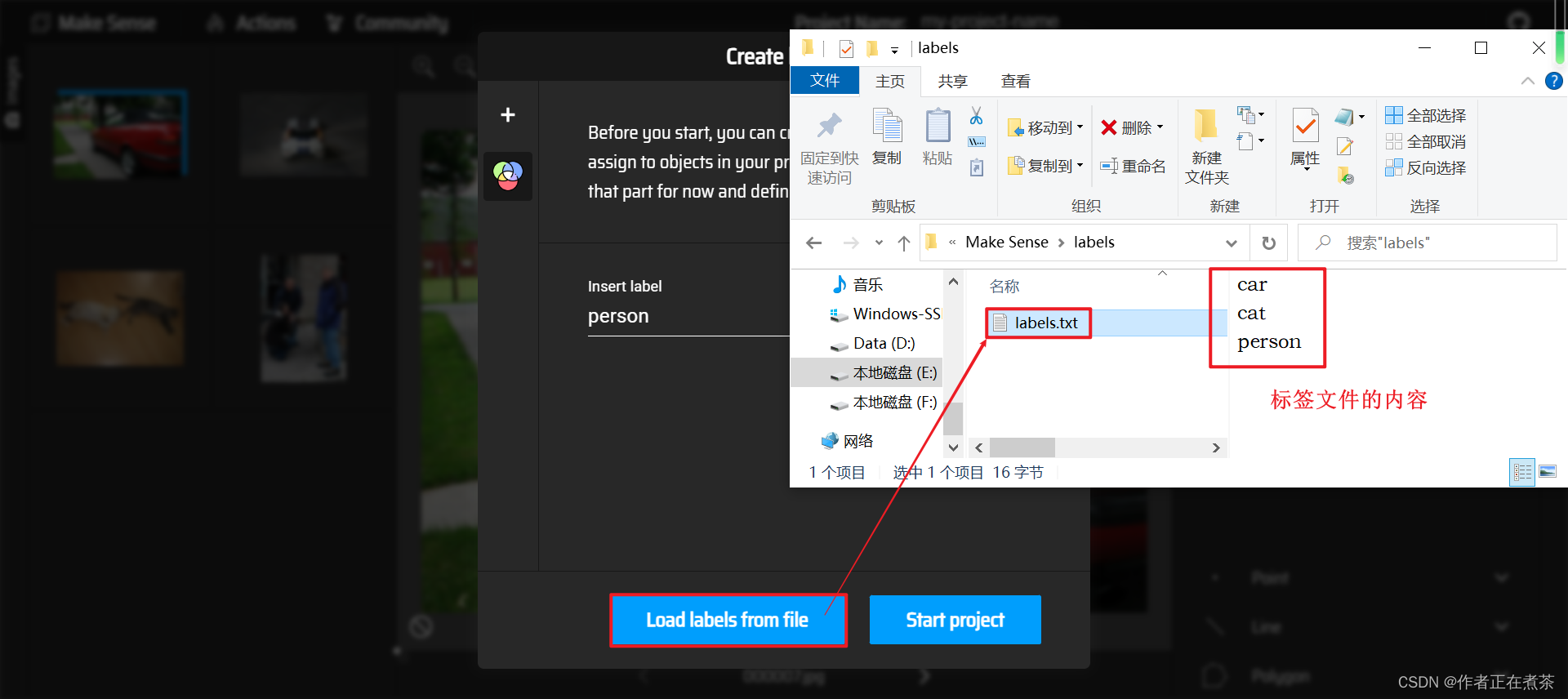
【操作2】为导入的 Images 添加标签 Labels,可以使用 + 逐个添加标签,也可以 Load labels from file 一次性添加标签。
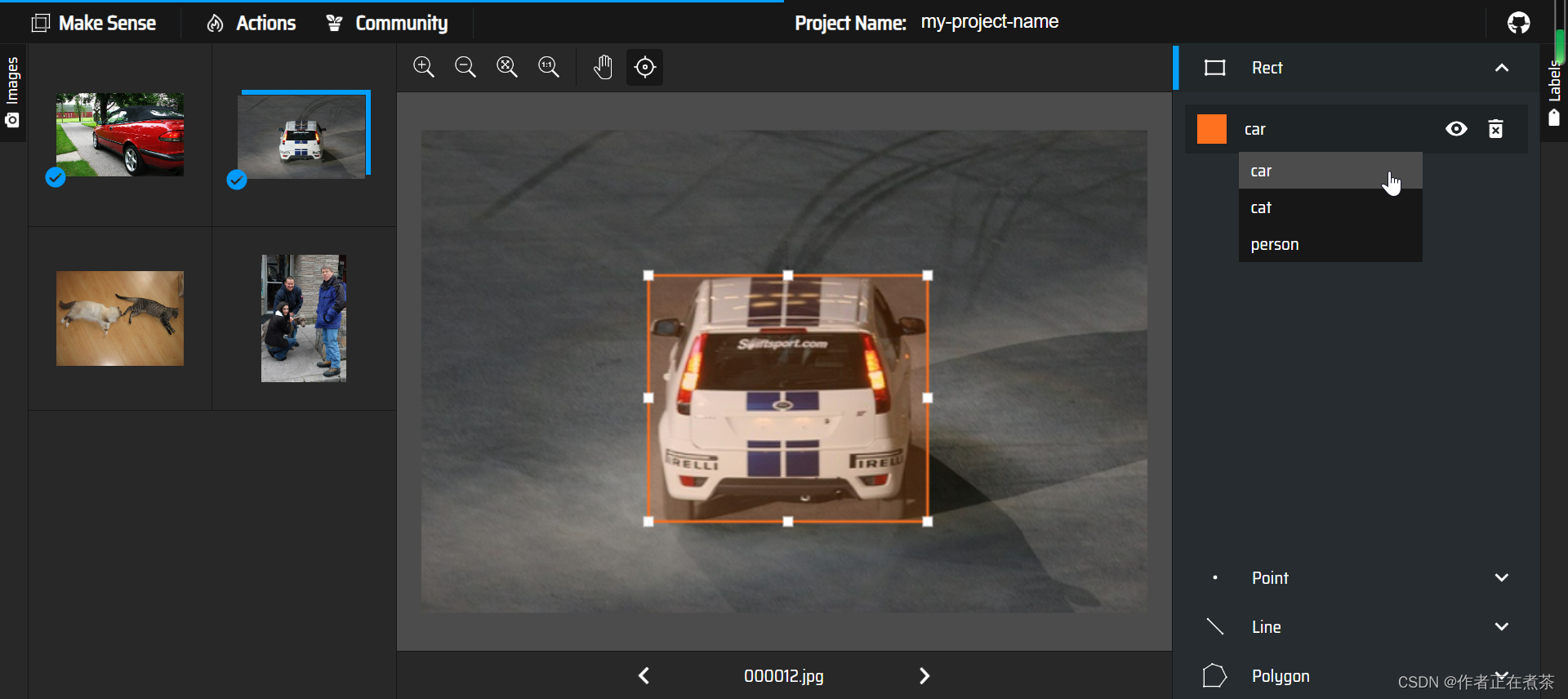
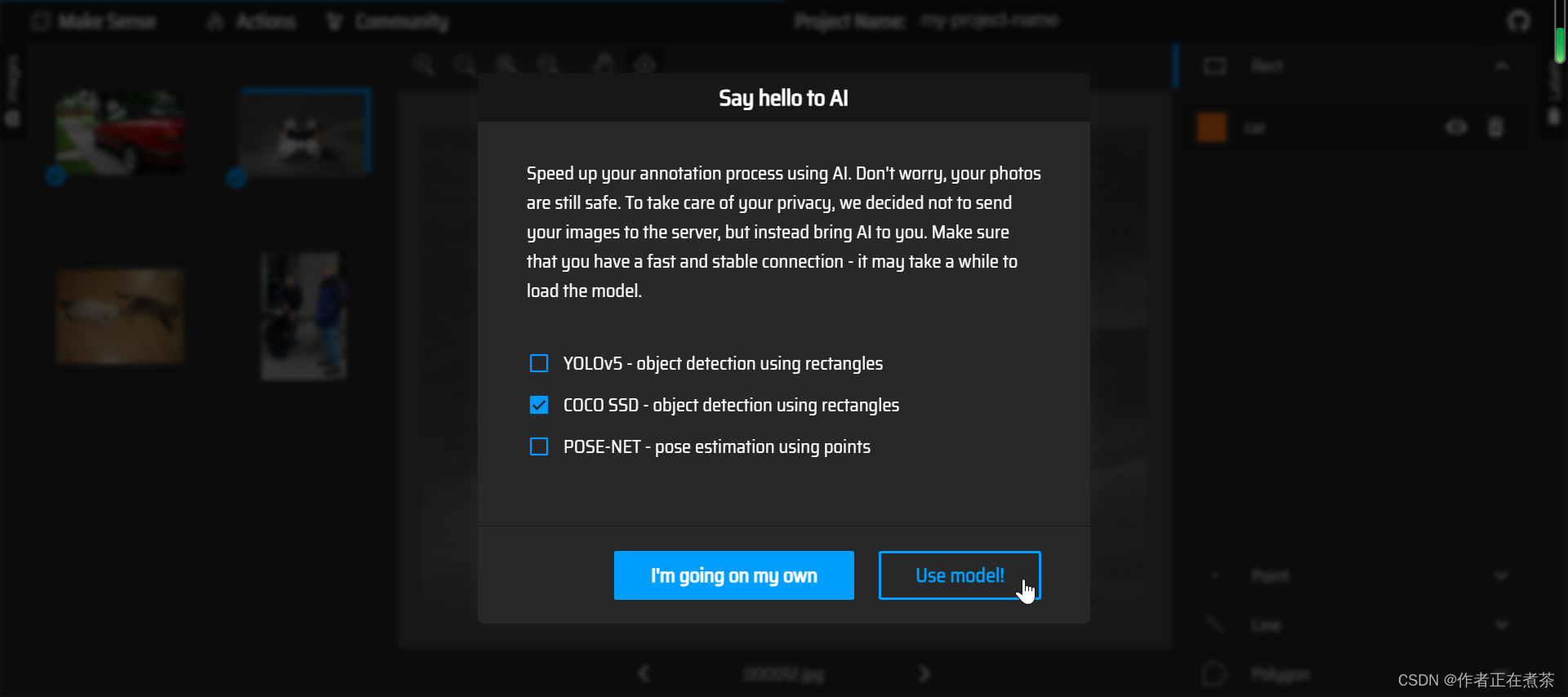
【操作3】对导入的 Images 进行标注,可以手动进行标注,也可以使用已经训练好的模型进行标注。
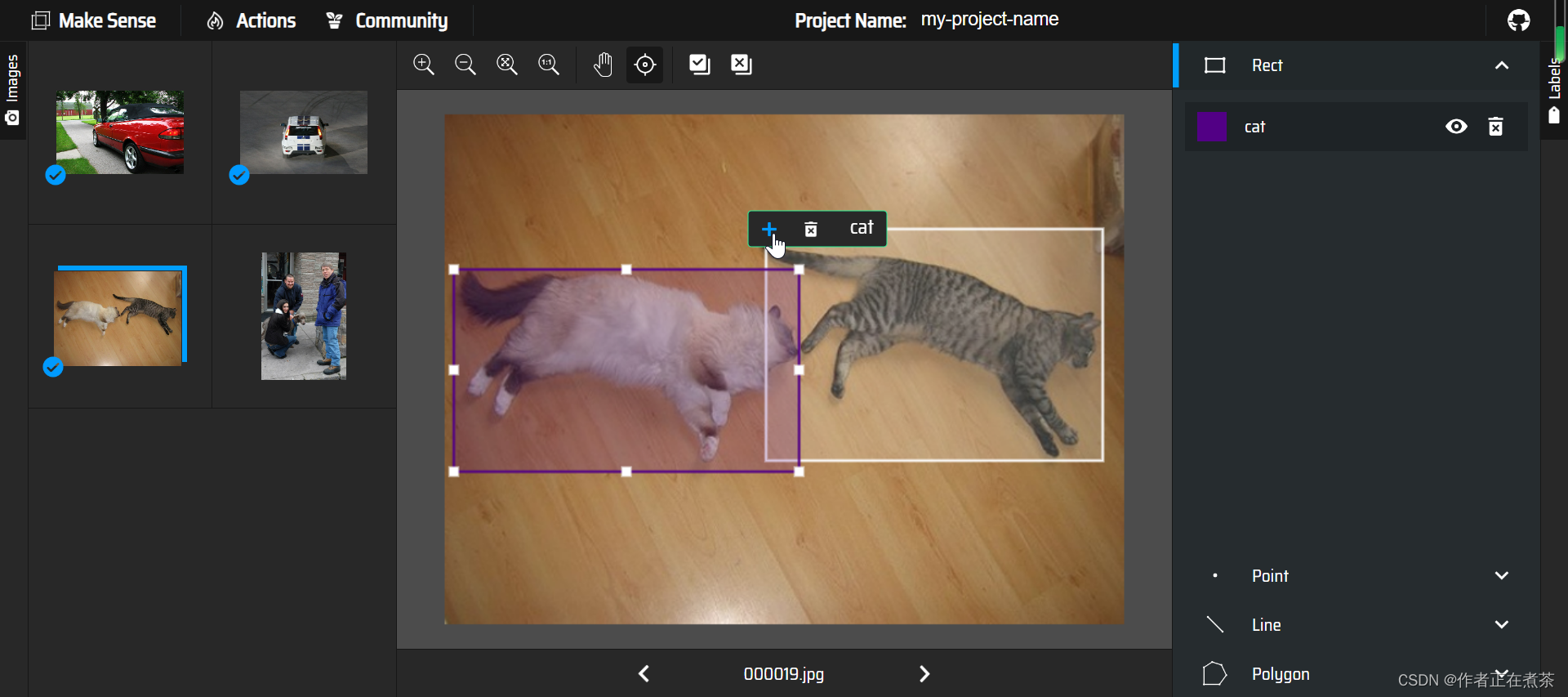
这是使用矩形框进行手动框选和标注:
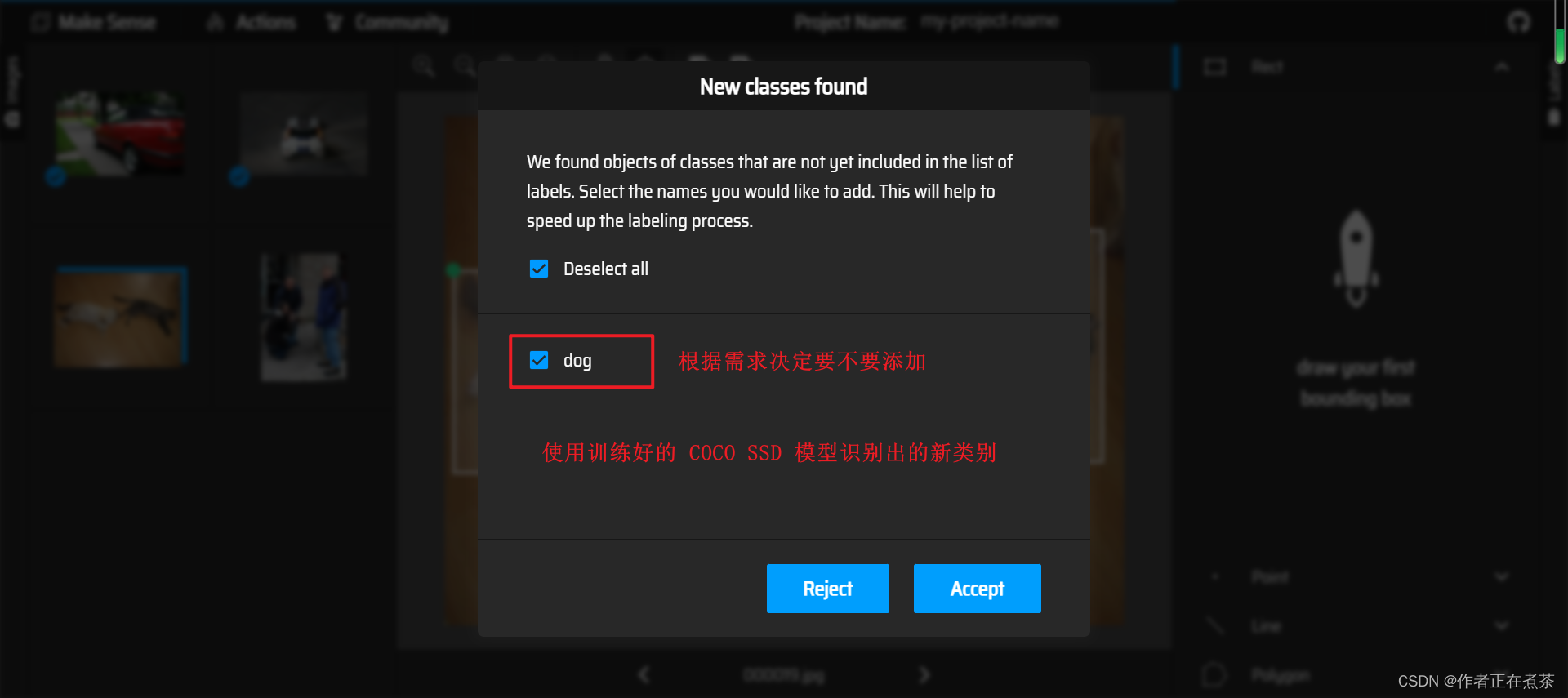
这是使用已经训练好的 COCO SSD 模型进行标注:
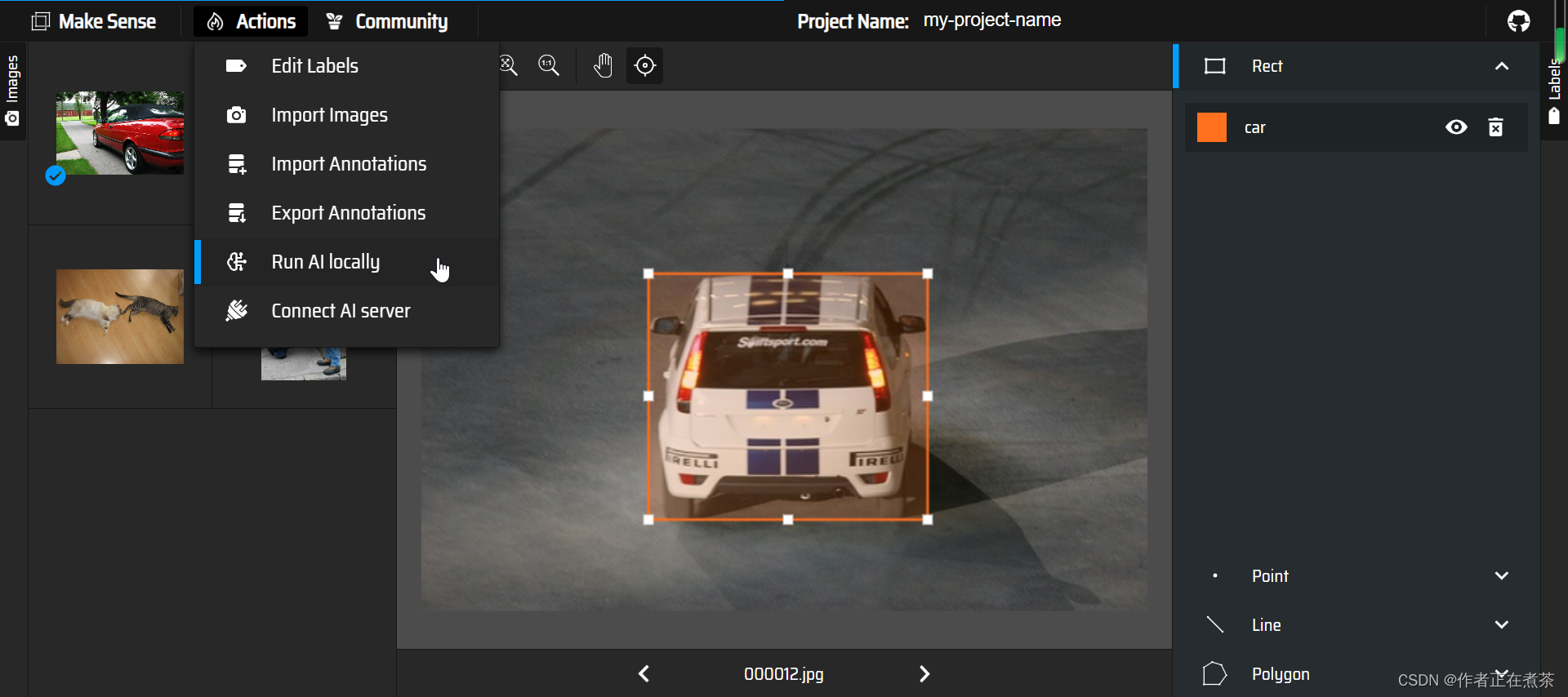
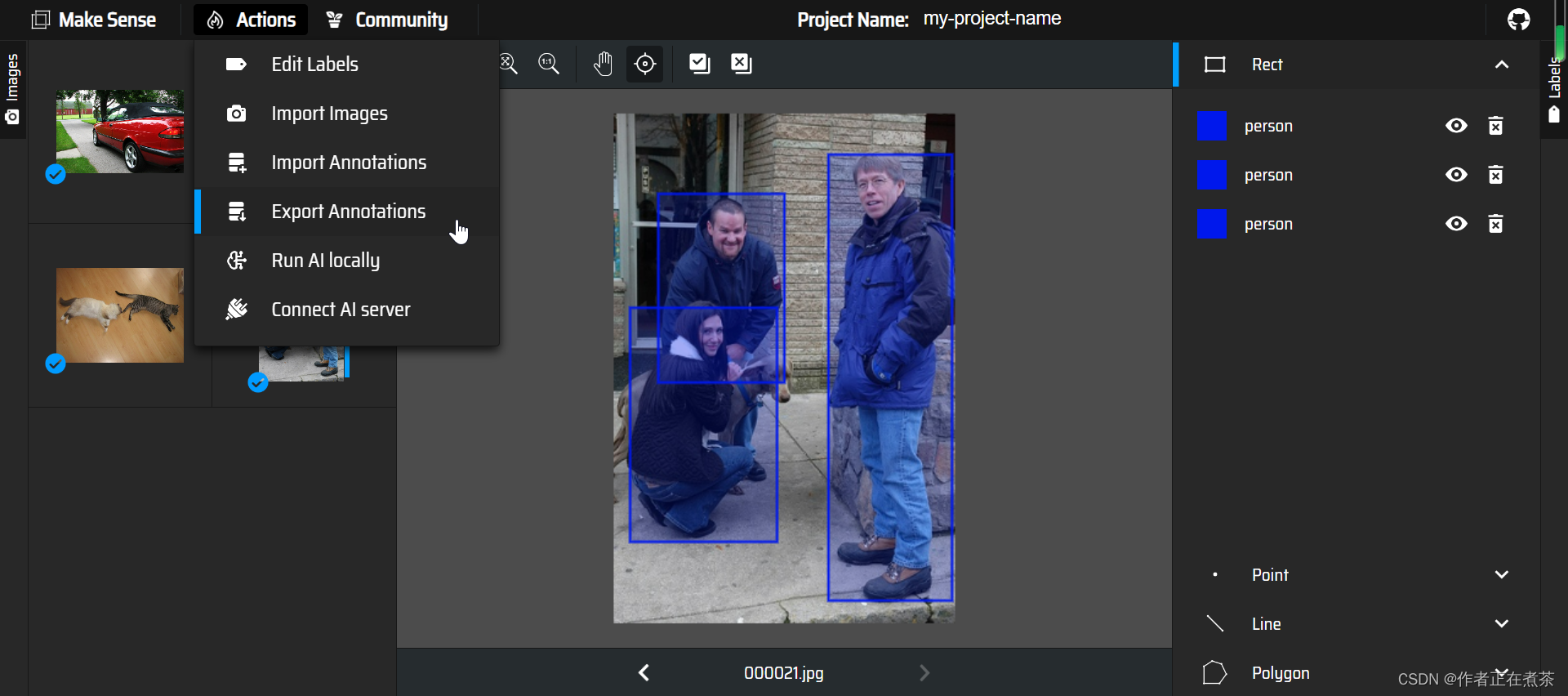
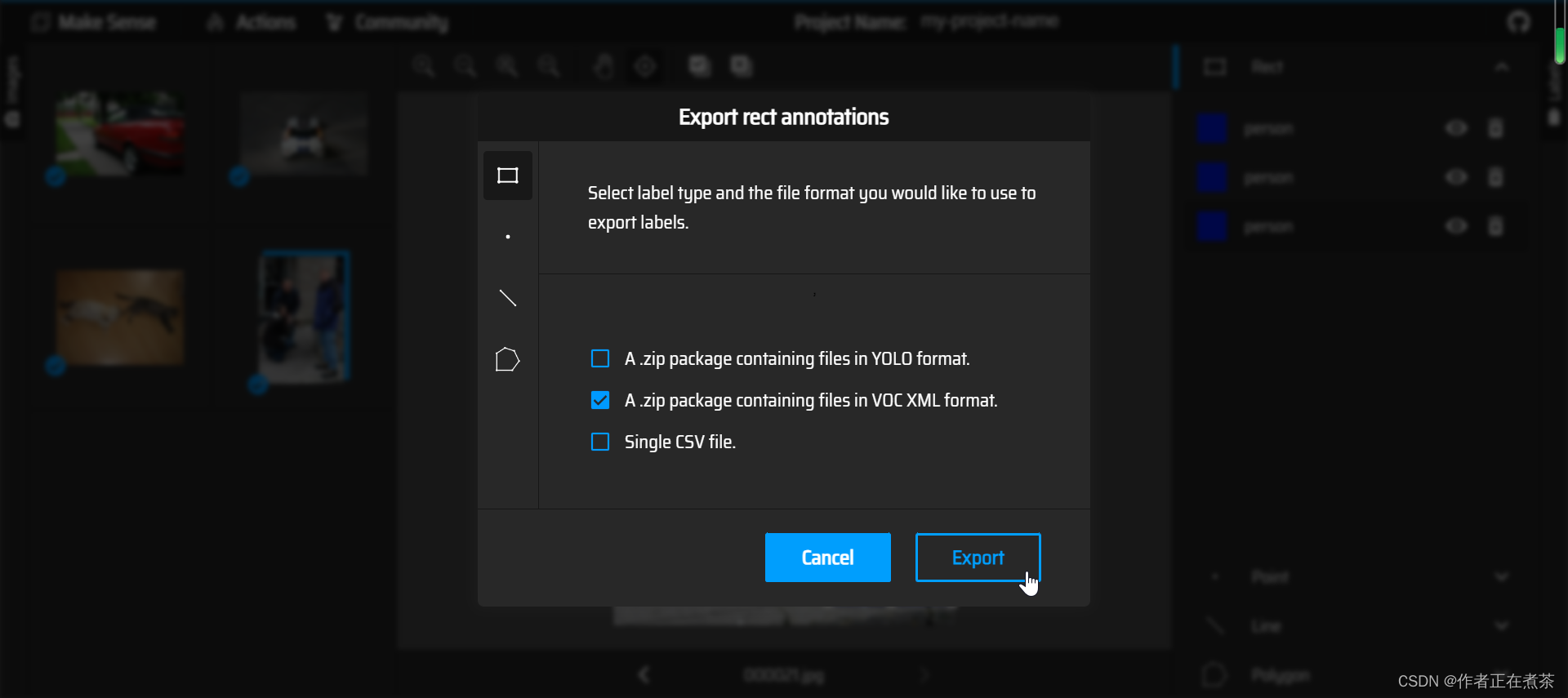
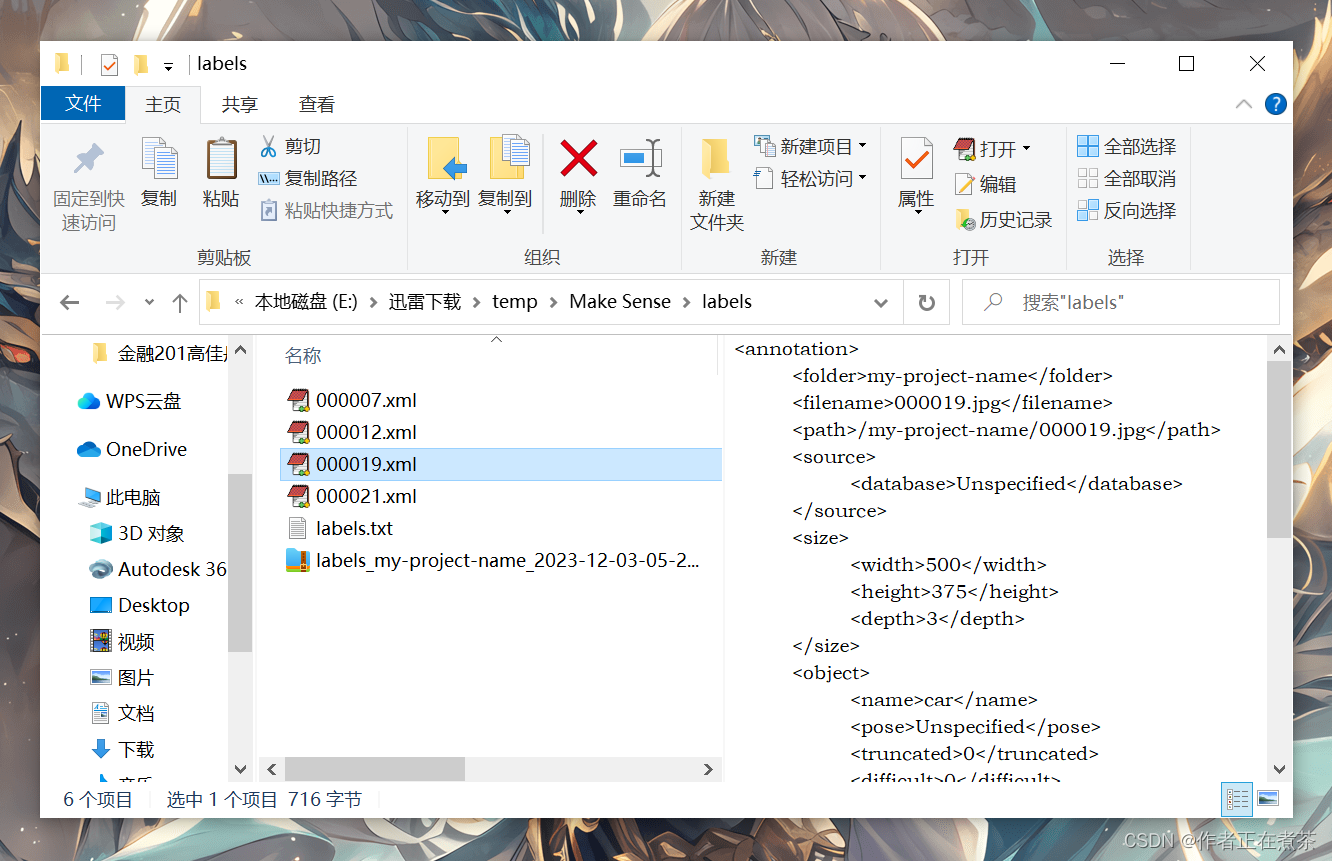
【操作4】将 Images 的标注导出,在 Actions 中选择 Export Annotations ,导出为包含 VOC XML 格式文件的压缩包。
2、CVAT
CVAT 官网:Computer Vision Annotation Tool
【补充】与 Make Sense 官网相比,CVAT 官网更适合团队协作,更适合大型项目。
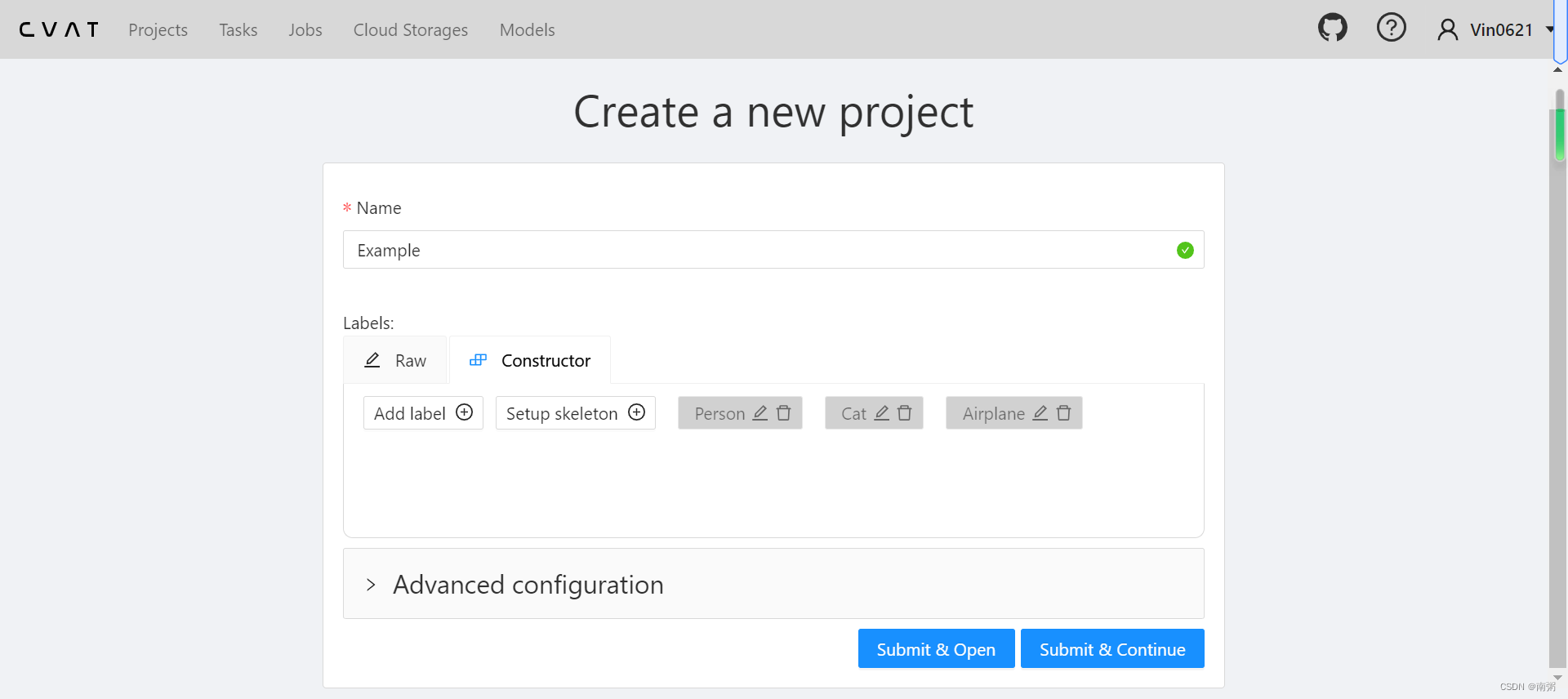
【操作1】在 CVAT 网站创建新项目,命名为 Example ,再添加若干 Label 标签,包括但不限于 Person 、Cat 、Airplane 等。
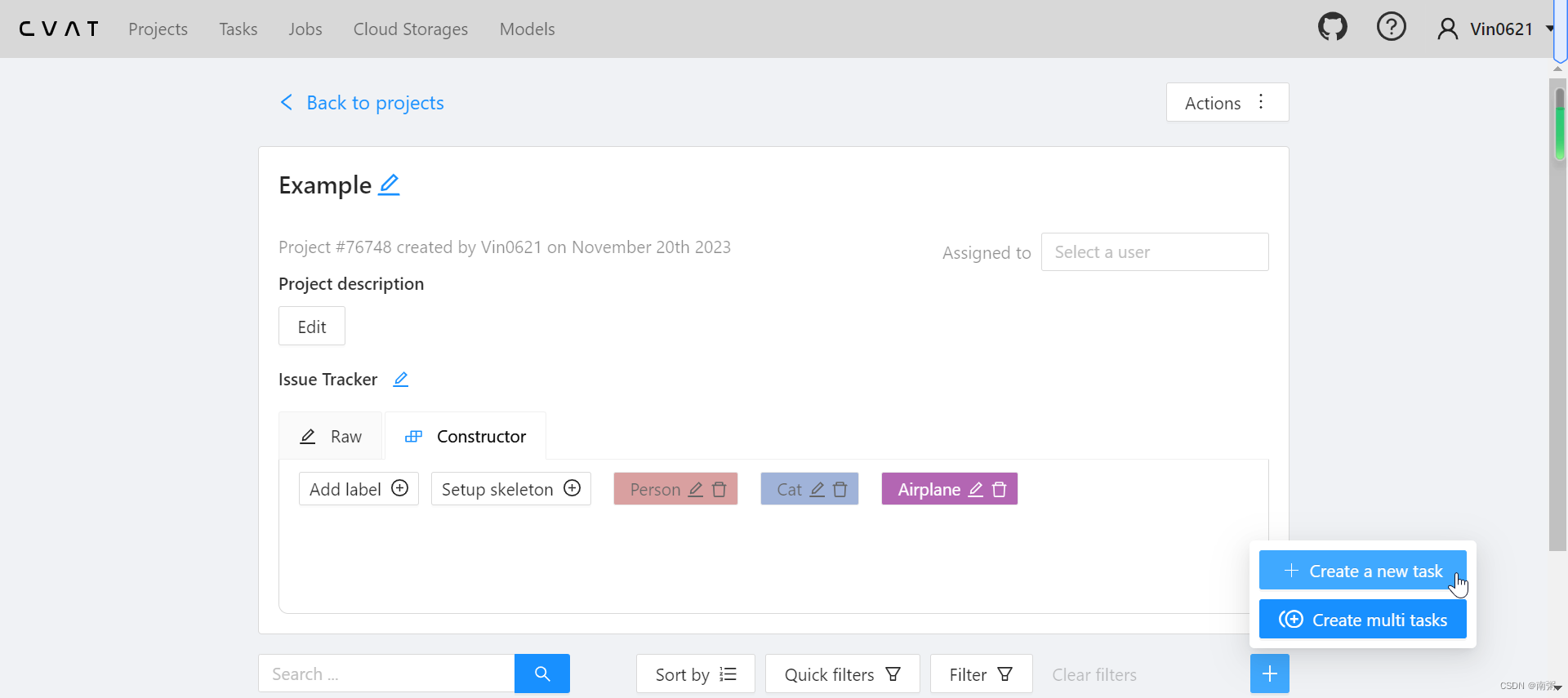
【操作2】在 Example 项目中新建任务,命名为 1-4 ,导入若干图片。
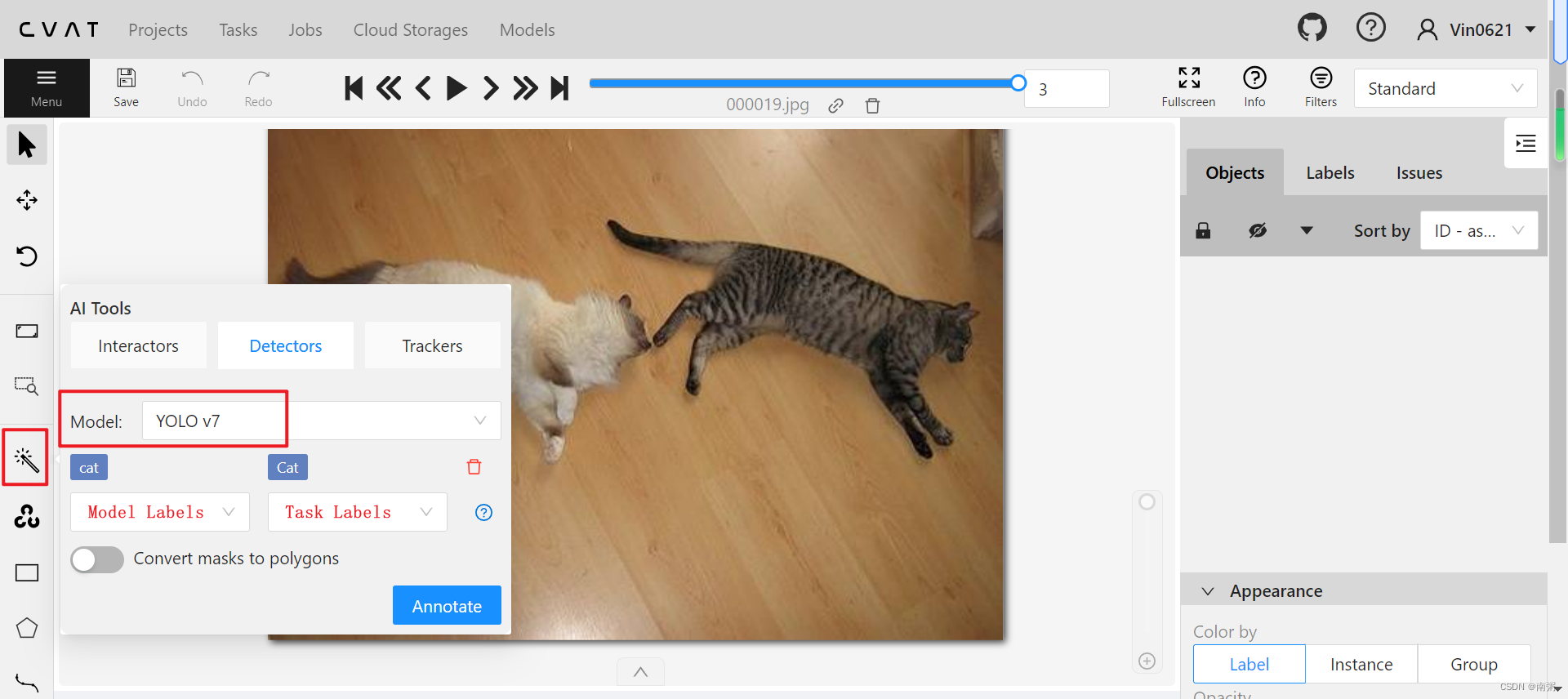
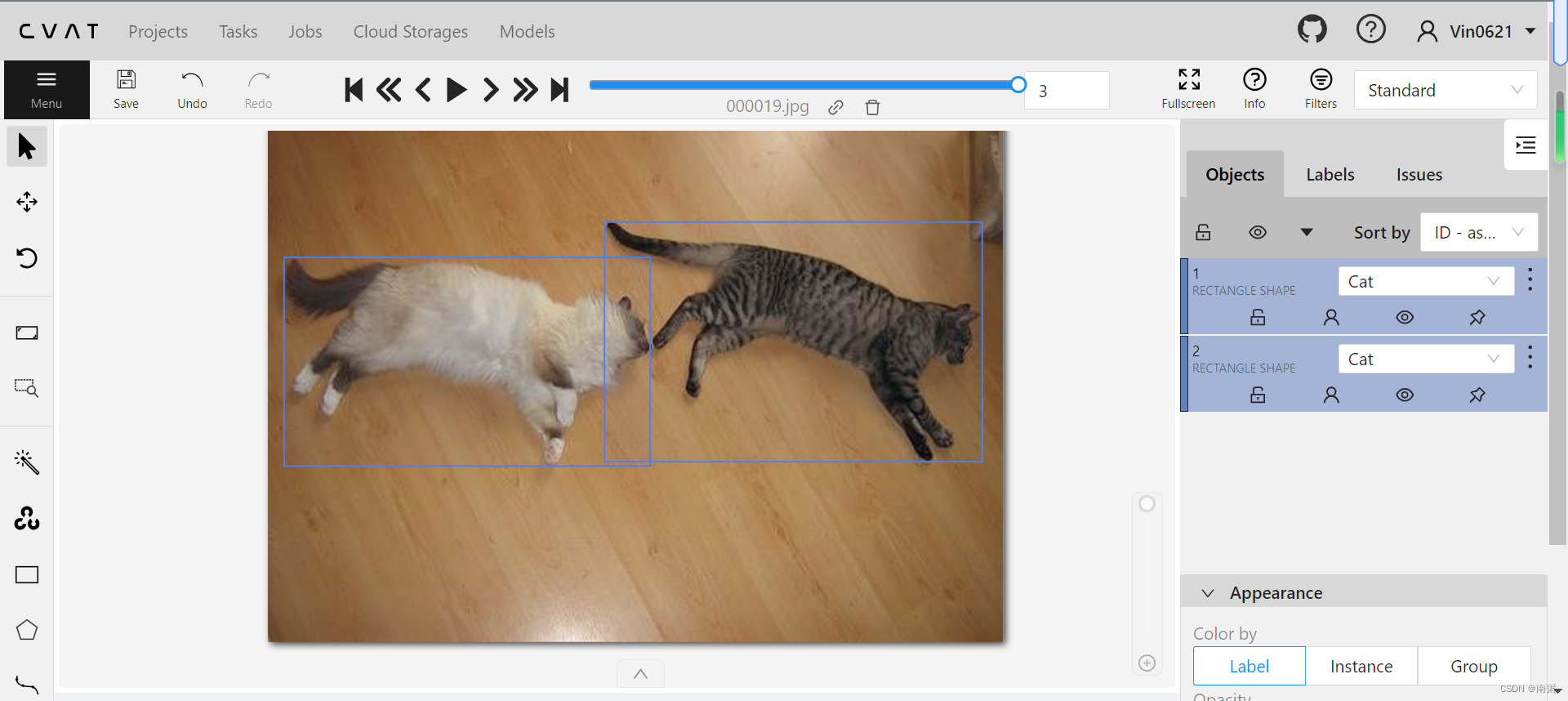
【操作3】在 CVAT 中,我们可以用现成的 Model 对图片进行标注,具体如图所示,我选用的是 YOLO v7 模型,当然,我们也可以手动标注哈!
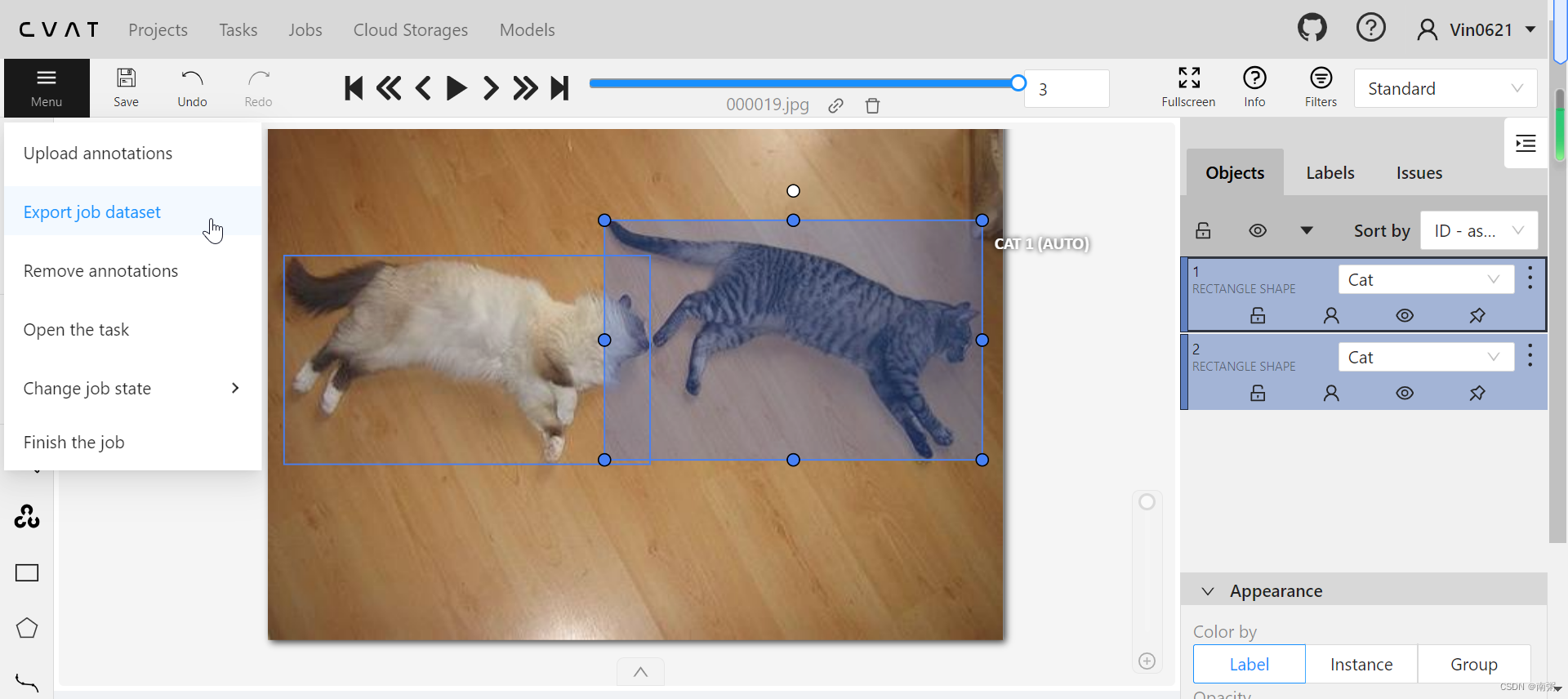
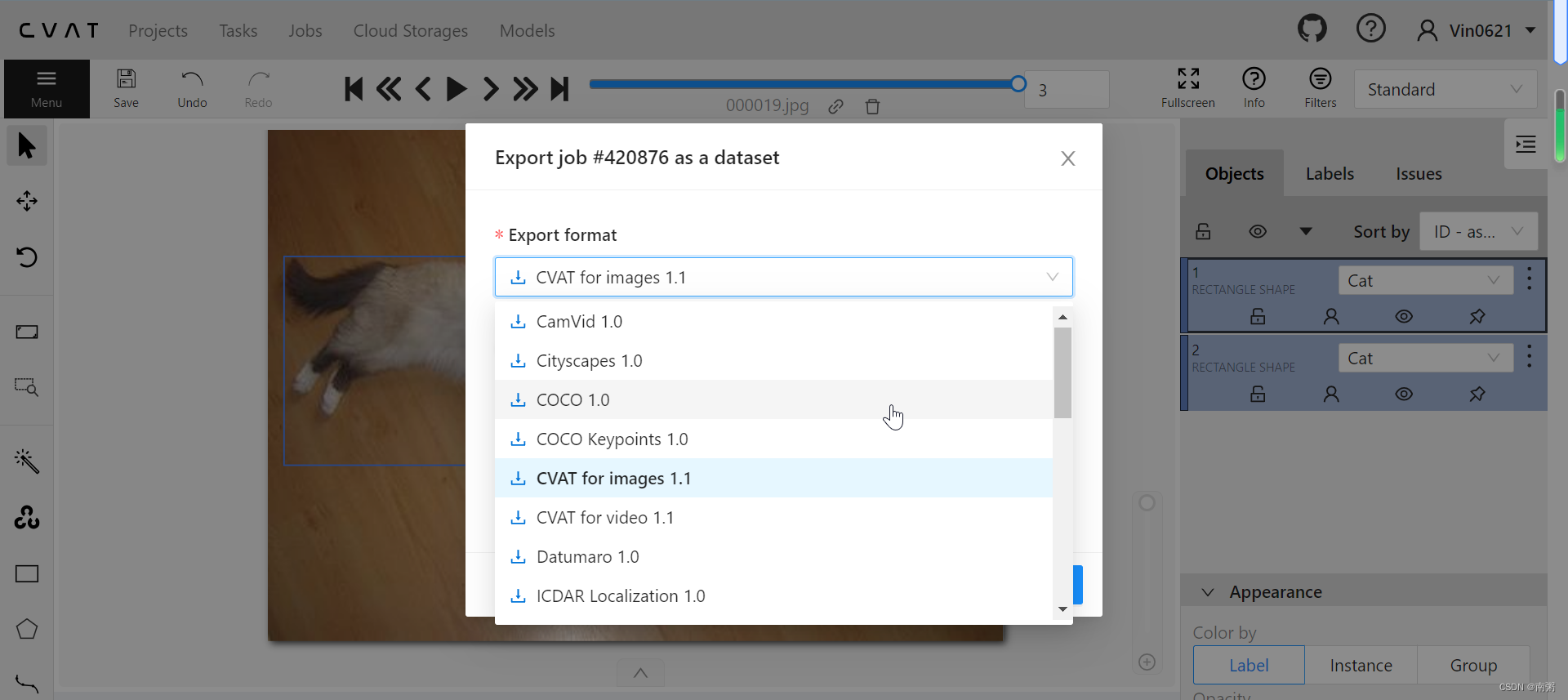
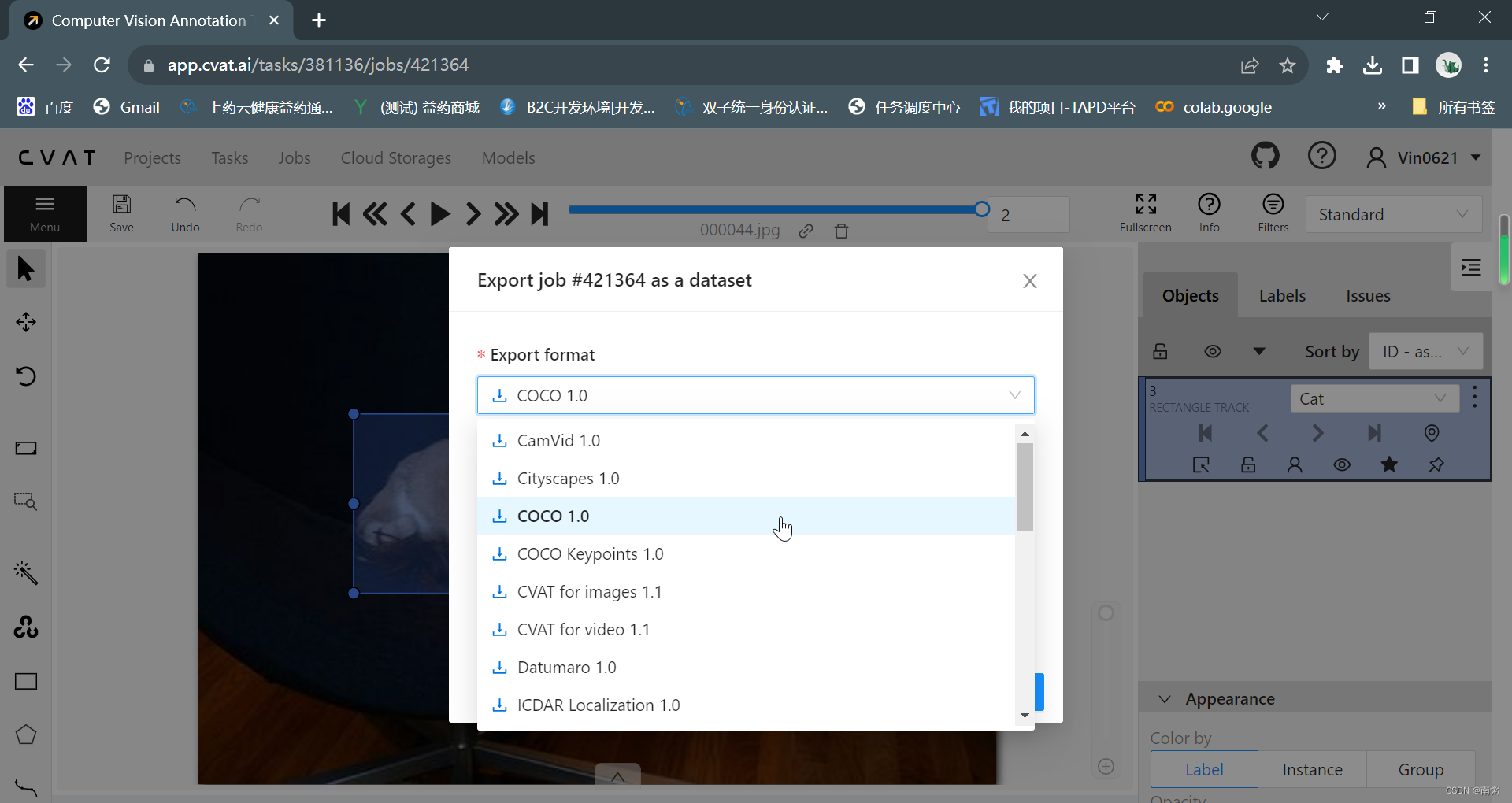
【操作4】在标注玩所有图片后,点击 Menu - Export job dataset 导出 COCO 数据集,这里我们可以看到 CVAT 官网提供导出的数据集类型比较多~
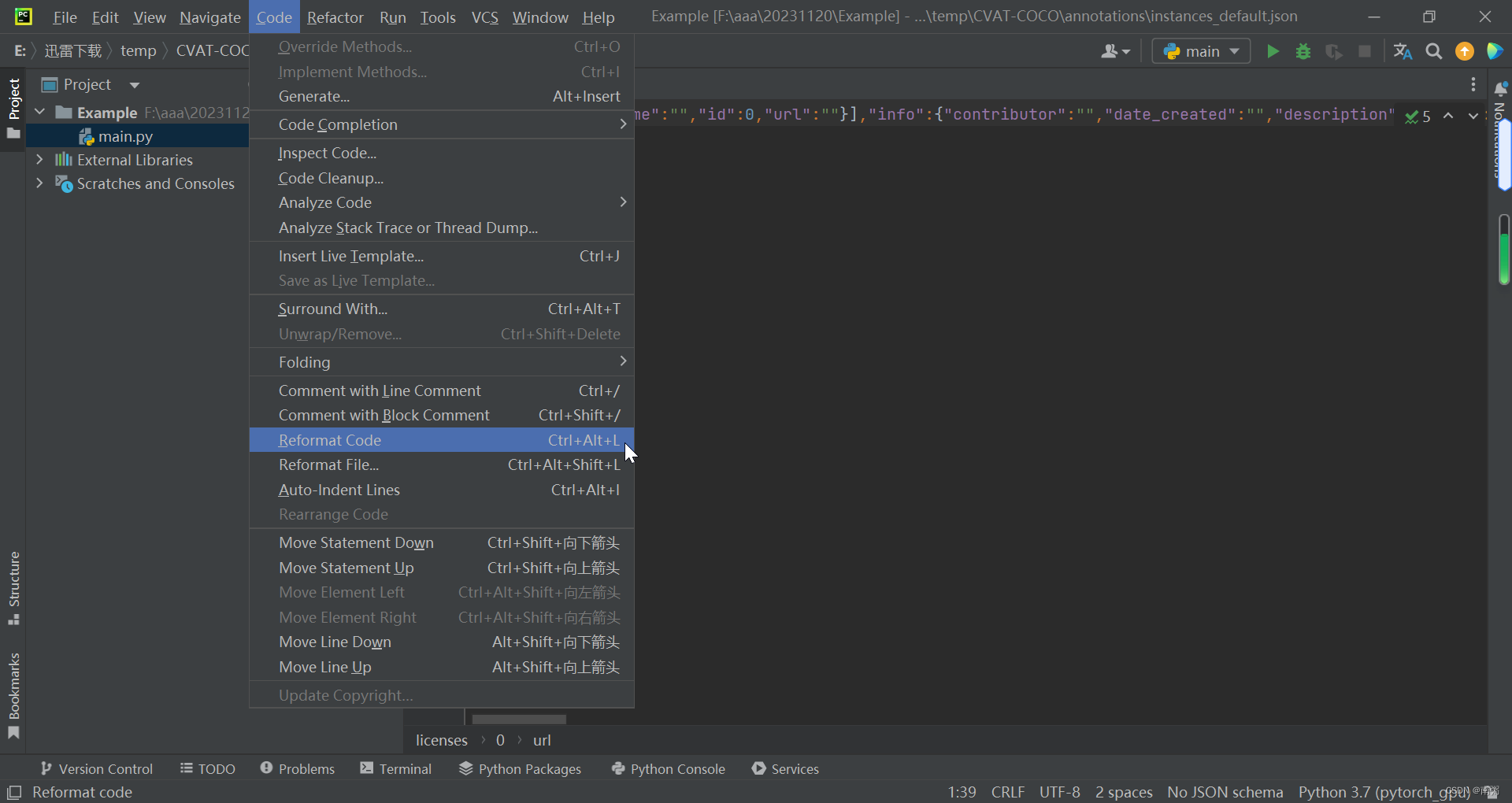
【操作5】在 PyCharm 中打开刚刚导出的 COCO 数据集的 json 文件,点击 Code - Reformat Code 可以规范 json 格式,方便我们查看文件内容。
五、本地标注数据集
1、精灵标注助手
精灵标注助手下载地址:精灵标注助手-人工智能数据集标注工具
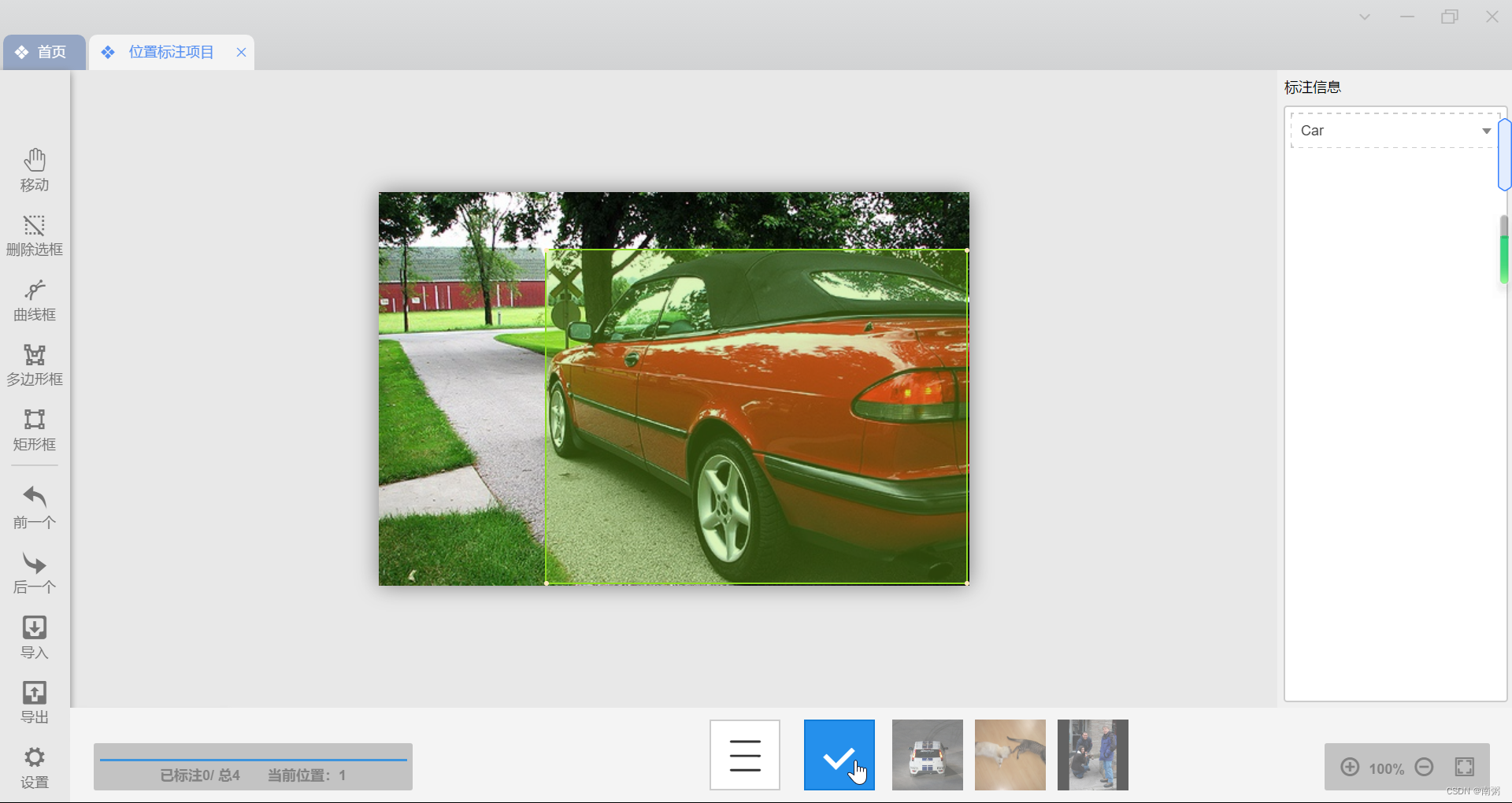
【操作1】点击左侧工具栏的 矩形框 ,对图片进行手动框选,然后在右侧选择标注信息,最后点击底部的 √ 就完成了对该图片的标注。
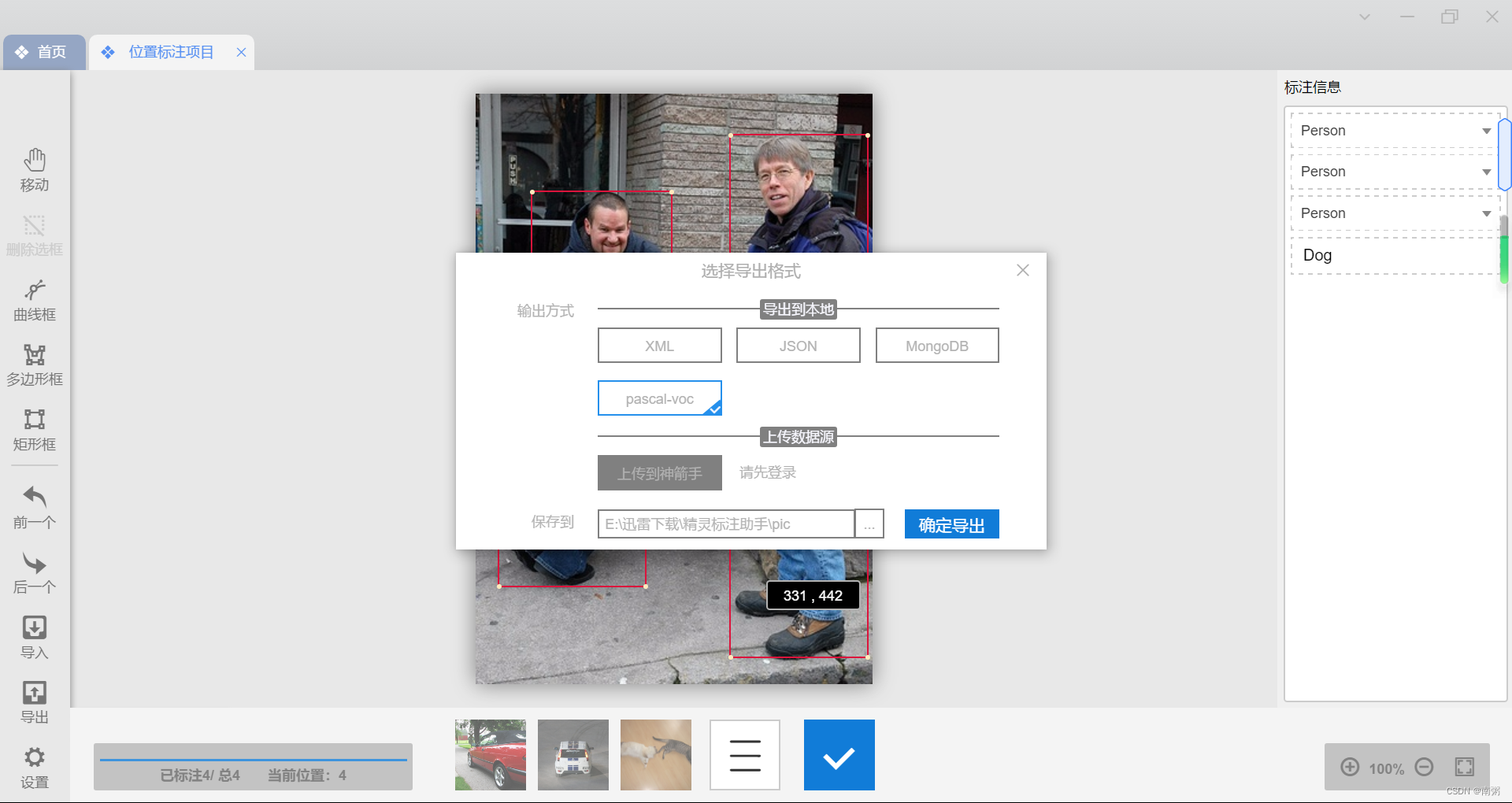
【操作2】 点击左侧的工具栏的 导出 ,选择输出方式为 pascal-voc 导出数据集。
六、论 Python 的元组、字典与数组
在用 PyTorch 加载 COCO 数据集之前,我们需要先来了解一下 Python 的元组、字典与数组,这可以帮助我们更好地看懂【七】【八】的代码。
# 元组 a = (1, 2), a[1] == 1
# 字典 b = {'username': 'Vin', 'sex': 'man', 'age': 23}, b['username'] == 'Vin'
# 数组 c = [1, 2, 3], c[1] == 2a = (1, 2)
b = {'username': 'Vin', 'sex': 'man', 'age': 23}
c = [1, 2, 3]print(a[0]) # [Run] 1
print(b['username']) # [Run] Vin
print(c[1]) # [Run] 2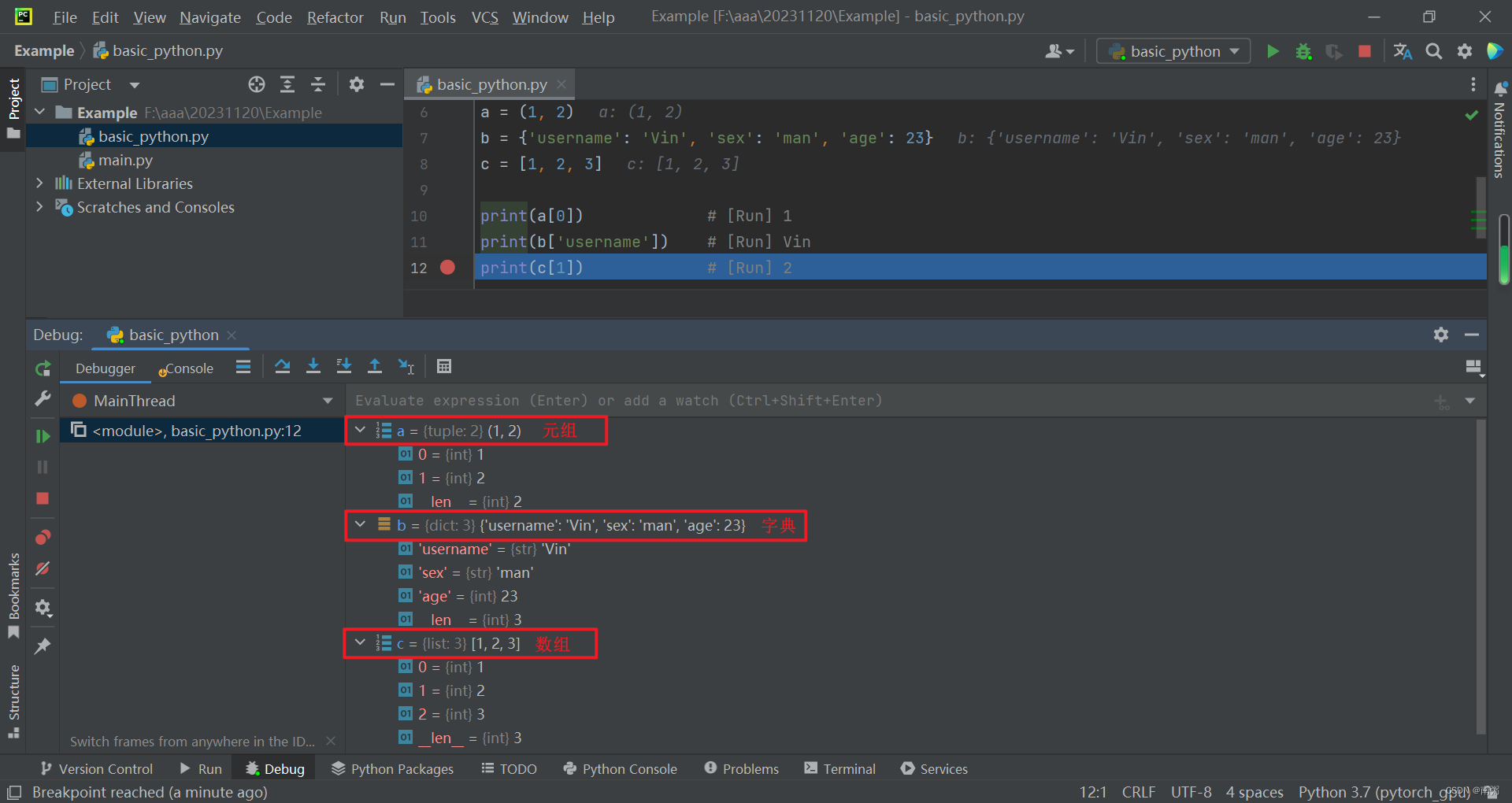
七、用 PyTorch 加载 COCO 数据集
torchvision.datasets.CocoCaptions 官方文档:CocoCaptions — Torchvision 0.16 documentation
torchvision.datasets.CocoDetection 官方文档:CocoDetection — Torchvision 0.16 documentation
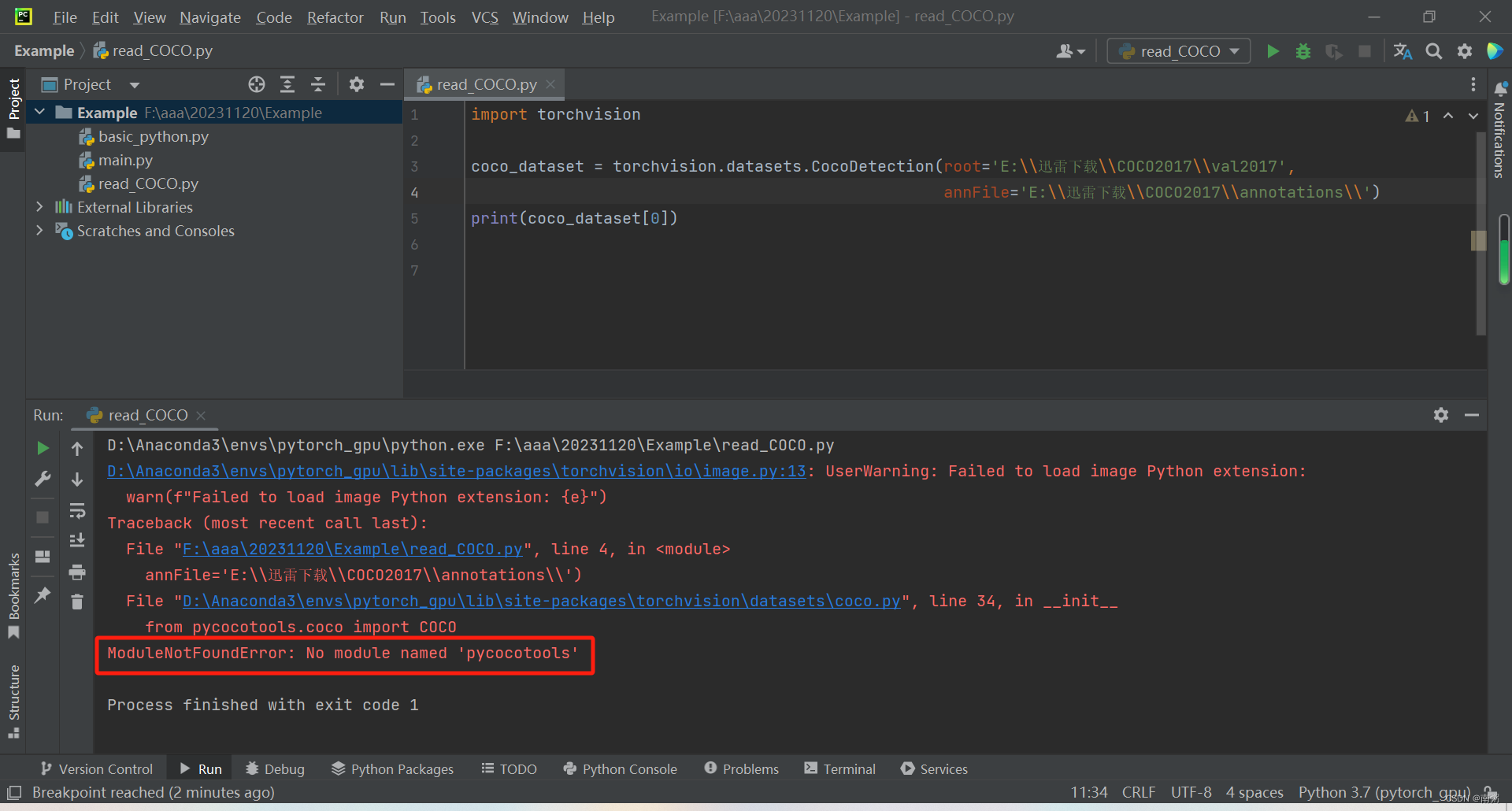
【操作1】如上图所示,在 PyCharm 中,我们用 PyTorch 加载 COCO 数据集前,需要先安装 pycocotools ,具体操作如下:
- 安装 cython :pip install -U cython
- 安装 pycocotools :pip install pycocotools-windows
【操作2】创建 COCO 数据集 coco_dataset ,通过 print 打印可以发现它由两部分构成的元组,第一部分类似于 images ,第二部分类似于 annotations 。

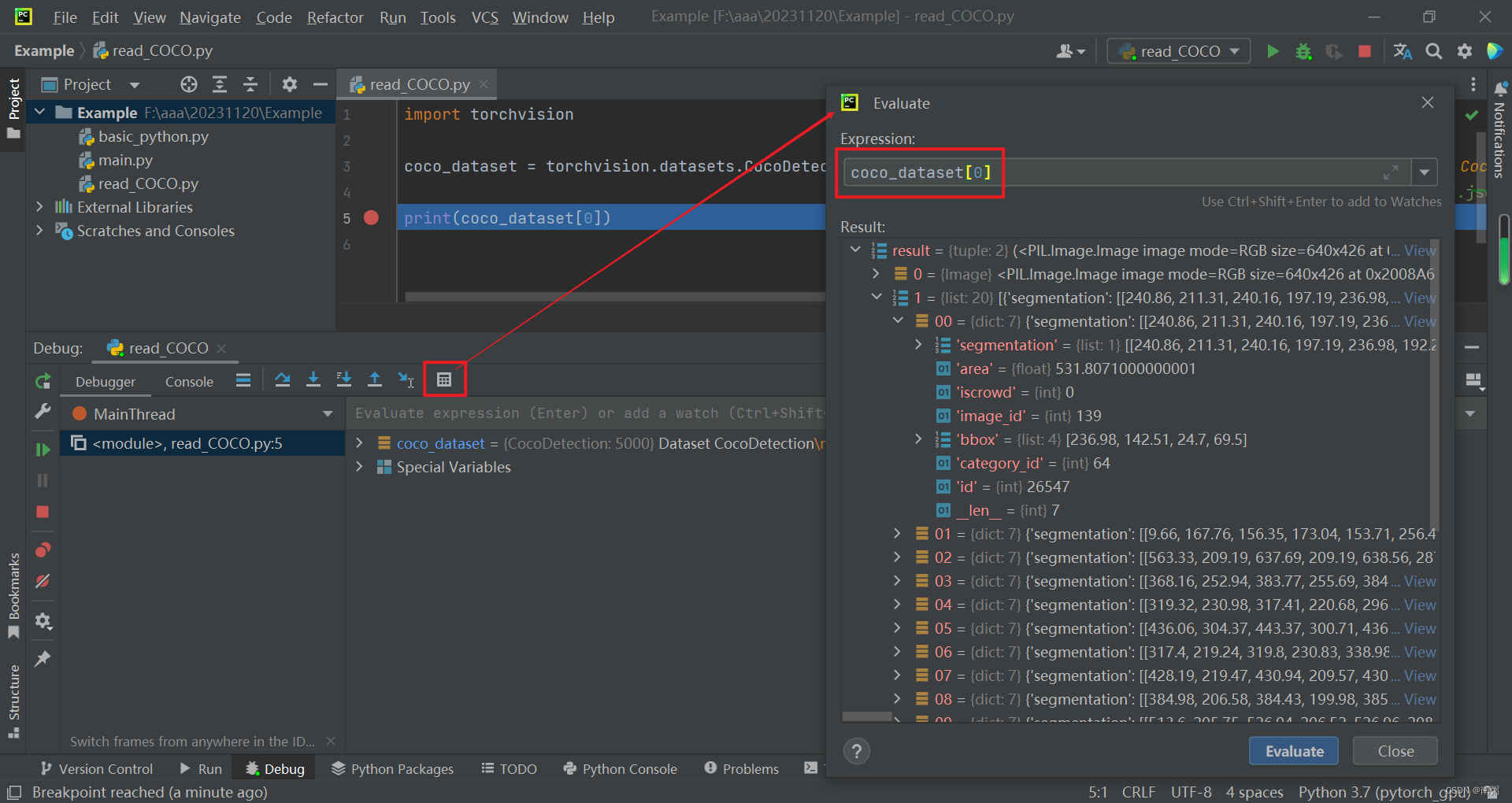
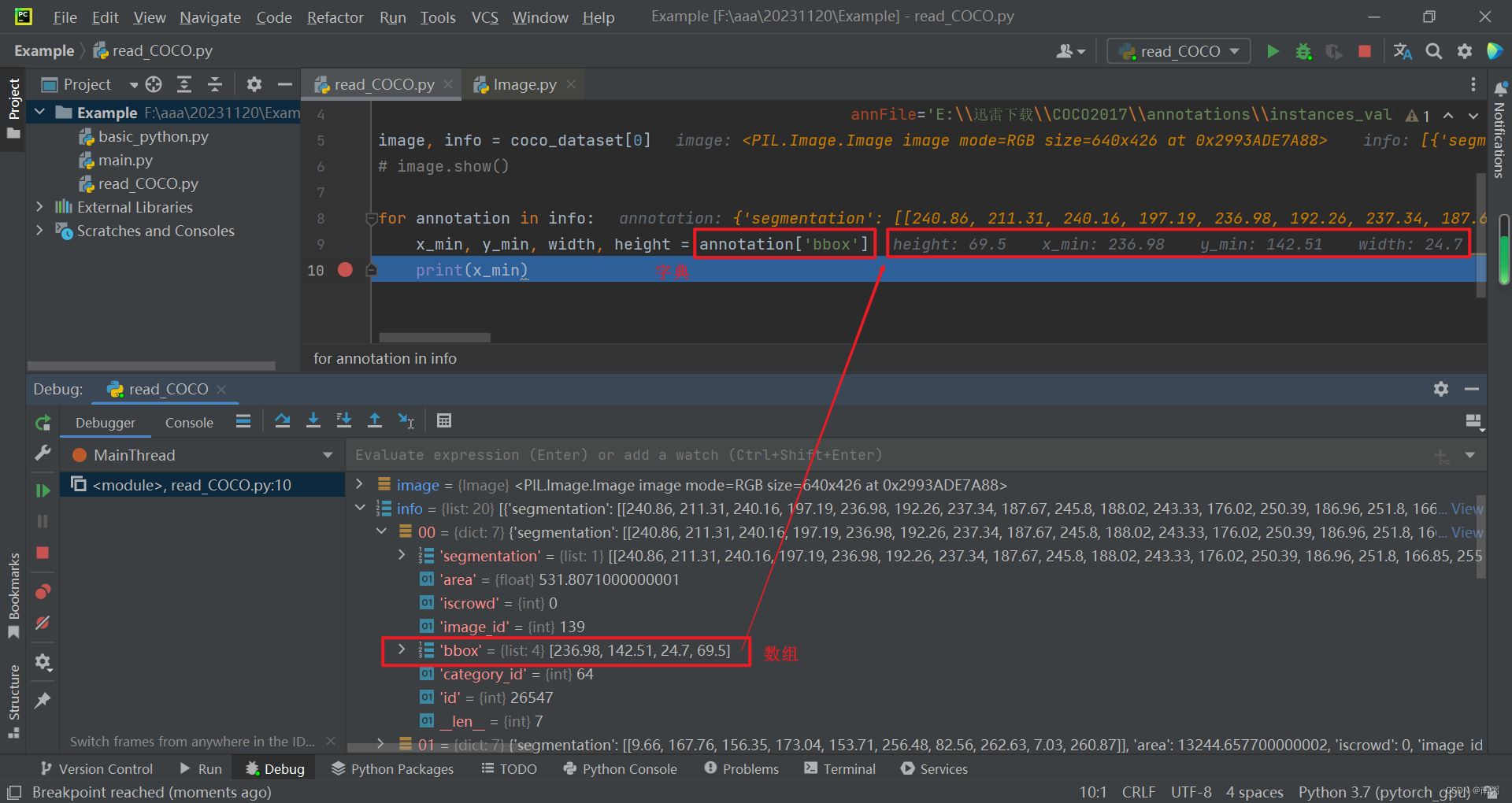
【操作3】对代码进行调试,我们可以借助 Evaluate 工具查看 coco_dataset[0] 的具体结构,不难发现其第二部分是由多个字典构成的,重点关注 bbox 。
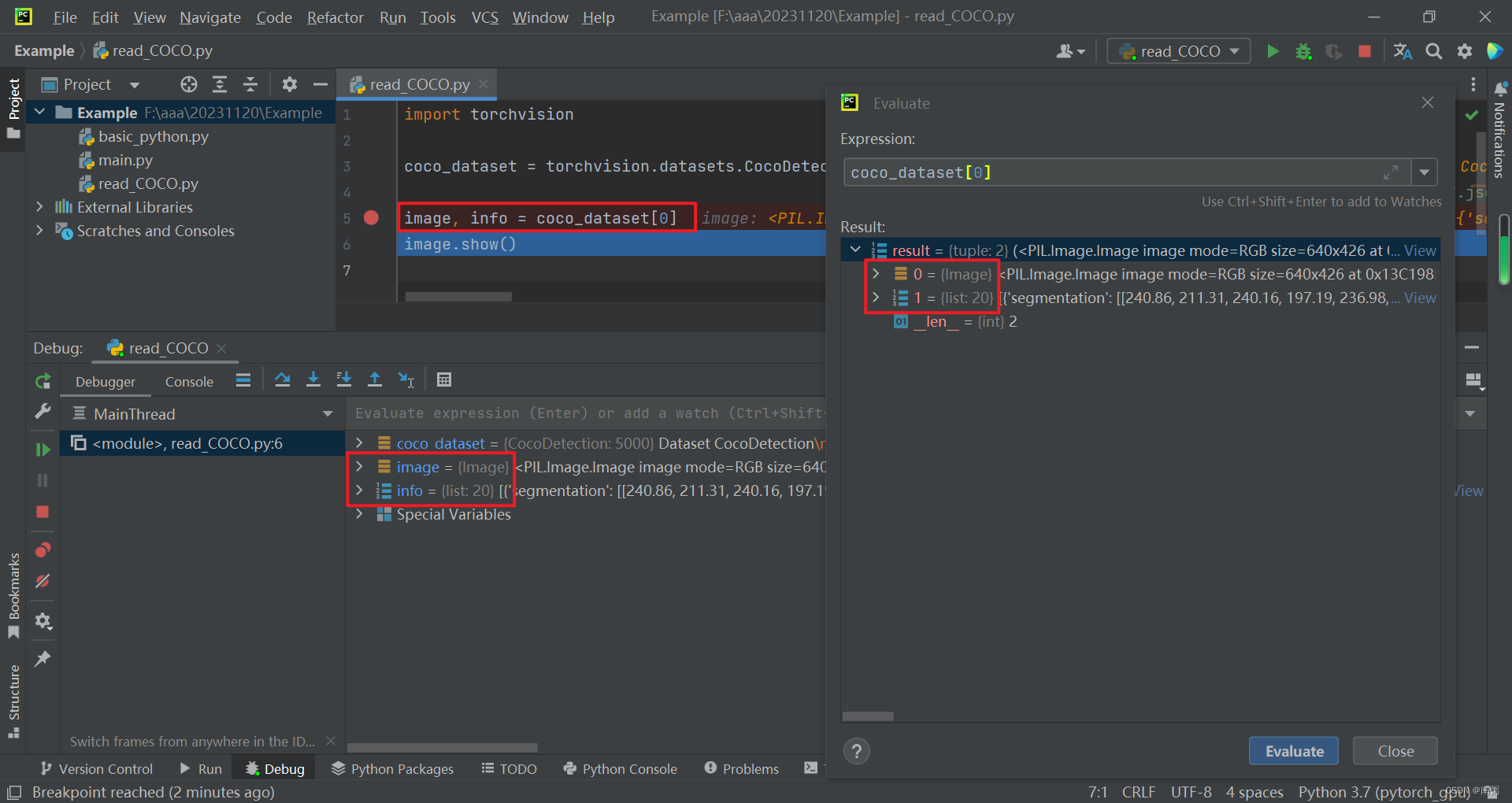
【操作4】在上面的基础上,我们将 coco_dataset[0] 元组的两部分分别赋给 image 和 info 。
【操作5】遍历 info 依次取出各个 annotation ,将 annotation 字典中 bbox 的对应值分别赋给 左上角 和 右下角 的点坐标,以确定图中 标注框 的位置。
【完整代码】
import torchvision
from PIL import ImageDrawcoco_dataset = torchvision.datasets.CocoDetection(root='E:\\迅雷下载\\COCO2017\\val2017',annFile='E:\\迅雷下载\\COCO2017\\annotations\\instances_val2017.json')
image, info = coco_dataset[0]
# image.show()image_handler = ImageDraw.ImageDraw(image)for annotation in info:x_min, y_min, width, height = annotation['bbox']color = (255, 255, 255)image_handler.rectangle((x_min, y_min, x_min + width, y_min + height), outline=color)image.show()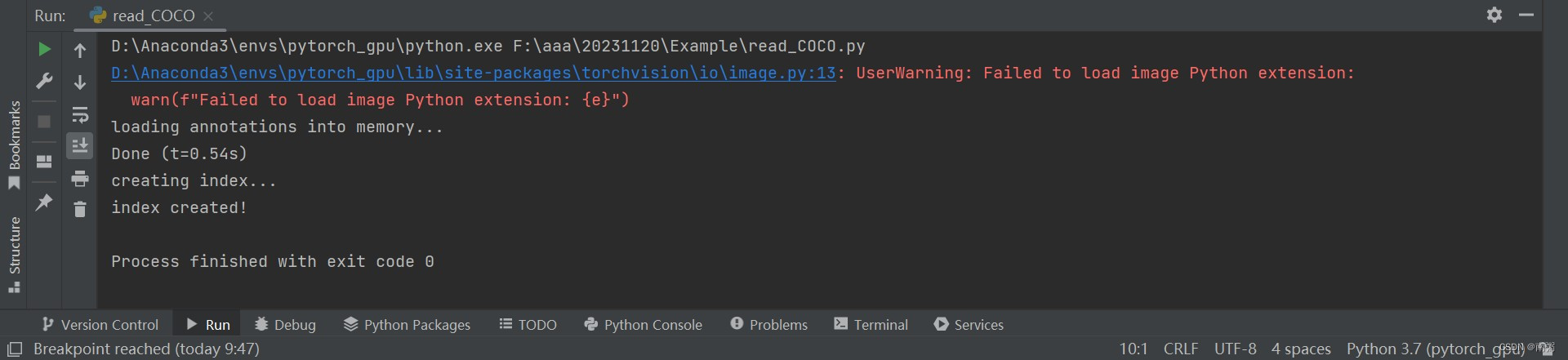

八、用 PyTorch 读取自己的 COCO 数据集
【说明】在这个环节,我们需要先借助在线标注数据集的网站,如 Make Sense 或 CVAT ,导入图片,进行矩形框框选,最后导出自己的 COCO 数据集。
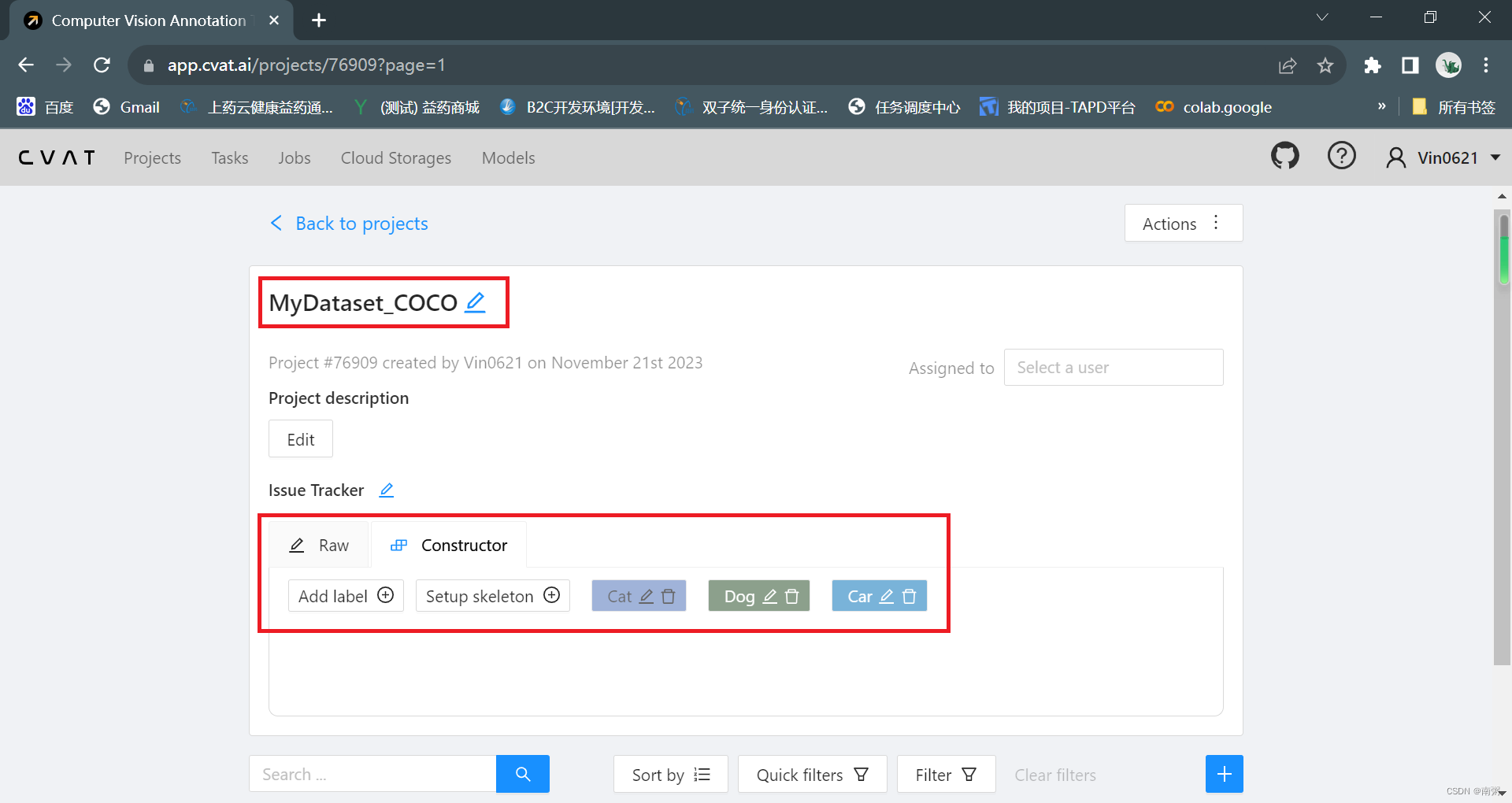
【操作1】在 CVAT 网站创建新项目,命名为 MyDataset_COCO ,再添加若干 Label 标签,包括但不限于 Cat 、Dog、Car 等。
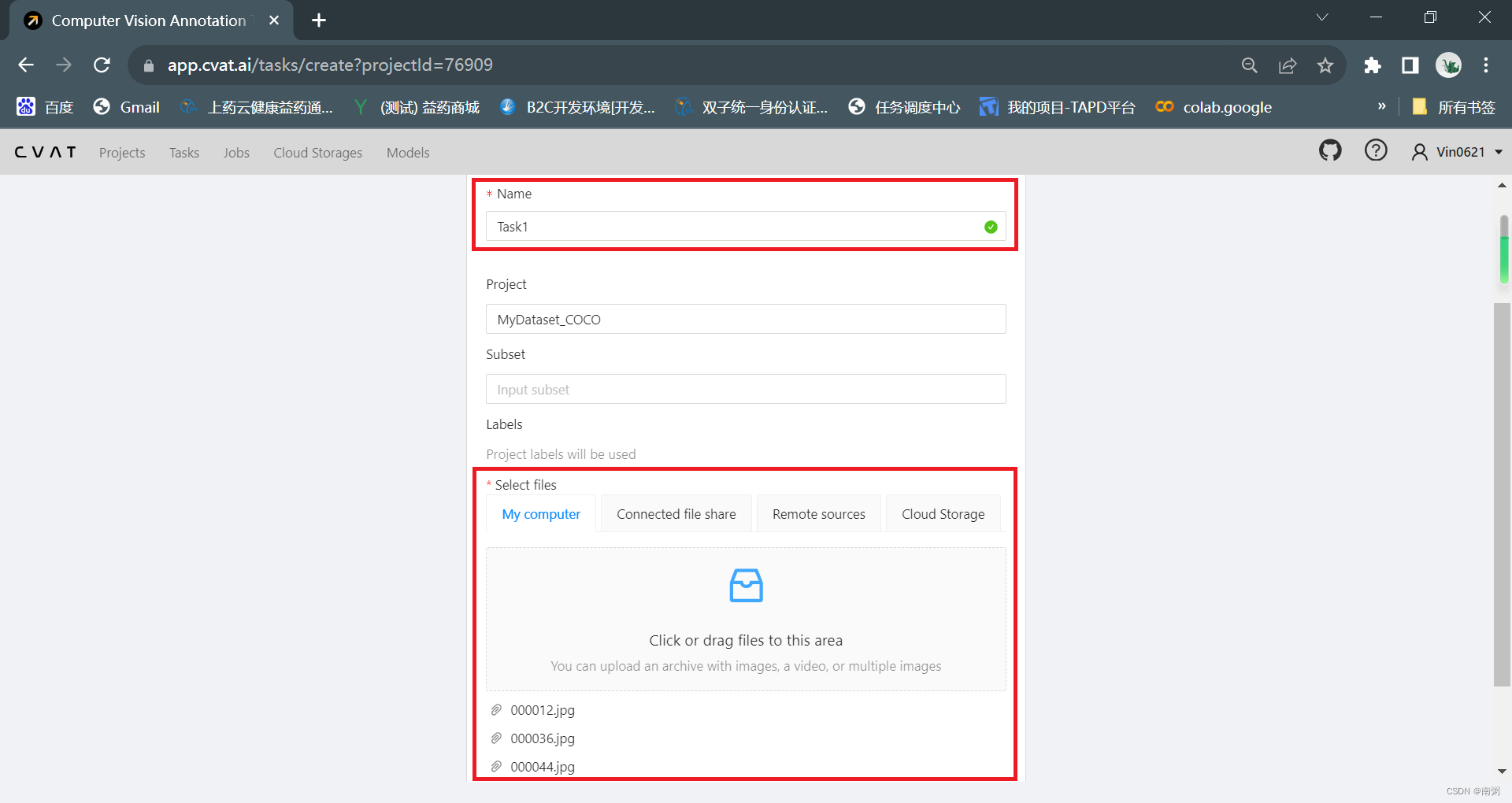
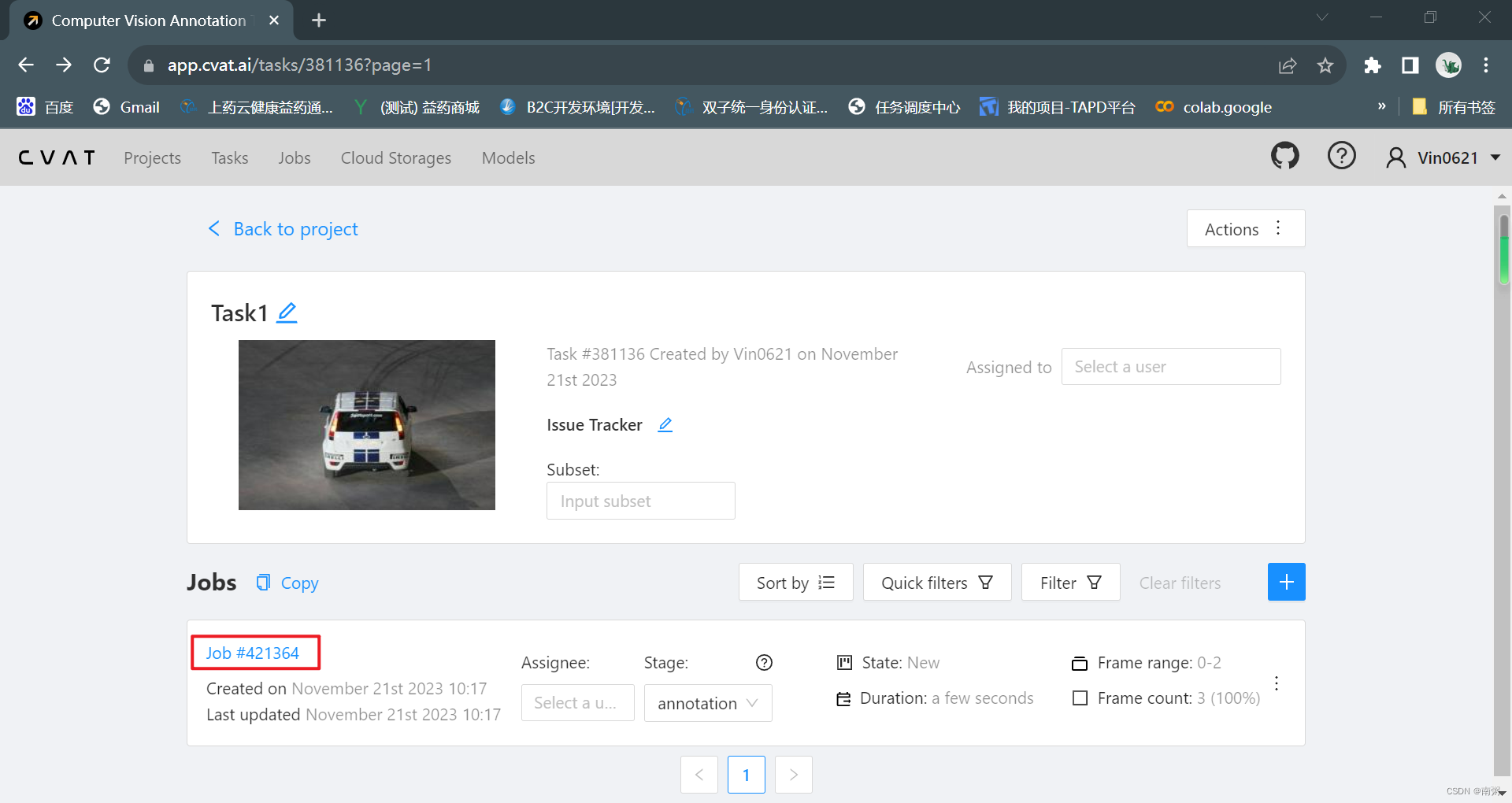
【操作2】在 MyDataset_COCO 项目中新建任务,命名为 Task1,导入若干图片。
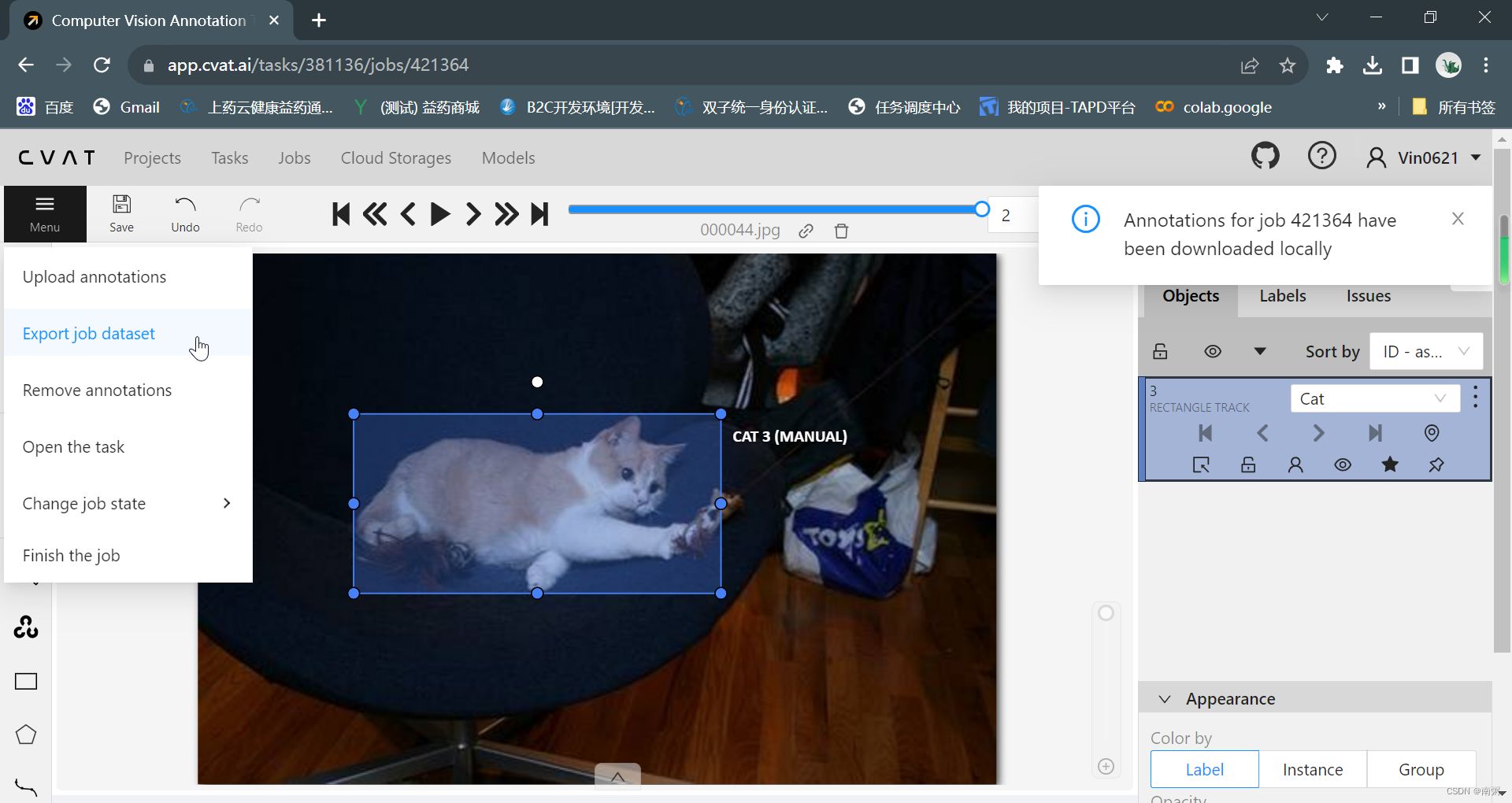
【操作3】 在 Task1 任务页面,点击对应的 Job 进入工作页面,对导入的图片依次进行手动标注,最后导出为 COCO 数据集。
【操作4】在 PyCharm 中编写相关代码,用 PyTorch 读取自己的 COCO 数据集,其实就是在【六】的基础上改了文件的路径。
import torchvision
from PIL import ImageDrawcoco_dataset = torchvision.datasets.CocoDetection(root='E:\\迅雷下载\\temp\\CVAT-COCO\\pic',annFile='E:\\迅雷下载\\temp\\CVAT-COCO\\annotations\\mydataset_coco.json')
image, info = coco_dataset[2]
# image.show()image_handler = ImageDraw.ImageDraw(image)for annotation in info:x_min, y_min, width, height = annotation['bbox']color = (255, 255, 255)image_handler.rectangle((x_min, y_min, x_min + width, y_min + height), outline=color)image.show()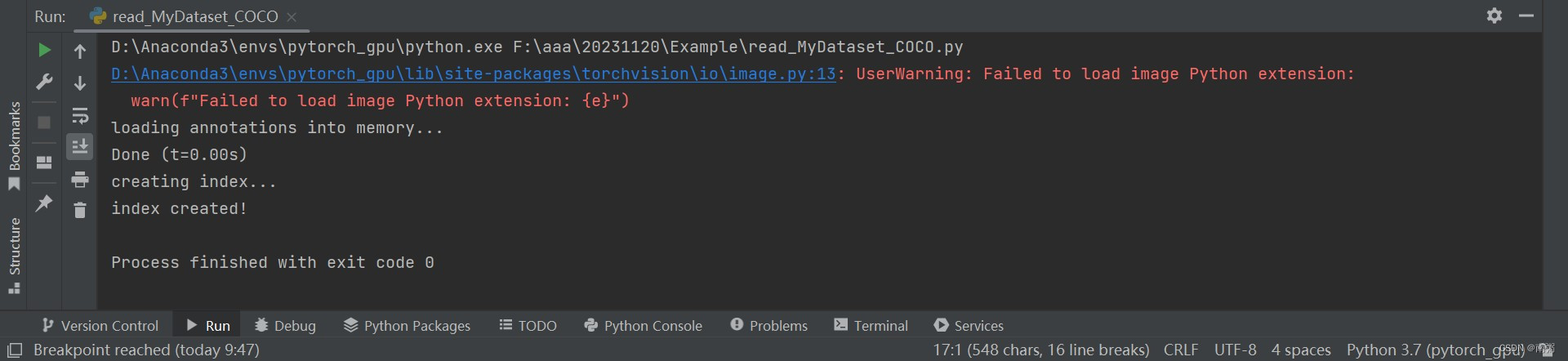

这篇关于【土堆】目标检测の入门实战——手把手教你使用 Make Sense 和 CVAT 在线标注 VOC 数据集与 COCO 数据集 用 PyTorch 读取自制 COCO 数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




