本文主要是介绍基于RWKV架构推理成本大降:Eagle 7B模型的十倍效能提升,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在今天这个数据驱动的时代,大型语言模型(LLM)在处理自然语言处理(NLP)任务时的效能和效率成为了众多研究者和工程师关注的焦点。尤其是在推理成本日益攀升的背景下,如何在保持甚至提升模型性能的同时,大幅降低推理成本,成为了一个迫切需要解决的问题。最近,由RWKV团队推出的Eagle 7B模型,就在这方面展示了其惊人的潜力。
-
Huggingface模型下载:https://huggingface.co/RWKV/v5-Eagle-7B
-
AI快站模型免费加速下载:https://aifasthub.com/models/RWKV

其具有以下特点:
-
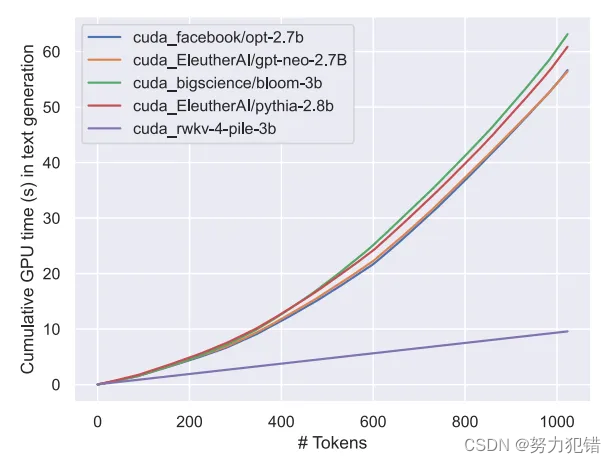
基于 RWKV-v5 架构构建,该架构的推理成本较低(RWKV 是一个线性 transformer,推理成本降低 10-100 倍以上);
-
在 100 多种语言、1.1 万亿 token 上训练而成;
-
在多语言基准测试中优于所有的 7B 类模型;
-
在英语评测中,Eagle 7B 性能接近 Falcon(1.5T)、LLaMA2 (2T)、Mistral;
-
英语评测中与 MPT-7B (1T) 相当;
-
没有注意力的 Transformer。
技术特点
RWKV(Receptive Weighted Key Value)架构,是Eagle 7B的核心,它是一种新型的Transformer架构变种,通过精巧的设计,结合了RNN的序列处理能力和Transformer的并行训练优势。与传统的Transformer相比,RWKV架构在处理长序列时不仅能够保持相似的性能,而且在推理效率上有了数量级的提升。
Eagle 7B模型是基于RWKV-v5架构构建的,它在1.1万亿token上进行了训练,涵盖了100多种语言。它不仅在多语言基准测试中超越了所有的7B级别模型,在英语评估中,其性能也接近了如Falcon、LLaMA2等大型模型。这一成就的背后,是Eagle 7B优秀的架构设计和大规模的数据训练。
让我们深入了解Eagle 7B模型的几个关键特点:
-
架构优势: RWKV-v5架构的推理成本比传统的Transformer低10-100倍,这使得Eagle 7B能够在计算资源受限的环境中,如边缘设备上运行,大幅拓宽了其应用场景。
-
环境友好: Eagle 7B的环境可持续性同样得到了优化。它被评为同级别参数模型中“最绿色”的模型,这意味着在实现高效能处理任务的同时,还能最小化对环境的影响。
-
多语言能力: Eagle 7B在多语言评估上的卓越性能,表明了模型不仅在英语,还在其他多种语言上的广泛适用性和强大能力。不同模型在多语言上的性能如下所示,测试基准包括 xLAMBDA、xStoryCloze、xWinograd、xCopa。
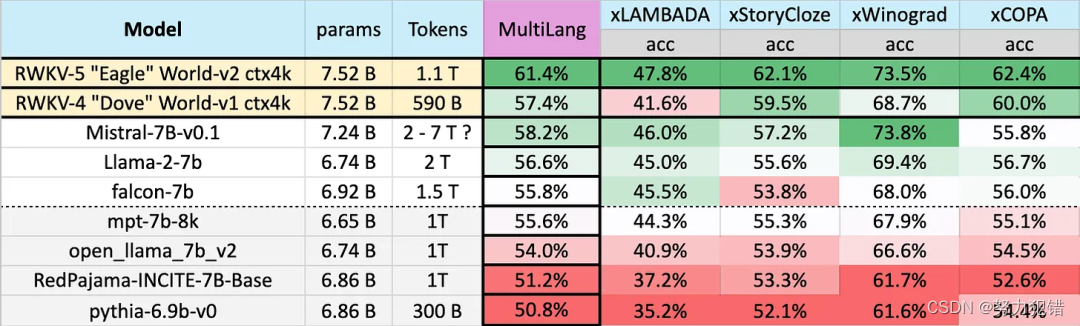
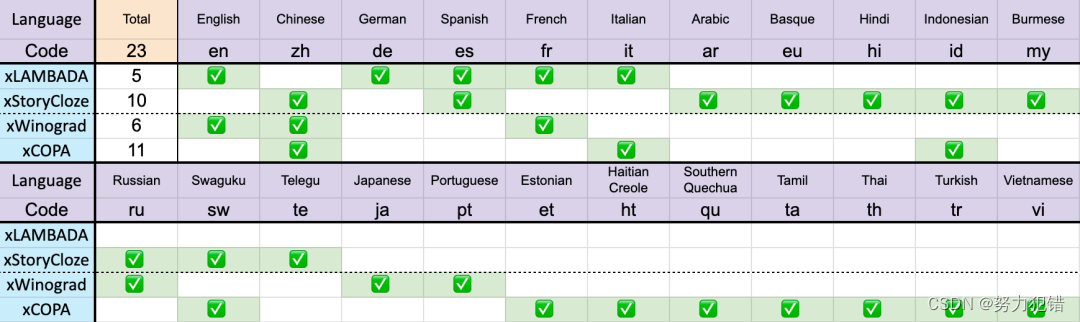
-
无注意力机制: 作为一个无注意力的Transformer,Eagle 7B在多个使用场景中的表现令人瞩目,尽管它可能需要针对特定任务进行进一步的微调。
结论
Eagle 7B的成功不仅展示了RWKV架构的巨大潜力,也为未来LLM的发展提供了新的方向。可以预见,随着技术的不断进步,更多基于RWKV架构的模型将涌现出来,为AI领域带来更多的创新和价值。在模型效能和推理成本之间寻找平衡,将成为推动AI技术发展的重要动力。
模型下载
Huggingface模型下载
https://huggingface.co/RWKV/v5-Eagle-7B
AI快站模型免费加速下载
https://aifasthub.com/models/RWKV
这篇关于基于RWKV架构推理成本大降:Eagle 7B模型的十倍效能提升的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








