本文主要是介绍深度剖析resnet究竟干了一件什么事?(从理论到代码详解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
resnet究竟干了一件什么事?
首先resnet解决了梯度弥散(也就是梯度爆炸的问题),但是resnet出现的原因并不是为了解决梯度弥散的情况(顺手解决,哈哈),而有更深层次的原因。
想必大家一定都已经听说过了大名鼎鼎的resnet了。那么resnet究竟是干了一件什么事呢?为什么网络假如残差效果就会变好了呢?本文将详细探讨一下。
开篇先说一下我自己的直观感受,我起初看了resnet以后我觉得之所以resnet会SOTA,其原因就是由于网络的加深最后面的feature_map可能丢失了比较小的信息(也就是低级的语义特征),而这种shortcut的结构可以将浅层的语义特征与深层的语义特征相结合,所以自然就会work了。(类似的FPN,SSD等都采用了这种思考方式。不清楚的可以看我的这两篇文章)
还有一个理解也是建立在上述观点的基础上的,resnet将浅层的语义特征与深层的语义特征融合就一定会work吗?为什么会work呢?我的理解就是,由于融合网络就可以去决定我想学浅层的还是深层的信息,相当于更加灵活和自适应的感觉。(毕竟玄学炼丹么,哈哈,纯属个人理解。)
WHY?
下面开始我们真正的Resnet。
起初是作者发现了意见奇怪的事,随着网络身的的加深,我们的学习效果居然越来越差了???这就变得很不科学了,理论上网络越深,对特征的认识应该越来越好啊,最差也应该与前面网络持平吧。

所以,开始猜测会不会是出现了下面两个问题。
神经网络的训练过程中的两大问题就是:
1、过拟合,欠拟合。
2、梯度消失(梯度弥散),梯度爆炸。
过拟合确实是有可能的,但是过拟合的表现是高方差低偏差,训练集效果好,测试集效果差,这与上面明显不合(上图显示训练集上面的效果也很差)。
梯度消失,梯度爆炸我们使用relu函数和BN已经基本解决了这两个问题,也不可能啊。
作者给出来的解释是模型退化。但是这却是不符合常理的。
按理说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。
然而事实上,这却是问题所在。“什么都不做”恰好是当前神经网络最难做到的东西之一。
为什么呢?其实是由于激活函数的存在,激活函数的作用是什么呢?就是然我们的线性模型变得可以拟合非线性。由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的(信息损失)。我们很难从输出反推回完整的输入。
也许赋予神经网络无限可能性的“非线性”让神经网络模型走得太远,却也让它忘记了为什么出发(想想还挺哲学)。这也使得特征随着层层前向传播得到完整保留(什么也不做)的可能性都微乎其微。(这时候知道不忘初心的重要性了吧!!!)
resnet的设计直觉是:较深的网络模型的表现效果不应该比较浅的网络模型的表现效果要差,但是实际上这是建立在网络深度的加深是通过恒等的线性映射实现的,但是我们的网络由于有激活函数的存在,所以基本上是非线性映射,这样的话,就很难有恒等映射的情况出现。所以Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
同时,resnet可以看做是很多条路径的集合,通过研究resnet的梯度流可以发现,网络在训练期间只有短路经才会产生梯度流,深的路径不是必须的。实验证明,resnet网络中的有效路径正是这些短的路径,且有效路径占总体路径的数量很少,加入训练中只保留有效路径的话,其在top5上的错误率几乎与整体是持平的。
所以Resnet不是通过让梯度流通整个网络深度来解决梯度消失的问题,而是通过引入能够在非常深的网络中传输梯度的短路径来缓解梯度消失的问题。
总的来说,resnet就是通过假如short cut的结构改进了传统神经网络在随着网络深度加深时,梯度在逐层传播的过程中逐渐衰减的问题。
Resnet的改进变体:
首先,resnet的第一个改进就是relu激活函数的位置,由原来的先addition再relu变成了现在的先relu再addition。
接下来我们套路残差部分假如BN层的结构:
先看一组图:
你知道哪一个才是我们熟知的Resnet呢?

其中weight指conv层,BN指Batch Normalization层,ReLU指激活层,addition指相加;
根据ResNet的描述,似乎以上五组都符合,那么2016年ResNet原文是哪一个结构呢?以及其他四组结构也都work么?我们不禁有了这两个疑问,伴随着疑问我们一一揭开谜题;
针对第一个问题,ResNet原文中使用的结构是(1),(1)的特点有两个:
1)BN和ReLU在weight的后面;
2)最后的ReLU在addition的后面;
对于特点1),属于常规范畴,我们平时也都这个顺序:Conv->BN->ReLU;对于特点2),为什么ReLU放在addition后面呢?按照常规,不是应该是图(3)这种么,那么我们接下来引出的问题就是:
图(3)的结构work么?
对于每个图右侧部分我们称作“residual”分支,左侧部分我们称作“identity”分支,如果ReLU作为“residual”分支的结尾,我们不难发现“residual”分支的结果永远非负,这样前向的时候输入会单调递增,从而会影响特征的表达能力,所以我们希望“residual”分支的结果应该在(-∞, +∞);这点也是我们以后设计网络时所要注意的。
对于图(3)不OK的情况,那如果把BN也挪到addition后面呢?如图(2),同时也保证了“residual”分支的取值范围;
这里BN改变了“identity”分支的分布,影响了信息的传递,在训练的时候会阻碍loss的下降;这里大家肯定又有个问题:
为什么“identity”分支发生变化,会影响信息传递,从而影响训练呢?
这是resnet的公式:

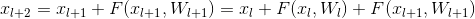
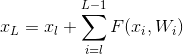
然后我们看一下反向传递的过程:
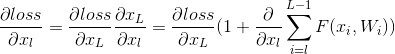
这个反向传播公式有几个特点:
(1)关于xl的梯度信息与两部分值有关:x_L的梯度值,也就是说两层之间梯度信息无障碍传递了,以及
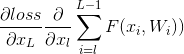
(2)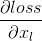 的值不会轻易的被抵消,因为在一个mini-batch中
的值不会轻易的被抵消,因为在一个mini-batch中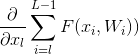 不会一直为-1.
不会一直为-1.
(3)有效的防止了当权重很小时,梯度消失的问题。
所以ResNet要尽量保证两点:1)不轻易改变”identity“分支的值,也就是输入与输出一致;2)addition之后不再接改变信息分布的层;
所以BN不能出现在addition后面,所以(2)不正确。
那么(4)和(5)呢?
通过实验对比发现(5)的效果更好一点。。。。
图5的结构好的原因在于两点:1)反向传播基本符合假设,信息传递无阻碍;2)BN层作为pre-activation,起到了正则化的作用;
所以图5就是我们俗称的Resnetv2,也就是在传统resnet的基础上,在residual分支前面加入了BN和relu,还有就是将addition后面的relu放到了addition前面

二、深度残差学习 Deep Residual Learning
下面是resnet的基本结构

图中右侧的曲线叫做跳接(shortcut connection),通过跳接在激活函数前,将上一层(或几层)之前的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。
看一下数学表达式,其实也很简单:
y = F ( x , { W i } ) + x \mathbf{y}=\mathcal{F}\left(x,\left\{W_{i}\right\}\right)+x y=F(x,{Wi})+x
F = W 2 σ ( W 1 x ) \mathcal{F}=W_{2} \sigma\left(W_{1} x\right) F=W2σ(W1x)
这里的 σ \sigma σ就是激活函数relu, F ( x , { W i } ) \mathcal{F}\left(x,\left\{W_{i}\right\}\right) F(x,{Wi})就是我们的学习目标,即输出输入的残差 y − x y-x y−x。输入是x。
注意这里的一个Block最少要有两个卷积层!!!自己写一下公式就知道为啥了。
resnet就是从vgg变化而来的,所以我们下面对照的看一下。

shortcut(也就是跳接的那些线)的曲线中大部分是实线,但也有少部分虚线。这些虚线的代表这些Block前后的维度不一致,因为去掉残差结构的Plain网络还是参照了VGG经典的设计思路:每隔x层,空间上/2(下采样)但深度翻倍。
也就是说,维度不一致体现在两个层面:
空间上不一致
深度上不一致
空间上不一致很简单,只需要在跳接的部分给输入x加上一个线性映射Ws,即:
y = F ( x , { W i } ) + x → y = F ( x , { W i } ) + W s x \mathbf{y}=\mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right)+\mathbf{x} \quad \rightarrow \quad \mathbf{y}=\mathcal{F}\left(\mathbf{x},\left\{W_{i}\right\}\right)+W_{s} \mathbf{x} y=F(x,{Wi})+x→y=F(x,{Wi})+Wsx
深度上的不一致,图中黄字写的两种办法都行,我们一般用1x1的卷积来实现。
原理基本上就讲完了,下面来说一下代码:
说代码之前看一下网络结构,代码基本也就懂了。这里给出的pytorch的实现,tensorflow也差不多。
import torchvision
model = torchvision.models.resnet18(pretrained=False) #我们不下载预训练权重
print(model)
可以看得出来,下采样也就是1x1卷积出现在channel纬度发生变化的时候。
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)(fc): Linear(in_features=512, out_features=1000, bias=True)
)
下面给出pytorch的代码:
这里需要再说两点。
1、resnet有两种残差实现,左边这种适用于res18,res34,右边这种用在res50,res101,res152,下面代码中可以清楚的看到。
2、左边都是这种结构
out = self.conv1(x)out = self.bn1(out)out = self.relu(out) #一次卷积,防爆,激活out = self.conv2(out)out = self.bn2(out) #第二次卷积,防爆if self.downsample is not None: #当连接的维度不同时,使用1*1的卷积核将低维转成高维,然后才能进行相加identity = self.downsample(x) #就是在进行下采样,如果需要的话out += identity #这个时候就会用到残差网络的特点,f(x)+x # 实现H(x)=F(x)+x或H(x)=F(x)+Wxout = self.relu(out)
右边是这种结构
identity = x #shotcutout = self.conv1(x)out = self.bn1(out)out = self.relu(out) #1x1卷积out = self.conv2(out)out = self.bn2(out)out = self.relu(out) #3x3卷积out = self.conv3(out)out = self.bn3(out) #1x1 归一#不管是BasicBlock还是Bottleneck,最后都会做一个判断是否需要给x做downsample,因为必须要把x的通道数变成与主枝的输出的通道一致,才能相加。if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return out

import torch
import torch.nn as nn
#from .utils import load_state_dict_from_url#其中torch.nn 为其提供基础函数,model_zoo提供权重数据的下载。
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101','resnet152', 'resnext50_32x4d', 'resnext101_32x8d','wide_resnet50_2', 'wide_resnet101_2']
#ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。model_urls = {'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth','resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth','resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth','resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth','resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth','resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth','resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth','wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth','wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
#groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
# dilation=1(也就是 padding) groups 是分组卷积参数,这里 groups=1 相当于没有分组 第一个3*3的主要作用是在以后高维中做卷积提取信息,第二个1*1的作用主要是进行升降维的。
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):"""3x3 convolution with padding"""return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=dilation, groups=groups, bias=False, dilation=dilation)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)#注意:这里bias设置为False,原因是:下面使用了Batch Normalization,而其对隐藏层 有去均值的操作,所以这里的常数项 可以消去
# 因为Batch Normalization有一个操作,所以上面的数值效果是能由所替代的,因此我们在使用Batch Norm的时候,可以忽略各隐藏层的常数项 。这样在使用梯度下降算法时,只用对 , 和 进行迭代更新
#BasicBlock是为resnet18、34设计的,由于较浅层的结构可以不使用Bottleneck。
class BasicBlock(nn.Module):expansion = 1__constants__ = ['downsample']def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None):super(BasicBlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2d # #BatchNorm2d最常用于卷积网络中(防止梯度消失或爆炸),设置的参数就是卷积的输出通道数#计算各个维度的标准和方差,进行归一化操作if groups != 1 or base_width != 64:raise ValueError('BasicBlock only supports groups=1 and base_width=64') #为什么要设置这些限制if dilation > 1:raise NotImplementedError("Dilation > 1 not supported in BasicBlock")# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = conv3x3(inplanes, planes, stride) #卷积操作,输入通道,输出通道,步长self.bn1 = norm_layer(planes) #防止梯度爆炸或消失,planes就是卷积一次之后的输出通道数?为什么要对输出的通道数进行防爆呢self.relu = nn.ReLU(inplace=True) #inplace为True,将会改变输入的数据 ,否则不会改变原输入,只会产生新的输出。self.conv2 = conv3x3(planes, planes) #conv层的时候通道数是一样的都是64的倍数,但是下一层的时候会改变,所以这里用了inplaces和planes两个变量self.bn2 = norm_layer(planes)self.downsample = downsample #下采样self.stride = stride #步长
#解读:这个结构就是由两个3*3的结构为主加上bn和一次relu激活组成。其中有个downsample是由于有x+out的操作,要保证这两个可以加起来所以对原始输入的x进行downsample。def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out) #一次卷积,防爆,激活out = self.conv2(out)out = self.bn2(out) #第二次卷积,防爆if self.downsample is not None: #当连接的维度不同时,使用1*1的卷积核将低维转成高维,然后才能进行相加identity = self.downsample(x) #就是在进行下采样,如果需要的话out += identity #这个时候就会用到残差网络的特点,f(x)+x # 实现H(x)=F(x)+x或H(x)=F(x)+Wxout = self.relu(out)return out
#看到代码 self.downsample = downsample,在默认情况downsample=None,表示不做downsample,但有一个情况需要做,就是一个 BasicBlock的分支x要与output相加时,若x和output的通道数不一样,则要做一个downsample,
# 剧透一下,在resnet里的downsample就是用一个1x1的卷积核处理,变成想要的通道数。为什么要这样做?因为最后要x要和output相加啊, 通道不同相加不了。所以downsample是专门用来改变x的通道数的。class Bottleneck(nn.Module):#expansion 是对输出通道数的倍乘,注意在基础版本 BasicBlock 中 expansion 是 1,此时相当于没有倍乘,输出的通道数就等于 planes。expansion = 4 #一层里面最终输出时四倍膨胀__constants__ = ['downsample']def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None):super(Bottleneck, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dwidth = int(planes * (base_width / 64.)) * groups #这个值应该是变化的# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = conv1x1(inplanes, width) #with在这里应该是改变输入的维度self.bn1 = norm_layer(width)self.conv2 = conv3x3(width, width, stride, groups, dilation) #输入输出的通道一样self.bn2 = norm_layer(width)self.conv3 = conv1x1(width, planes * self.expansion)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = x #shotcutout = self.conv1(x)out = self.bn1(out)out = self.relu(out) #1x1卷积out = self.conv2(out)out = self.bn2(out)out = self.relu(out) #3x3卷积out = self.conv3(out)out = self.bn3(out) #1x1 归一#不管是BasicBlock还是Bottleneck,最后都会做一个判断是否需要给x做downsample,因为必须要把x的通道数变成与主枝的输出的通道一致,才能相加。if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,groups=1, width_per_group=64, replace_stride_with_dilation=None,norm_layer=None):super(ResNet, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dself._norm_layer = norm_layer #为什么这么做,是因为在make函数中也要用到norm_layer,所以将这个放到了self中self.inplanes = 64 #设置默认输入通道self.dilation = 1if replace_stride_with_dilation is None:# each element in the tuple indicates if we should replace# the 2x2 stride with a dilated convolution insteadreplace_stride_with_dilation = [False, False, False]if len(replace_stride_with_dilation) != 3:raise ValueError("replace_stride_with_dilation should be None ""or a 3-element tuple, got {}".format(replace_stride_with_dilation))self.groups = groupsself.base_width = width_per_groupself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,bias=False) #7x7 输入3 输出inplanes 步长为2 填充为3 偏移量为falseself.bn1 = norm_layer(self.inplanes) #归一化防爆self.relu = nn.ReLU(inplace=True) #激活函数替换self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) #最大池化3x3 步长为2 填充为1self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2,dilate=replace_stride_with_dilation[0])self.layer3 = self._make_layer(block, 256, layers[2], stride=2,dilate=replace_stride_with_dilation[1])self.layer4 = self._make_layer(block, 512, layers[3], stride=2,dilate=replace_stride_with_dilation[2])self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)# 对卷积和与BN层初始化,论文中也提到过for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# Zero-initialize the last BN in each residual branch,# so that the residual branch starts with zeros, and each residual block behaves like an identity.# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677if zero_init_residual:for m in self.modules():if isinstance(m, Bottleneck):nn.init.constant_(m.bn3.weight, 0)elif isinstance(m, BasicBlock):nn.init.constant_(m.bn2.weight, 0)#_make_layer 方法的第一个输入参数 block 选择要使用的模块是 BasicBlock 还是 Bottleneck 类,第二个输入参数 planes 是该模块的输出通道数,第三个输入参数 blocks 是每个 blocks 中包含多少个 residual 子结构。def _make_layer(self, block, planes, blocks, stride=1, dilate=False): #planes参数是“基准通道数”,不是输出通道数!!!不是输出通道数!!!不是输出通道数!!!)norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilation #填充?if dilate:self.dilation *= stridestride = 1if stride != 1 or self.inplanes != planes * block.expansion: #如果stride不等于1或者维度不匹配的时候的downsample,可以看到也是用过一个1*1的操作来进行升维的,然后对其进行一次BN操作downsample = nn.Sequential( #一个时序器conv1x1(self.inplanes, planes * block.expansion, stride),norm_layer(planes * block.expansion),)layers = [] #[3,4,6,3]表示按次序生成3个Bottleneck,4个Bottleneck,6个Bottleneck,3个Bottleneck。layers.append(block(self.inplanes, planes, stride, downsample, self.groups,self.base_width, previous_dilation, norm_layer)) #该部分是将每个blocks的第一个residual结构保存在layers列表中#这里分两个block是因为要将一整个Lyaer进行output size那里,维度是依次下降两倍的,第一个是设置了stride=2所以维度下降一半,剩下的不需要进行维度下降,都是一样的维度self.inplanes = planes * block.expansionfor _ in range(1, blocks): #该部分是将每个blocks的剩下residual 结构保存在layers列表中,这样就完成了一个blocks的构造layers.append(block(self.inplanes, planes, groups=self.groups,base_width=self.base_width, dilation=self.dilation,norm_layer=norm_layer))return nn.Sequential(*layers)
#ResNet 共有五个阶段,其中第一阶段为一个 7*7 的卷积,stride = 2,padding = 3,然后经过 BN、ReLU 和 maxpooling,此时特征图的尺寸已成为输入的 1/4
#接下来是四个阶段,也就是代码中 layer1,layer2,layer3,layer4。这里用 _make_layer 函数产生四个 Layer,需要用户输入每个 layer 的 block 数目( 即layers列表 )以及采用的 block 类型(基础版 BasicBlock 还是 Bottleneck 版)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x) #第一阶段进行普通卷积 变成原来1/4#其实所谓的layer1,2,3,4都是由不同参数的_make_layer()方法得到的。看_make_layer()的参数,发现了layers[0~3]就是上面输入的[3,4,6,3],即layers[0]是3,layers[1]是4,layers[2]是6,layers[3]是3。x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef _resnet(arch, block, layers, pretrained, progress, **kwargs):model = ResNet(block, layers, **kwargs)if pretrained:state_dict = load_state_dict_from_url(model_urls[arch],progress=progress)model.load_state_dict(state_dict)return modeldef resnet18(pretrained=False, progress=True, **kwargs):r"""ResNet-18 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,**kwargs)def resnet34(pretrained=False, progress=True, **kwargs):r"""ResNet-34 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,**kwargs)def resnet50(pretrained=False, progress=True, **kwargs):r"""ResNet-50 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,**kwargs)def resnet101(pretrained=False, progress=True, **kwargs):r"""ResNet-101 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,**kwargs)def resnet152(pretrained=False, progress=True, **kwargs):r"""ResNet-152 model from`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,**kwargs)def resnext50_32x4d(pretrained=False, progress=True, **kwargs):r"""ResNeXt-50 32x4d model from`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['groups'] = 32kwargs['width_per_group'] = 4return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],pretrained, progress, **kwargs)def resnext101_32x8d(pretrained=False, progress=True, **kwargs):r"""ResNeXt-101 32x8d model from`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['groups'] = 32kwargs['width_per_group'] = 8return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],pretrained, progress, **kwargs)def wide_resnet50_2(pretrained=False, progress=True, **kwargs):r"""Wide ResNet-50-2 model from`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_The model is the same as ResNet except for the bottleneck number of channelswhich is twice larger in every block. The number of channels in outer 1x1convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048channels, and in Wide ResNet-50-2 has 2048-1024-2048.Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['width_per_group'] = 64 * 2return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],pretrained, progress, **kwargs)def wide_resnet101_2(pretrained=False, progress=True, **kwargs):r"""Wide ResNet-101-2 model from`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_The model is the same as ResNet except for the bottleneck number of channelswhich is twice larger in every block. The number of channels in outer 1x1convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048channels, and in Wide ResNet-50-2 has 2048-1024-2048.Args:pretrained (bool): If True, returns a model pre-trained on ImageNetprogress (bool): If True, displays a progress bar of the download to stderr"""kwargs['width_per_group'] = 64 * 2return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],pretrained, progress, **kwargs)这篇关于深度剖析resnet究竟干了一件什么事?(从理论到代码详解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!