本文主要是介绍Stable Diffusion 绘画入门教程(webui)-图生图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过之前的文章相信大家对文生图已经不陌生了,那么图生图是干啥的呢?
简单理解就是根据我们给出的图片做为参考进行生成图片。
一、能干啥
这里举两个例子
1、二次元头像
真人转二次元,或者二次元转真人都行,
下图为真人转二次元样例:左边真人,右边二次元

2、换造型换装
比如我要让真人漏牙齿,或者换头发颜色,换脸,换服装等等都可以用类似方法

二、真人转二次元
主要分三步,
1.反推已经有的图片的关键词,这里的话就是反推真人图像的关键词
2.选大模型,这里是转二次元就要选二次元模型
3.调参找最优
1.反推关键词
这里用到了一个插件“WD 1.4标签器”,如果是参考我之前文章安装的话,默认已经集成了。
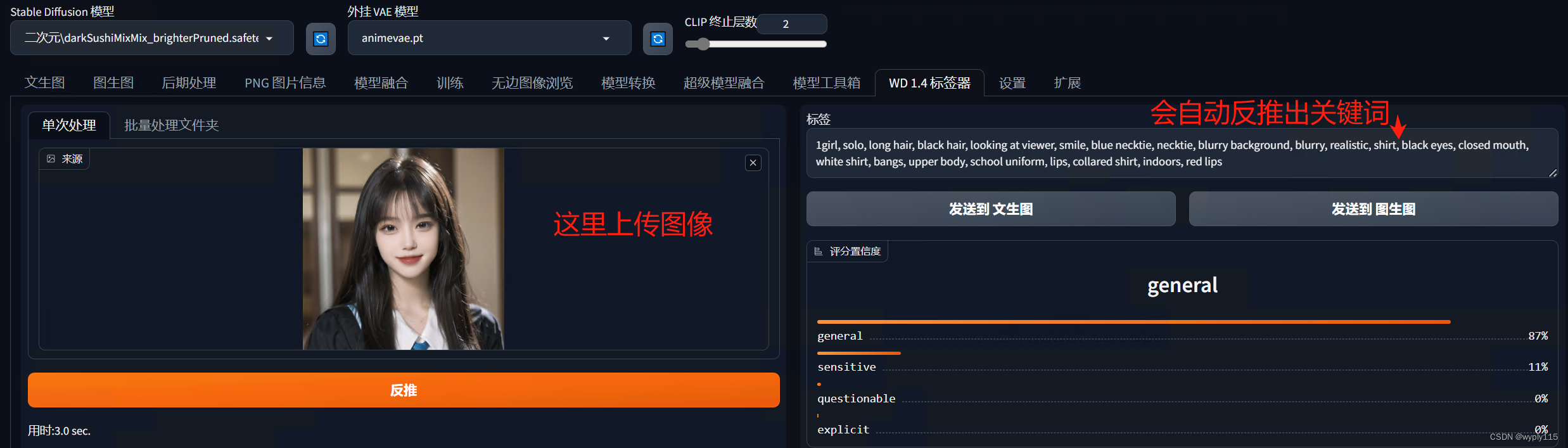
如上图,这里需要把关键词拷贝到翻译软件,看下是否有不适合的关键词

这里反推的比较好,没有不合适的关键词,那什么是不合适的关键词,比如我这里要生成二次元的,如果关键词有真实字样就不是很合适,需要单独删掉。
检查没问题把关键词拷贝到图生图中的提示词中即可。
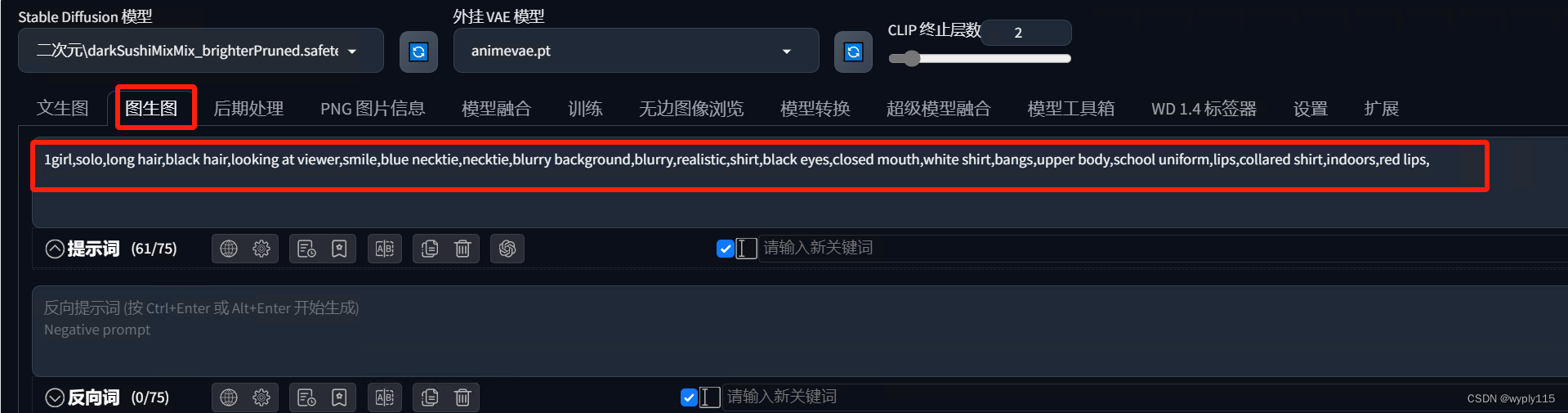
然后把参考图传上去
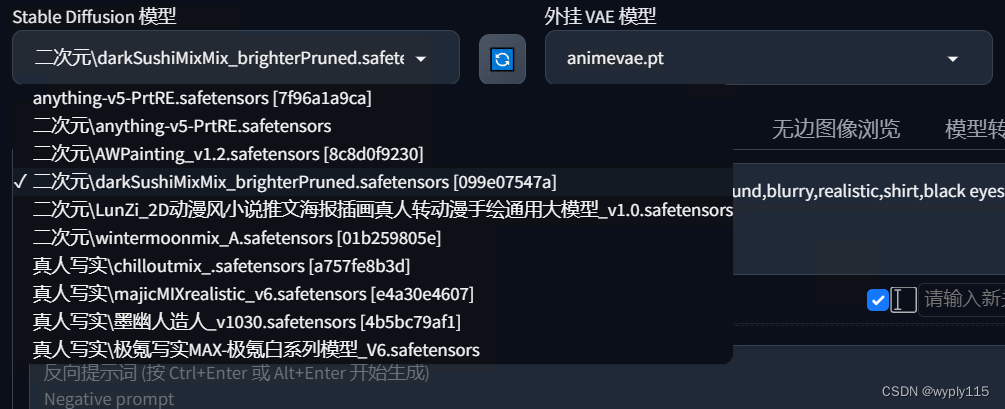
2、选大模型
这里我们要转二次元,所以选择一个二次元模型,当然二次元模型也有很多,根据自己喜好的风格挑选大模型
我这里随便选用一个二次元模型
3、调参数
图生图中有一个重绘幅度,默认是0.75,越小的话会越像原图,越大会约二次元化
下面是重绘幅度0-0.8,间隔0.2的测试效果,选取你最喜欢的一张即可

三、换造型换装
依然是三步,
1.反推已经有的图片的关键词,这里的话就是反推真人图像的关键词(同上)
2.修改关键词,只改动你想变化的部分
3.局部重绘并选大模型,这里是不转换风格,默认用真人大模型即可
4.调参找最优
第一步和上面一样就不说了
2、修改关键词
这是反推出来的关键词
1girl, solo, long hair, black hair, looking at viewer, smile, blue necktie, necktie, blurry background, blurry, realistic, shirt, black eyes, closed mouth, white shirt, bangs, upper body, school uniform, lips, collared shirt, indoors, red lips
我们翻译一下

我们想让女孩露出牙齿,则需要添加一个关键词tooth
但看到上面关键词有一个闭着嘴,这个和露出牙齿冲突,则需要把:
closed mouth 中的closed删掉
最终的关键词放入图生图中的提示词文本框即可
1girl,solo,long hair,white hair,looking at viewer,smile,blue necktie,necktie,blurry background,blurry,realistic,shirt,black eyes,mouth,white shirt,bangs,upper body,school uniform,lips,collared shirt,indoors,red lips,tooth,
3、局部重绘并选大模型
我们需要让嘴露出牙齿,也就是需要重新绘制嘴这个部位,需要将其重新绘制
如下图对嘴部进行涂抹
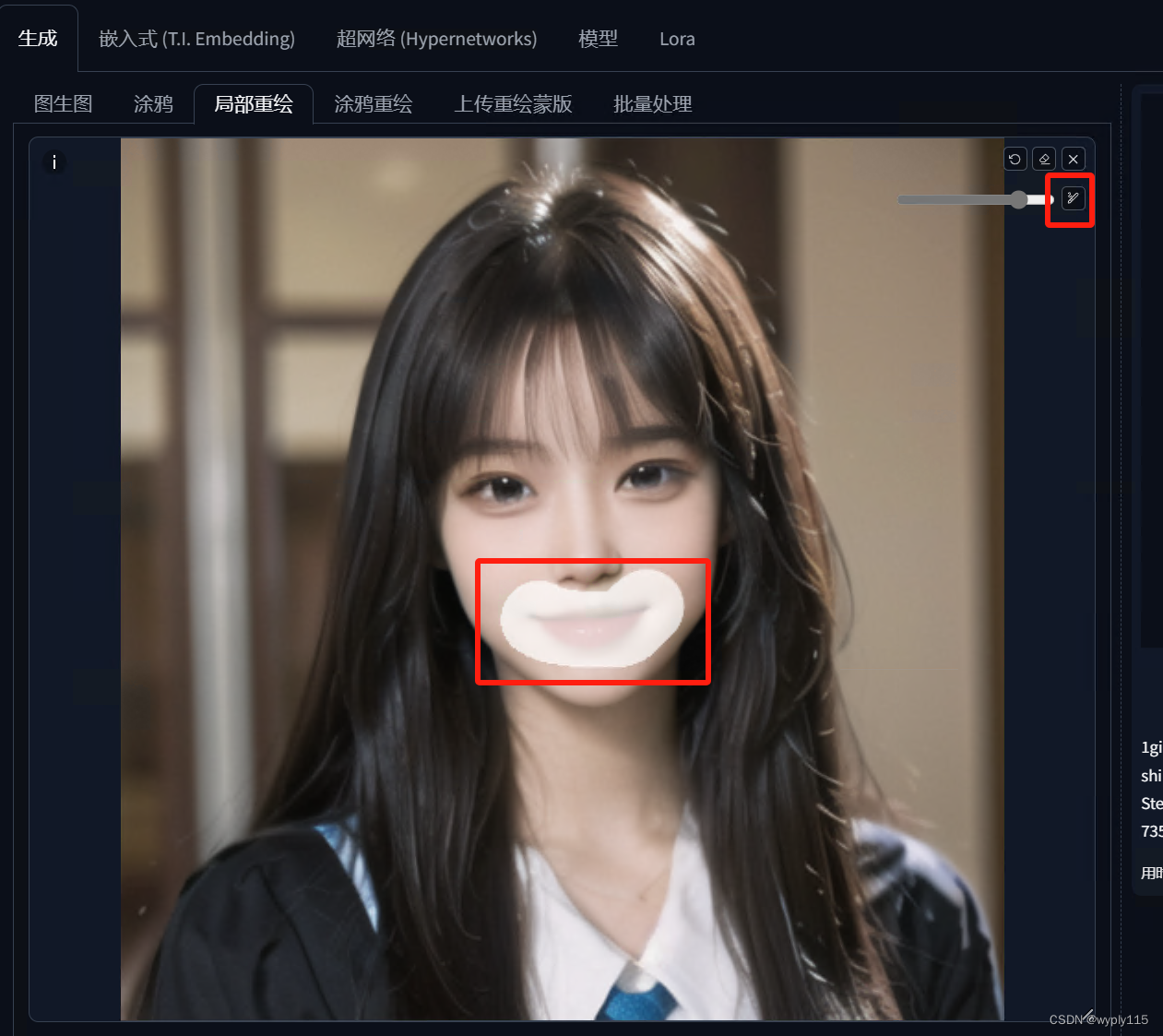
然后设置一下参数
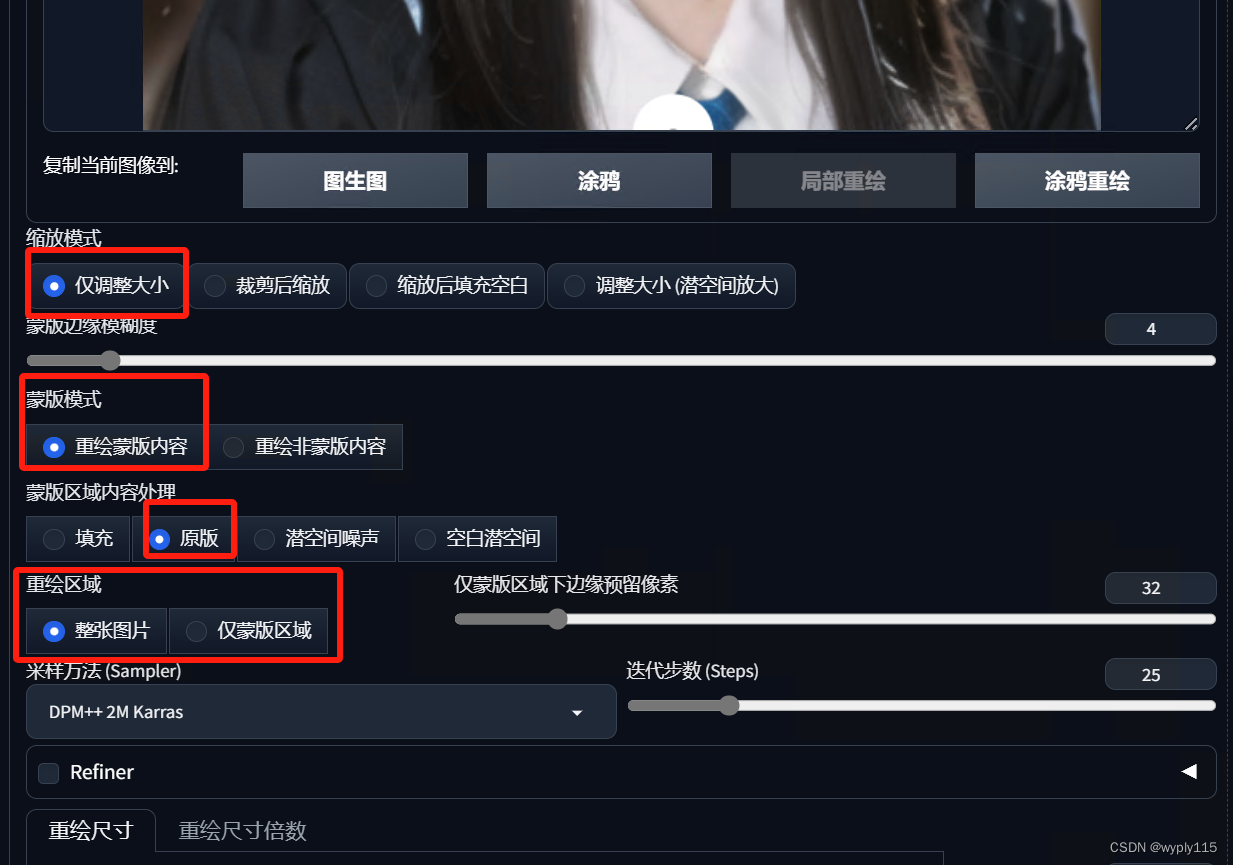
这里不同的参数产生的效果可能会有区别,不过对这么小的局部重绘影响不大,大家自己去探索一下吧,印象会更深刻
然后就是重绘幅度了,我这里设定的是0.6
之后选一个合适的大模型,因为不做风格转换,就选一个写实的模型就好
之后就可以生成测试了

最后的调优参考真人转二次元的案例,找到你觉得最合适得参数即可。
四、其他玩法
其他包括换装、换发型、换头等等也是同样的道理,大家理解了其中原理,不难摸索出来。
这篇关于Stable Diffusion 绘画入门教程(webui)-图生图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









