本文主要是介绍中科院计算所:什么情况下,大模型才需要检索增强?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGPT等大型语言模型在自然语言处理领域表现出色。但有时候会表现得过于自信,对于无法回答的事实问题,也能编出一个像样的答案来。
这类胡说乱说的答案对于医疗等安全关键的领域来说,是致命的。

为了弥补这一缺陷,研究者们提出了检索增强技术,通过引入外部知识源来减少模型的错误信息。然而,频繁的检索不仅增加开销,还可能引入不准确或误导性的信息。
因此,检索的时机就变得很重要了。如果仅在LLMs对问题感到不确定时进行检索检索,将大大提高效率。
但是新问题又来了,如何让过度自信的LLMs诚实的表达出“我不知道”呢?
中科院计算所的研究团队对此进行了深入研究,定量评估了大型语言模型对知识边界的感知能力,并发现它们确实存在过度自信的问题。团队进一步探讨了模型对问题确定性与外部检索信息依赖之间的关系,并提出了几种创新方法来增强模型对知识边界的感知,从而减少过度自信。
这些方法不仅有助于提升模型的性能,还能在减少检索调用次数的同时,实现与传统检索增强相当甚至更好的效果。
论文标题:
When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’ Overconfidence Helps Retrieval Augmentation
公众号「夕小瑶科技说」后台回复“When”获取论文PDF!
1. 衡量模型的自信程度
任务定义
开放领域问答
对于给定问题 和一个包含大量文档的集合,本文要求LLMs根据语料库提供问题的答案,而且通过提示 输出关于答案的确定性 ,这可以描述如下:
![]()
当时, 表示模型认为答案是正确的, 而则意味着相反。
检索文档增强LLMs
从语料库中为给定问题检索一组相关文档,利用这些文档来增强LLMs的知识,表示为:
![]()
利用LLMs的置信度来指导何时进行检索。其格式为:
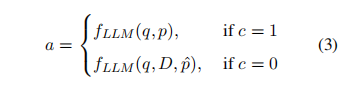
实验设置
数据集
在两个挑战性的开放领域问答基准数据集——自然问题(NQ)和HotpotQA上进行了实验。NQ数据集基于谷歌搜索查询构建,包含带注释的简短和长篇答案;HotpotQA则需要多跳推理,数据由亚马逊 Mechanical Turk 收集。由于HotpotQA难度较高,其检索增强需求可能与NQ不同。实验聚焦于NQ测试集和HotpotQA开发集,仅采用带简短答案的问题,并将这些答案作为标签。
评估了五个代表性模型:两个开源模型(Vicuna-v1.5-7B和LLaMA2-Chat7B)及三个黑盒模型(GPT-Instruct、ChatGPT和GPT-4)。
对黑盒模型,限制最大输出长度为256个标记,其他参数设为默认值。对开源模型,为求稳定结果,将温度参数设为0。
指标
本文使用准确性来评估问答性能,若回答与基准答案相符,则视为正确。同时,通过不确定响应的比例(简称Unc-rate)来衡量模型的信心水平,比例较低表示模型信心较高。准确性和信心的匹配情况分为四种,相关数据展示在表1中。

▲回答正确与模型置信度之间各种匹配情况下 的样本计数
为了精准评估模型对知识边界的感知能力,提出了三个指标。
-
计算Alignment = (Ncc + Niu) / N,可以评估模型的综合感知水平。
-
使用Overconfidence = Nic / N来衡量模型的过度自信。
-
利用Conservativeness = Ncu / N 来衡量模型的保守性程度。
在计算后两个指标时,不采用Ncc + Nic和Ncu + Niu作为分母,因为模型的不确定性比例同样会影响其是否过度自信或保守。
2. LLMs的知识边界感知
下表展示了LLM在自然问题(NQ)数据集HotpotQA数据集上的问答性能和事实知识边界知。"Conserv."和"Overconf."分别代表保守性和过度自信。

-
问答性能与LLMs的自信度之间的一致性并不高,即便是最强大的模型GPT-4也显示出过度自信的特点。以NQ为例,GPT-4正确回答的问题占比不到49%,然而却有高达18.94%的情况错误地确认其答案正确。
-
过度自信的问题比保守性更为严重,这表明模型对知识边界的不清晰感知主要源于其过度自信。
-
模型的准确性与知识边界感知之间并没有明显的相关性。换句话说,准确性更高的模型可能具有较低的一致性。这意味着对对话数据的进一步训练可能会提升模型对知识边界的感知,但同时也可能会降低其问答性能。
3. 模型对外部信息依赖的程度
在检索增强下,我们需要了解LLMs何时对问题表现出不确定性,以及它们是否会利用提供的外部信息。
实验设置
通过两种不同的提示模板如下图所示,引导模型在正确回答问题同时输出对答案的把握程度,并根据这两个响应,将置信度分为四个级别。

▲一般模板

▲
如果模型两次都表达出不确定,这表明缺乏自信,而两次都表达出确定则表明模型高度自信。这四个置信度级别如下界定:级别0:c = 0, cˆ = 0;级别1:c = 0;级别2:c = 1;级别3:c =1, cˆ = 1。置信水平从级别0递增到级别4。
增强文档类型
本文着重关注两种类型的支持文档之间的关系:
-
黄金文档:使用DPR检索增强得到的真实文档,其中包含问题的真实答案,有1691个带有黄金文件的问题。
-
腐败文档:只是将文件中正确答案替为“Tom”,其他部分与黄金文档相同。
提示模板
要求模型自行决定是依靠其内部知识还是依赖于检索文档来回答问题。提示模板如下图所示:

评估指标
测试模型包括LLaMA2、GPT-Instruct和ChatGPT,并通过两个指标评估结果:
-
利用率Utilization Ratio:对于给定的问题和文档,以及无增强的响应和带增强的响应。如果,则推断模型依赖于文档。其中γ为阈值,文本设为0,Overlap代表文档之间的重叠程度。
-
错误率Corruption Rate:无增强的响应正确而带增强的响应错误的问题百分比。
利用率用于黄金文件,错误率用于腐败文档。虽然依赖黄金文档并不等同于答案的准确性,因为模型可能参考了文档的其他部分,但答案与文档之间的重叠增加仍然是一个重要指标。相比之下,当模型依赖腐败文件时,生成错误答案的概率显著提高。
因此,如果模型在本来应该回答正确的问题上给出了错误的答案,则认为它是过度依赖了文档。
实验结果
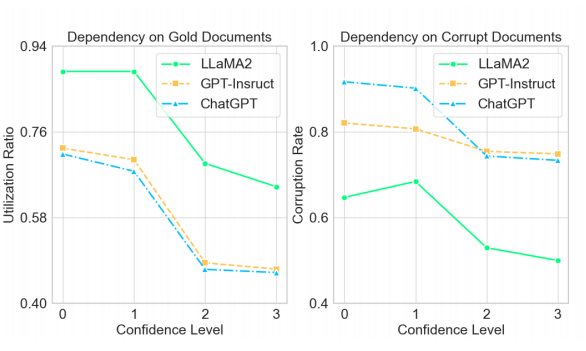
-
随着置信度的提高,所有模型在文档依赖性方面都表现出下降。这表明当语言模型表达不确定性时,它们倾向于更多地依赖外部文档。
-
总体上,无论文档是否包含正确答案,LLMs对文档的依赖性都相当高。这意味着LLMs倾向于信任输入内容,因此在利用检索增强时特别需要谨慎,尤其是当检索器表现不佳时。
4. 提升知识边界感知的方法
上文得出LLM对知识边界的认知不足主要是由于它们过于自信所致。因此,通过减轻过度自信可以增强对知识边界的认知。分别从敦促LLM谨慎行事,以及提高模型提供正确答案的能力两大方面入手。
1. 敦促LLM谨慎行事
为了减少大型语言模型(LLMs)的过度自信,研究提出了三种策略:
-
惩罚Punish:通过在提示中加入“如果回答不正确但你确定的话,你将会受到惩罚”,鼓励模型在给出确定答案前更加谨慎。

-
挑战Challenge:对生成的答案的正确性提出疑问,迫使模型表达更多的不确定性。

-
Think Step by Step:明确要求模型逐步思考,先回答问题,然后在下一步输出自信度。希望当要求逐步思考时,模型能认识到自己的过度自信。

2. 提高正确答案能力:Generate和Explain
为了提高LLMs给出正确答案的能力,研究提出了Generate和Explain两种方法。
-
生成Generate:让模型自己生成一份有助于回答问题的短文档,从而提高回答的准确性。

-
解释Explain:在提供答案之前要求模型解释其答案的原因,这样不仅可以获得辅助信息,还可能通过要求模型解释答案来减少没有合理解释的错误回答的风险。

3.两者结合
为了结合谨慎和增强问答性能的概念,本文还将惩罚和解释方法合并为一种方法,称为惩罚+解释。

实验结果
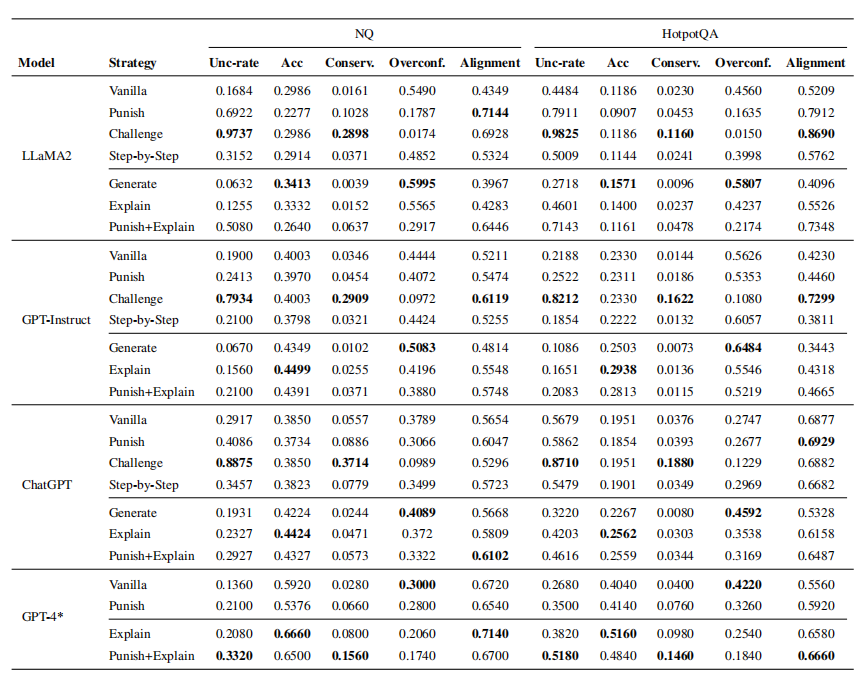
-
挑战方法显著提高了不确定响应比例并降低了过度自信,表明LLMs易过度相信输入并削弱自身判断。
-
惩罚方法减少了过度自信,避免过度保守,通常能改善答案对齐度。
-
逐步思考方法在NQ上有效,但在HotpotQA上加剧了过度自信,效果有限。
-
生成方法产生最高过度自信分数,因为LLMs依赖生成的文档,导致过度自信。
-
解释方法通常减少过度自信,保持较低保守水平,增强LLMs对知识边界的认识。ChatGPT在HQ数据集上过度自信最低,难以进一步提高准确性。
-
结合谨慎性和QA性能概念,本文结合Punish+Explain方法,提高了对齐性而不影响准确性。
-
所有促使模型谨慎的方法都导致预期的不确定响应比例增加。
-
提高QA性能的方法旨在增加答案准确性。
-
对于LLaMA2,因其严重过度自信和较弱生成能力,惩罚方法非常有效。而GPT-4因较低过度自信和强大生成能力,解释方法非常有效。
5. 自适应检索增强(Adaptive Retrieval Augmentation)
本文主要是确定何时进行检索,而不是一直触发检索,同时增强LLMs利用未知质量文档的能力。因此结合惩罚+解释的方法,开展自适应检索增强研究。
实验设置
本文在两种设置下进行检索增强:
-
静态检索增强:对所有问题启用检索增强。
-
自适应检索增强:当模型认为基于其内部知识无法回答问题时,自适应地启用检索增强。
实验中使用了三种类型的支持文档:稀疏检索文档、密集检索文档和包含正确答案的黄金文档。这些文档分别代表了实际情况的下限和上限。
采用了两个开放域QA基准数据集:Natural Questions (NQ) 和 HotpotQA,以及五个不同的模型,包括两个开源模型和三个黑盒模型。
实验使用的提示(prompts)包括Vanilla、Punish、Explain和Punish+Explain四种。
实验结果

-
对于自适应检索增强,Punish+Explain 方法在大多数情况下取得了最佳结果。
-
自适应检索增强仅利用最小数量的检索尝试就取得了与静态增强的性能相当甚至更好的效果索尝试。
-
当利用稀疏检索器检索的文档时,静态增强在NQ上性能出现下降。这是因为检索提供低质量的文档误导了模型。相比之下,自适应检索增强可以减少性能损失。
-
Explain策略在大多数场景下获得了最高准确性,该方法本质上增强了性能并且具有相对较小的不确定率。
-
在使用黄金文档进行增强时,静态增强在几乎所有情况下均实现了最高准确性。这表明包含答案的文档通常有助于回答问题。
-
自适应检索增强使LLMs对不相关的文档更加稳健。
-
在实际搜索场景中,Explain和Punish+Explain策略比静态增强更高效,当文档有助于提高准确率时,这些策略通常能够实现与静态增强相当或更好的性能,同时需要更少的检索尝试。
6. 结论
在本研究中 提出了一系列方法来减轻大型语言模型的过度自信问题,并通过这些方法增强了模型对知识边界的感知,从而提高了检索增强的效果。
局限与未来探索方向:
本文将模型对其回答的置信度划分为两个组成部分,没有进一步细化。未来的研究可以探索更细粒度的置信度划分,以更精确地理解和指导模型的行为。
另外本文通过提示来减轻LLMs的过度自信,这可能对于那些过度自信程度特别高的模型(例如Vicuna-v1.5-7B)的调整有限。对于开源模型,可能存在更有效的训练方法。此外,我们的研究主要集中在LLMs对其事实知识边界的感知水平上,而对于不同类型知识的知识边界感知仍有待研究。
公众号「夕小瑶科技说」后台回复“When”获取论文PDF!


这篇关于中科院计算所:什么情况下,大模型才需要检索增强?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







