本文主要是介绍Python 中文词频分析——红楼梦人物出场次数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇文档,带大家用Python做一下词频统计
本章需要用到Python的jieba模块
jieba模块是一个经典的用于中文分词的模块
首先呢 我们需要读取文章的内容,并用jieba库的lcut进行分词
import jieba# 读取红楼梦的文本内容
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
# 运用jieba库对文本内容进行分词
words = jieba.lcut(txt)
然后 我们去统计人名的出现次数
这里需要分析什么词语是人名,我们去创建一个文档,当做字典存储人名信息
人名还会有其他的表示,我们将它转化成一样的名字
# 初始化count字典 用于存放人名出现频率
counts = {}
# 读取红楼梦人名信息
names = open('人名.txt', 'r', encoding='utf-8').read().split('、')
# 对分词数据进行筛选 将不需要的数据跳过 只保存有效数据
for word in words:if len(word) == 1:continueelif word == '贾母' or word == '老太太':word = '贾母'elif word in '贾珍—尤氏'.split('—'):word = '贾珍'elif word in '贾蓉—秦可卿'.split('-'):word = '贾蓉'elif word in '贾赦—邢夫人'.split('-'):word = '贾赦'elif word in '贾政—王夫人'.split('-'):word = '贾政'elif word in '袭人-蕊珠'.split('-'):word = '袭人'elif word in '贾琏—王熙凤'.split('-'):word = '贾琏'elif word in '紫鹃-鹦哥'.split('-'):word = '紫鹃'elif word in '翠缕-缕儿'.split('-'):word = '翠缕'elif word in '香菱-甄英莲'.split('-'):word = '香菱'elif word in '豆官-豆童'.split('-'):word = '豆官'elif word in '薛蝌—邢岫烟'.split('-'):word = '薛蝌'elif word in '薛蟠—夏金桂'.split('-'):word = '薛蟠'elif word in '贾宝玉-宝玉'.split('-'):word = '贾宝玉'elif word in '林黛玉-林姑娘-黛玉'.split('-'):word = '林黛玉'if word not in names:continuecounts[word] = counts.get(word, 0)+1
最后我们将数据排序整理一下
# 将人名按照次数排序 降序
items = list(counts.items())
# 排序规则 以次数为参考进行排序
items.sort(key=lambda x: x[1], reverse=True)
完整代码如下:
import jieba# 读取红楼梦的文本内容
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
# 运用jieba库对文本内容进行分词
words = jieba.lcut(txt)
# 初始化count字典 用于存放人名出现频率
counts = {}
# 读取红楼梦人名信息
names = open('人名.txt', 'r', encoding='utf-8').read().split('、')
# 对分词数据进行筛选 将不需要的数据跳过 只保存有效数据
for word in words:if len(word) == 1:continueelif word == '贾母' or word == '老太太':word = '贾母'elif word in '贾珍—尤氏'.split('—'):word = '贾珍'elif word in '贾蓉—秦可卿'.split('-'):word = '贾蓉'elif word in '贾赦—邢夫人'.split('-'):word = '贾赦'elif word in '贾政—王夫人'.split('-'):word = '贾政'elif word in '袭人-蕊珠'.split('-'):word = '袭人'elif word in '贾琏—王熙凤'.split('-'):word = '贾琏'elif word in '紫鹃-鹦哥'.split('-'):word = '紫鹃'elif word in '翠缕-缕儿'.split('-'):word = '翠缕'elif word in '香菱-甄英莲'.split('-'):word = '香菱'elif word in '豆官-豆童'.split('-'):word = '豆官'elif word in '薛蝌—邢岫烟'.split('-'):word = '薛蝌'elif word in '薛蟠—夏金桂'.split('-'):word = '薛蟠'elif word in '贾宝玉-宝玉'.split('-'):word = '贾宝玉'elif word in '林黛玉-林姑娘-黛玉'.split('-'):word = '林黛玉'if word not in names:continuecounts[word] = counts.get(word, 0)+1# 将人名按照次数排序 降序
items = list(counts.items())
# 排序规则 以次数为参考进行排序
items.sort(key=lambda x: x[1], reverse=True)
# print(items)
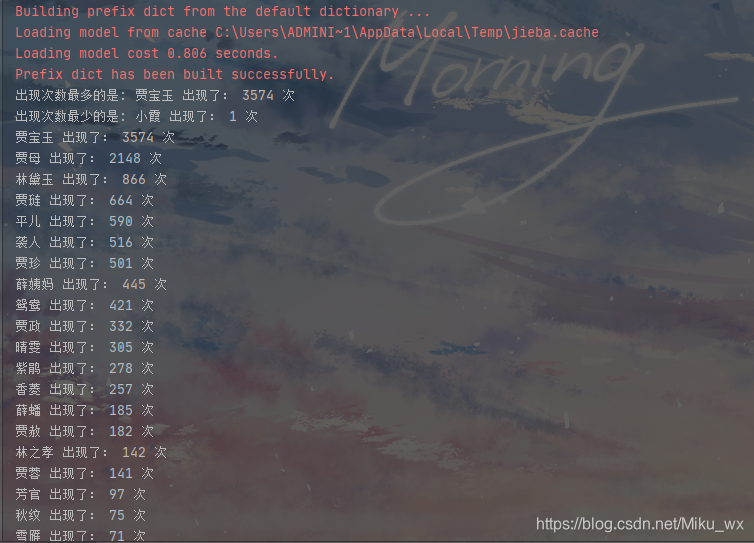
print('出现次数最多的是:', items[0][0], '出现了:', items[0][1], '次')
print('出现次数最少的是:', items[-1][0], '出现了:', items[-1][1], '次')
for item in items:print(item[0], '出现了:', item[1], '次')
效果图如下:
Python问题解答私信我
这篇关于Python 中文词频分析——红楼梦人物出场次数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




