本文主要是介绍跳表是一种什么样的数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
跳表是有序集合的底层数据结构,它其实是链表的一种进化体。正常链表是一个接着一个用指针连起来的,但这样查找效率低只有O(n),为了解决这个问题,提出了跳表,实际上就是增加了高级索引。朴素的跳表指针是单向的并且元素值不能重复,redis对其进行了修改,回退指针的作用是支持反向遍历。
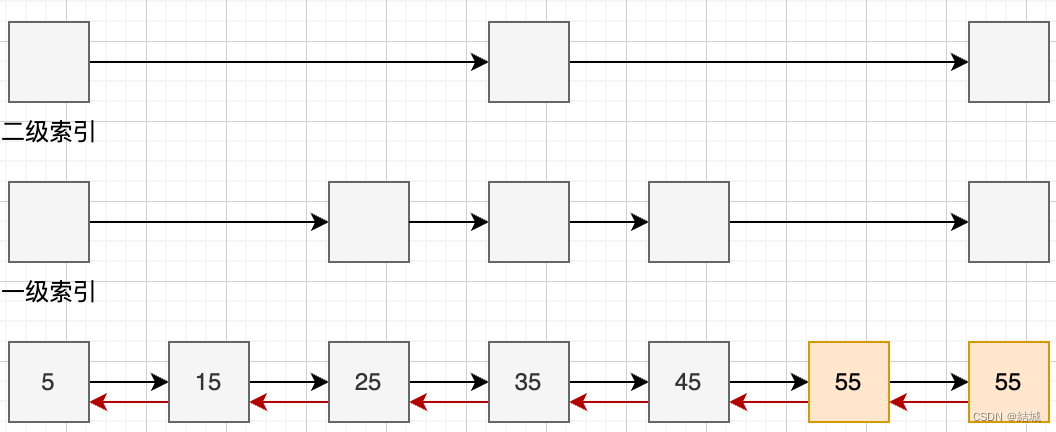
具体查找过程,假设查45,那从5的二级索引一下跳到35,发现还没找到,再跳到55。发现超了,那用一级索引试试,结果找到了,那ok了。需要注意,使用高级索引时候底层源码实现时候还有一个对于步长的记录,也就是5->35用二级索引记录了步长3
插入的话,不会影响当前表中节点的层高,因为节点被创建时和层高就已经确定了(当然可能会修改插入位置前后结点的关联指针,这是链表必然的)。
那一个节点层高如何确定?
这是在插入时候确定的,默认每个节点一开始默认的是1层(一级索引都没有),每次以25%概率增加1层(5.0.5版本最高为64层)。不用一个层高数量的比例是因为不想刻意维护这种比例关系,导致额外开销。
跳表的平均性能能达到O(logn),并且由于表头有定义查询有序集合元素总数时仅需O(1)
那么为啥redis不用b+树呢?
因为b+树是更多用于磁盘io的,其可以降低磁盘io次数。redis是内存中的,所以b+树这扁平特性没那么重要了,并且跳表实现起来简单,也不用考虑在中间位置插入后保持平衡的操作。
同样的问题,为啥不用红黑树?
其实就是因为跳表实现简单,占用内存少(层高概率25%是可以调的,层高越大占用内存越多,折中选择),并且查询性能和局部性不比红黑树差
这篇关于跳表是一种什么样的数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







