中科院计算所专题

AI 编译器技术分享会:上海交大/中科院计算所/微软亚研/智源,他们来了!
4 场 Meetup、3 个城市、19 位嘉宾、1k+ 行业从业者、累计 100w+ 曝光, 2023 年 AI 编译器社区小小刷新了一下存在感,我们在非常细分的领域里找到了最为垂直的开发者和工程师,从 0 到 1 建立起一个个小据点,搭建交流平台、促成企内合作、连通生态上下游。 2024 年虽然已经过半,在大模型持久占据技术圈「热搜榜单」的今天,我们将于 7 月 6 日(周六)在中国科学院计算

中科院计算所Goddon CPU诞生历史!牛!
下面就是项目负责人-胡伟武的研发手记 我参与计算所的CPU开发项目,源于2000年10月一个偶然的机缘。10月中旬,所领导派我到我的母校中国科技大学去进行招生宣传。这是我1991年毕业后第一次回到母校。我回到了我原来工作过的实验室,十年前在那里,我曾经和另外一个同学一起做过一个与8086指令级兼容的处理器作为本科毕业设计。这是一个用400多个74LS系列的芯片搭起来的电路,能够运行8086指
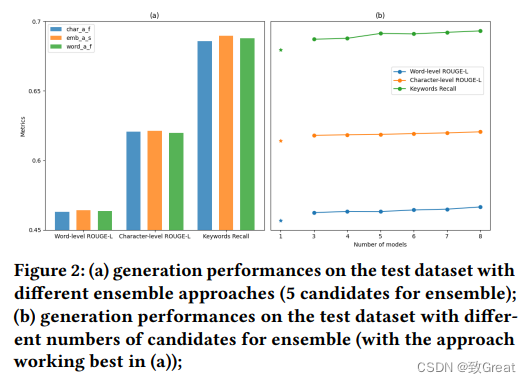
【中科院计算所】WSDM 2024冠军方案:基于大模型进行多文档问答
作者:李一鸣 张兆 中科院计算所 会话式多文档问答旨在根据检索到的文档以及上下文对话来回答特定问题。 在本文中,我们介绍了 WSDM Cup 2024 中“对话式多文档 QA”挑战赛的获胜方法,该方法利用了大型语言模型 (LLM) 卓越的自然语言理解和生成能力。 在方案中,首先让大模型适应该任务,然后设计一种混合训练策略,以充分利用领域内的未标记数据。 此外,采用先进的文本嵌入模型来过滤掉潜

中科院计算所:什么情况下,大模型才需要检索增强?
ChatGPT等大型语言模型在自然语言处理领域表现出色。但有时候会表现得过于自信,对于无法回答的事实问题,也能编出一个像样的答案来。 这类胡说乱说的答案对于医疗等安全关键的领域来说,是致命的。 为了弥补这一缺陷,研究者们提出了检索增强技术,通过引入外部知识源来减少模型的错误信息。然而,频繁的检索不仅增加开销,还可能引入不准确或误导性的信息。 因此,检索的时机就变得很重要了。如果仅在LLM

中文分词工具比较 6大中文分词器测试(哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP)
中文分词工具比较 6大中文分词器测试(jieba、FoolNLTK、HanLP、THULAC、nlpir、ltp) 哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba 个人接触的分词器 安装 调用 jieba“结巴”中文分词:做最好的 Python 中文分词组件https://github.com/fxsjy/jieba THULAC清华大学:一个高效的中文词法分析工具包