本文主要是介绍谷歌掀桌子!开源Gemma:可商用,性能超过Llama 2!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2月22日,谷歌在官网宣布,开源大语言模型Gemma。
Gemma与谷歌最新发布的Gemini 使用了同一架构,有20亿、70亿两种参数,每种参数都有预训练和指令调优两个版本。
根据谷歌公布的测试显示,在MMLU、BBH、GSM8K等主流测试平台中,其70亿模型在数学、推理、代码的能力超过Llama-2的70亿和130亿,成为最强小参数的类ChatGPT模型。
目前,Gemma可以商用,并且普通笔记本、台式机就能跑,无需耗费巨大的AI算力矩阵。
Kaggle地址:https://www.kaggle.com/models/google/gemma/code/
huggingface地址:https://huggingface.co/models?search=google/gemma
技术报告:https://goo.gle/GemmaReport

谷歌作为贡献出Transformers、TensorFlow、BERT、T5、JAX、AlphaFold等一系列改变世界AI发展的宗师级大师,在生成式AI领域却一直落后于OpenAI。
不仅如此,开源领域还打不过类ChatGPT开源鼻祖Meta的Llama系列。痛定思痛之后,谷歌决定重新加入开源阵营,以抢夺开发者和用户。
Gemma简单介绍
谷歌表示,Gemma之所以性能如此强悍,主要是使用了与Gemini相同的技术架构。
更详细的开发者指南:https://ai.google.dev/gemma/docs?utm_source=agd&utm_medium=referral&utm_campaign=quickstart-docu
Gemini的基础架构建立在Transformer编码器结构之上,通过多层自注意力和前馈神经网络来建模序列依赖性。不同的是Gemini采用了多查询注意力机制,可处理超复杂长文本。
具体来说,模型首先将输入序列的每个位置编码成多组查询向量。然后,将这些查询向量并行地与键值对进行批量注意力运算,得到多个注意力结果。
除了开源模型权重,谷歌还推出Responsible Generative AI Toolkit等一系列工具,为使用Gemma提供更安全的AI应用程序提供指导。
目前,Gemma开放了两个版本:预训练,该版本未针对 Gemma 核心数据训练集以外的任何特定任务或指令进行训练;指令微调,通过人类语言互动进行训练,可以响应对话输入,类似ChatGPT聊天机器人。
跨框架、工具和硬件,对Gemma进行优化
开发者可以根据自己的数据微调 Gemma 模型,以适应特定的应用程序需求,例如,生成摘要/文本或检索增强生成 (RAG)等。Gemma 支持以下多种工具和系统:
多框架工具:可跨多框架 Keras 3.0、本机 PyTorch、JAX 和 Hugging Face Transformers 进行推理和微调。
跨设备兼容性:Gemma可以跨多种设备类型运行,包括笔记本电脑、台式机、物联网、移动设备和云,从而实现广泛的 AI 功能。

高级硬件平台:谷歌与NVIDIA合作,针对 NVIDIA GPU 优化 Gemma模型,从数据中心到云端再到本地RTX AI PC,提供行业领先的性能并与尖端AI技术集成。
针对 Google Cloud 进行了优化:Vertex AI 提供广泛的 MLOps 工具集,具有一系列调整选项,并可使用内置推理优化功能进行一键式部署。
高级定制功能可通过完全管理的顶点人工智能工具或自我管理的GKE 实现,包括部署到 GPU、TPU 和 CPU 平台上具有成本效益的基础设施。
Gemma性能测试
谷歌在MMLU、BBH、GSM8K等主流测试平台中,用Gemma 70亿模型与Llama-2、Mistral在数学、推理、代码等方面进行了深度测试。
Gemma的标准学术基准测试平均分数都高于同规模的Llama 2和Mistral模型。甚至在一些关键能力方面,高于Llama-2 130亿参数模型。
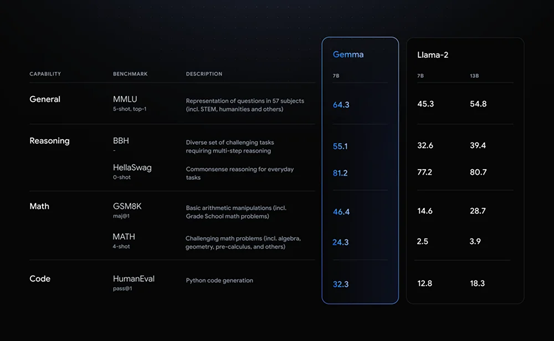
也就是说,Gemma是一款参数很小,性能却异常强悍的大模型。
本文素材来源谷歌官网,如有侵权请联系删除
这篇关于谷歌掀桌子!开源Gemma:可商用,性能超过Llama 2!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






