本文主要是介绍Elasticsearch:使用 ELSER v2 进行语义搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在我之前的文章 “Elasticsearch:使用 ELSER 进行语义搜索”,我们展示了如何使用 ELESR v1 来进行语义搜索。在使用 ELSER 之前,我们必须注意的是:
重要:虽然 ELSER V2 已正式发布,但 ELSER V1 仍处于 [预览] 状态。此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束,并将保留在技术预览版中。
也就是说 ELSER v1 不建议在生产环境中使用。在生产的环境中,我们建议使用 ELSER v2。由于两个版本中的使用方法稍有不同。在今天的文章中,我们以 ELSER v2 为例来进行展示。
简介
Elastic Learned Sparse EncodeR(或 ELSER)是由 Elastic 训练的 NLP 模型,使你能够使用稀疏向量表示来执行语义搜索。 语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
本教程中的说明向你展示如何使用 ELSER 对数据执行语义搜索。
注意:在使用 ELSER 进行语义搜索期间,仅考虑每个字段提取的前 512 个标记。 请参阅此页面了解更多信息。
要求
要使用 ELSER 执行语义搜索,你必须在集群中部署 NLP 模型。 请参阅 ELSER 文档以了解如何下载和部署模型。
注意:如果关闭部署自动扩展,则 Elasticsearch Service 中用于部署和使用 ELSER 模型的最小专用 ML 节点大小为 4 GB。 建议打开自动扩展功能,因为它允许你的部署根据需求动态调整资源。 通过使用更多分配或每次分配更多线程可以实现更好的性能,这需要更大的 ML 节点。 自动扩展可在需要时提供更大的节点。 如果关闭自动扩展,你必须自己提供适当大小的节点。
创建索引映射
首先,必须创建目标索引的映射 - 包含模型根据你的文本创建的 token 的索引。 目标索引必须具有 sparse_vector 或 rank_features 字段类型的字段才能对 ELSER 输出进行索引。
注意:ELSER 输出必须摄取到具有 sparse_vector 或 rank_features 字段类型的字段中。 否则,Elasticsearch 会将 token 权重对解释为文档中的大量字段。 如果你收到类似于 “Limit of total fields [1000] has been exceeded while adding new fields” 的错误,则 ELSER 输出字段未正确映射,并且其字段类型不同于 sparse_vector 或 rank_features。
PUT my-index
{"mappings": {"properties": {"content_embedding": { "type": "sparse_vector" },"content": { "type": "text" }}}
}- content_embedding 包含生成的 token 的字段的名称。 必须在下一步的推理管道配置中引用它。
- sparse_vector 定义字段是 sparse_vector 字段。
- 用于创建稀疏向量表示的字段的名称。 在此示例中,字段的名称是 content。 必须在下一步的推理管道配置中引用它。
- text 定义字段类型为文本。
使用推理处理器创建摄取管道
创建带有 inference processor 的 ingest pipeline,以使用 ELSER 来推理管道中摄取的数据。
PUT _ingest/pipeline/elser-v2-test
{"processors": [{"inference": {"model_id": ".elser_model_2","input_output": [ {"input_field": "content","output_field": "content_embedding"}]}}]
}- input_output:配置对象,定义推理过程的输入字段和包含推理结果的输出字段。
加载数据
在此步骤中,你将加载稍后在推理摄取管道中使用的数据,以从中提取 token。
使用 msmarco-passagetest2019-top1000 数据集,该数据集是 MS MARCO Passage Ranking 数据集的子集。 它由 200 个查询组成,每个查询都附有相关文本段落的列表。 所有独特的段落及其 ID 均已从该数据集中提取并编译到 tsv 文件中。
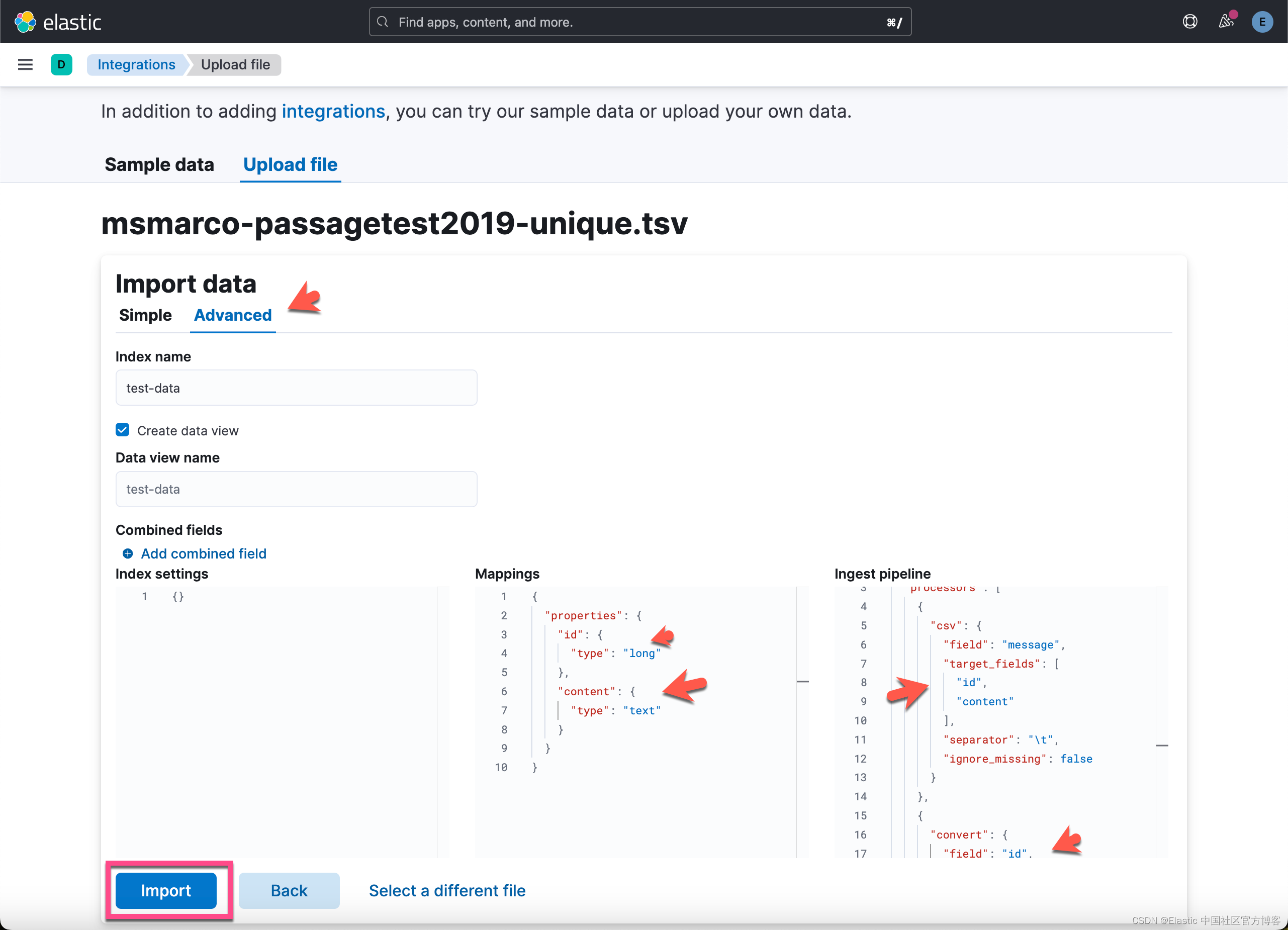
下载文件并使用机器学习 UI 中的数据可视化工具将其上传到集群。 将名称 id 分配给第一列,将内容分配给第二列。 索引名称是 test-data。 上传完成后,你可以看到名为 test-data 的索引,其中包含 182469 个文档。
关于如何加载这个数据,请详细阅读文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索”。


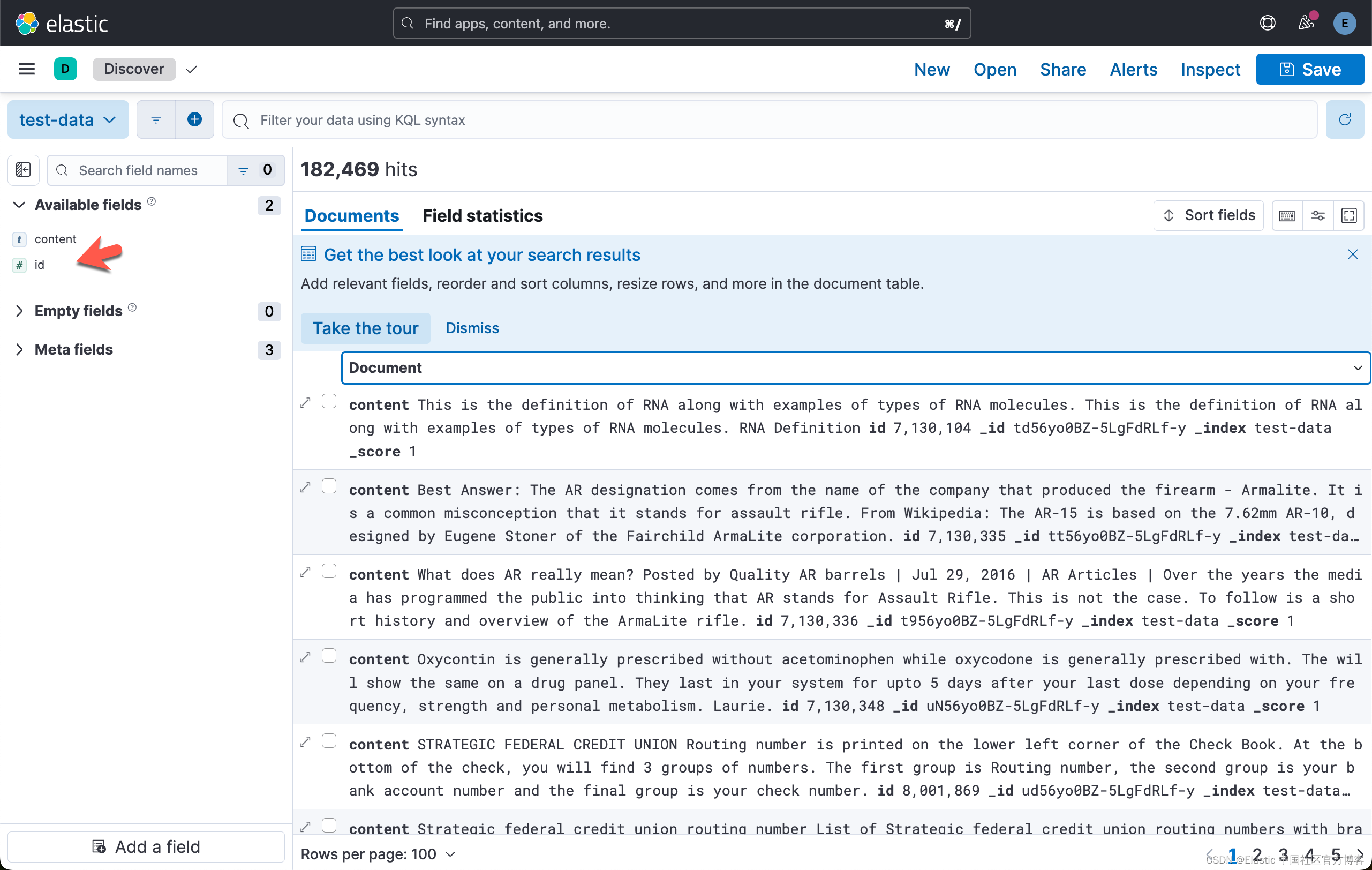
我们可以在 Discover 中进行查看:
通过推理摄取管道摄取数据
通过使用 ELSER 作为推理模型的推理管道重新索引数据,从文本创建标记。
POST _reindex?wait_for_completion=false
{"source": {"index": "test-data","size": 50 },"dest": {"index": "my-index","pipeline": "elser-v2-test"}
}- Reindex 的默认批量大小为 1000。将大小减小到较小的数字可以使重新索引过程的更新更快,使你能够密切跟踪进度并尽早发现错误。

该调用返回一个任务 ID 以监控进度:

我们等到 completed 的状态变为 true:
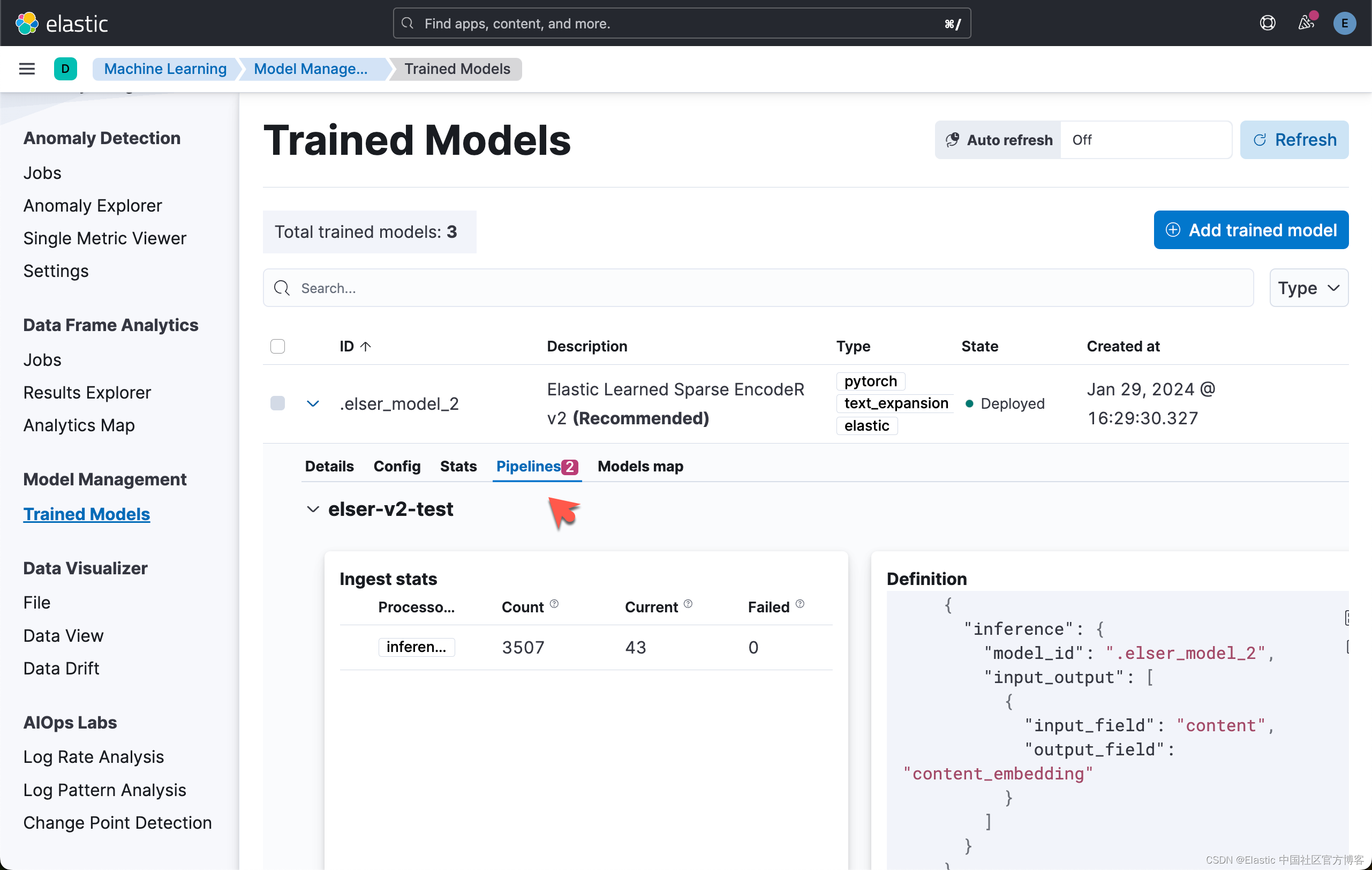
你还可以打开训练模型 UI,选择 ELSER 下的 Pipelines 选项卡来跟踪进度。
使用 text_expansion 查询进行语义搜索
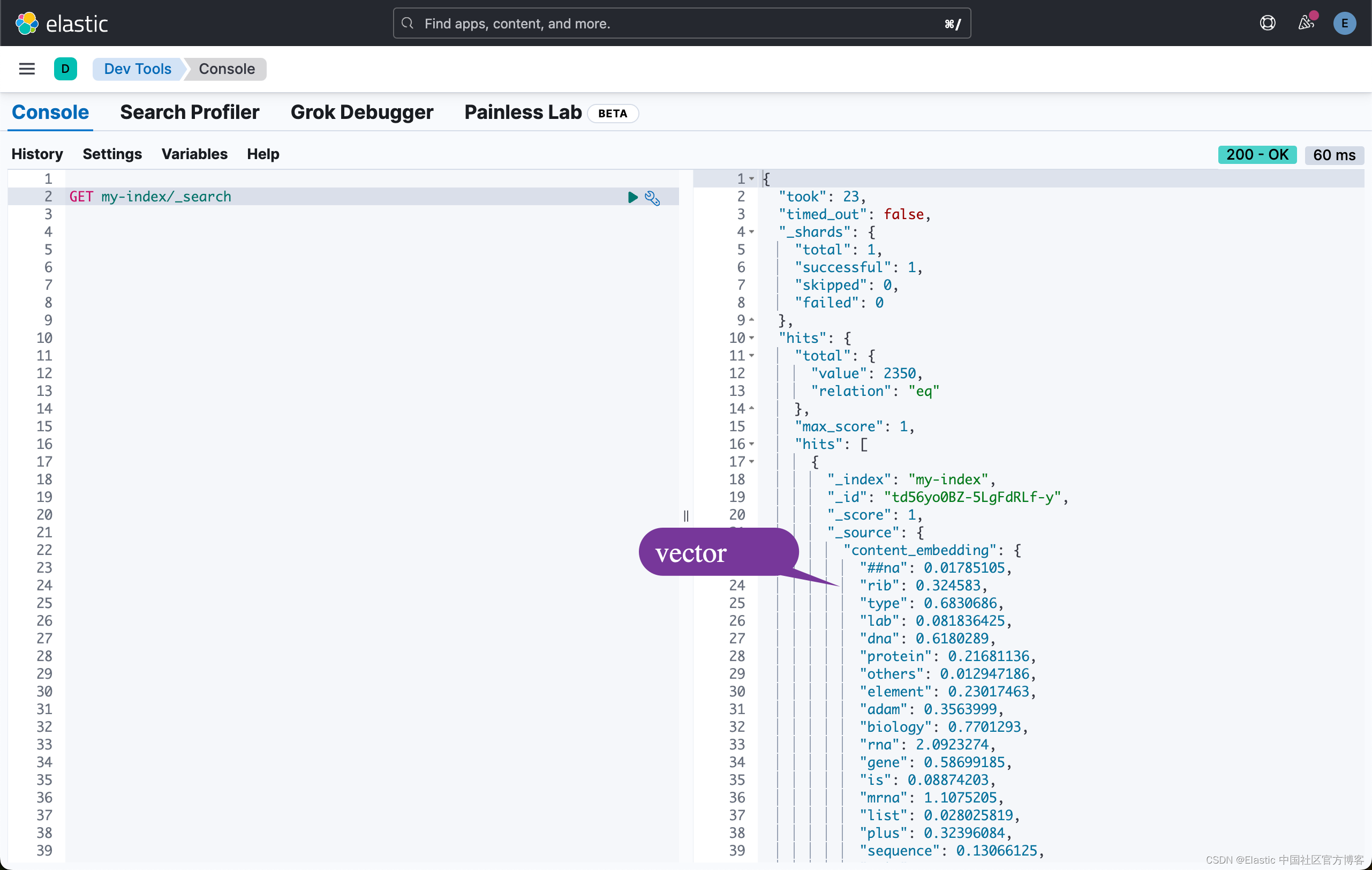
要执行语义搜索,请使用 text_expansion 查询,并提供查询文本和 ELSER 模型 ID。 下面的示例使用查询文本 “How to avoid muscle soreness after running?”,content_embedding 字段包含生成的 ELSER 输出:
GET my-index/_search
{"_source": false,"fields": ["content"], "query":{"text_expansion":{"content_embedding":{"model_id":".elser_model_2","model_text":"How to avoid muscle soreness after running?"}}}
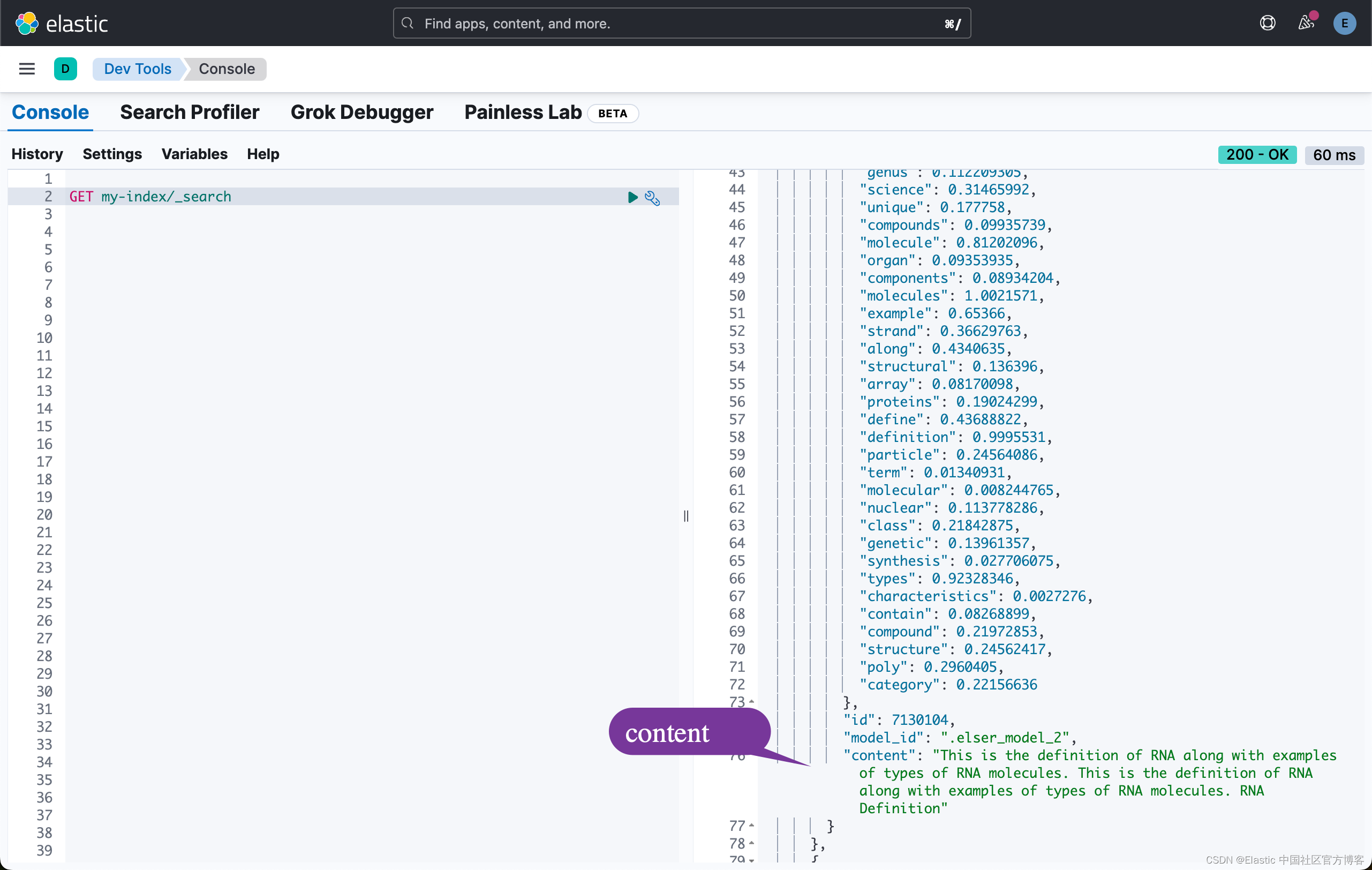
}结果是 my-index 索引中按相关性排序的与你的查询文本含义最接近的前 10 个文档。 结果还包含为每个相关搜索结果提取的 token 及其权重。 标记是捕获相关性的学习关联,它们不是同义词。 要了解有关 token 是什么的更多信息,请参阅此页面。 可以从源中排除 token,请参阅下面的章节以了解更多信息。
{"took": 1531,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 10000,"relation": "gte"},"max_score": 25.669455,"hits": [{"_index": "my-index","_id": "fd96yo0BZ-5LgFdRMD7b","_score": 25.669455,"fields": {"content": ["There are a few foods and food groups that will help to fight inflammation and delayed onset muscle soreness (both things that are inevitable after a long, hard workout) when you incorporate them into your postworkout eats, whether immediately after your run or at a meal later in the day. Advertisement. Advertisement."]}},{"_index": "my-index","_id": "nt96yo0BZ-5LgFdRLQCy","_score": 23.388044,"fields": {"content": ["What so many out there do not realize is the importance of what you do after you work out. You may have done the majority of the work, but how you treat your body in the minutes and hours after you exercise has a direct effect on muscle soreness, muscle strength and growth, and staying hydrated. Cool Down. After your last exercise, your workout is not over. The first thing you need to do is cool down. Even if running was all that you did, you still should do light cardio for a few minutes. This brings your heart rate down at a slow and steady pace, which helps you avoid feeling sick after a workout."]}},{"_index": "my-index","_id": "ot96yo0BZ-5LgFdRLzD0","_score": 22.550915,"fields": {"content": ["If you’ve been exercising more, you may be suffering from the aches and pains of having overdone it at the gym. I’ve been there. Making sure your workout is challenging without overdoing it is one way to prevent muscle soreness. But research also points to some foods and beverages that can help ward off and minimize exercise-related muscle soreness, which we’ve reported on in EatingWell Magazine. Related: Foods to Eat to Improve Your Workout Post-Workout Breakfast Recipes What to Drink Before, During and After You Exercise. Blueberries."]}}...将语义搜索与其他查询相结合
你可以将 text_expansion 与复合查询中的其他查询结合起来。 例如,在布尔查询或全文查询中使用过滤子句,该查询可能会或可能不会使用与 text_expansion 查询相同的查询文本。 这使你能够合并两个查询的搜索结果。
text_expansion 查询的搜索命中得分往往高于其他 Elasticsearch 查询。 可以通过使用 boost 参数增加或减少每个查询的相关性分数来对这些分数进行正则化。 当存在不太相关的结果时,text_expansion 查询的召回率可能很高。 使用 min_score 参数来修剪那些不太相关的文档。
GET my-index/_search
{"query": {"bool": { "should": [{"text_expansion": {"content_embedding": {"model_text": "How to avoid muscle soreness after running?","model_id": ".elser_model_2","boost": 1 }}},{"query_string": {"query": "toxins","boost": 4 }}]}},"min_score": 10
}- text_expansion 和 query_string 查询都位于 bool 查询的 should 子句中。
- text_expansion 查询的 boost 值为 1,这是默认值。 这意味着该查询结果的相关性得分不会提高。
- query_string 查询的提升值为 4。 该查询结果的相关性得分增加,导致它们在搜索结果中排名更高。
- 仅显示分数等于或高于 10 的结果。
优化性能
通过从文档源中排除 ELSER token 来节省磁盘空间
必须对 ELSER 生成的 token 进行索引,以便在 text_expansion 查询中使用。 但是,没有必要在文档源中保留这些术语。 你可以通过使用 source exclude 映射从文档源中删除 ELSER 术语来节省磁盘空间。
警告:重新索引使用文档源来填充目标索引。 一旦 ELSER 术语从源中排除,就无法通过重新索引来恢复它们。 从源中排除 token 是一种节省空间的优化,只有在你确定将来不需要重新索引时才应应用该优化! 仔细考虑这种权衡并确保从源中排除 ELSER 术语符合你的特定要求和用例,这一点很重要。 仔细查看禁用 _source 字段和从 _source 中包含/排除字段部分,以详细了解从 _source 中排除 token 可能产生的后果。
可以通过以下 API 调用创建从 _source 字段中排除 content_embedding 的映射:
PUT my-index
{"mappings": {"_source": {"excludes": ["content_embedding"]},"properties": {"content_embedding": {"type": "sparse_vector"},"content": {"type": "text"}}}
}注意:根据你的数据,使用 track_total_hits: false 时文本扩展查询可能会更快。
更多阅读:Elasticsearch:使用 ELSER v2 文本扩展进行语义搜索
这篇关于Elasticsearch:使用 ELSER v2 进行语义搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





