本文主要是介绍Intend Classification Engine,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Data & Code
数据下载:
链接: https://pan.baidu.com/s/19WEMuPRQVP4yRMO6xJeLPg 提取码: uehm 复制这段内容后打开百度网盘手机App,操作更方便哦
写在前面,文中可能提及evaluation、test、validation,这里的evaluation和test是同一个意思都是测试集,validation是验证集,在ICEv4的baseline中是没有validation的只有test。也就是直接训练完模型后看模型在test上的表现(test是有标签的)。
文件结构:
.
├── train_test_data
├── newest_train_with_norm
├── newest_validation_with_norm
├── DNN_multi_gpu_v4.py
├── label_dict.json
├──LoadData_TfidfFeature.py
其中DNN_multi_gpu_v4.py是主函数,使用的train和test数据分别在newest_train_with_norm和newest_validation_with_norm中。在主函数中使用了LoadData_TfidfFeature.py将一个query各个词的tfidf填充到355001大小的vector中输入给DNN模型。
newest_train_with_norm中数据有trainSmall0.txt ~ trainSmall447.txt共448个文件,每个文件有15000个样本(除了最后一个文件trainSmall447.txt有4595样本),每个样本是一行。文件太多共30多G,我这里就放了一个文件。
newest_validation_with_norm数据是有标签的,预测完数据后自动调用函数输出top1 accuracy。label_dict.json为标签的词典。
ICEv4数据介绍
ICEv4是0.47的baseline,使用的数据如下所示。
以trainSmall0.txt第一行举例:
2043802 12124:1,10857:2,10163:2,10018:2 15:0.05182752845352 26:0.0544780513904204 72:0.0583115046118085 ...
文件使用\t作为分割,第一列2043802为行的id,第二列12124:1,10857:2,10163:2,10018:2中12124为标签,后面带:2的都是标签的父节点或者爷爷节点等。第三列15:0.05182752845352 26:0.0544780513904204 72:0.0583115046118085中第一对数字15为token的id,第二个数字0.05182752845352为该token在当前query的tfidf值。后面的数字对也是这样的意思。
我使用的数据
train_test_data中是我目前使用的所有的数据包括训练数据和测试数据。
以step2.trainMerge_multi_label_high_quality_repeat_resort_docid.txt第一行举例:
5784078 12699 rfid:0.24798 implant:0.16931 obamacare:0.25705 ...
和ICEv4不同之处就是我把query的数字对的第一个数字换成了真实的token。同样都是以\t分隔,第一列是样本的唯一id。第二列是样本的label,有的数据有多个label。第三列就是各个token和token对应的tfidf。
我的实验
DNN的baseline是0.47~0.48左右,我用bert做了几个实验,其中set1就是部分训练数据,set1+set2是所有训练数据,WordPiece是官方的bert分词,Term feature是用空格分词(30w词表)。bert做的几个实验如下所示:
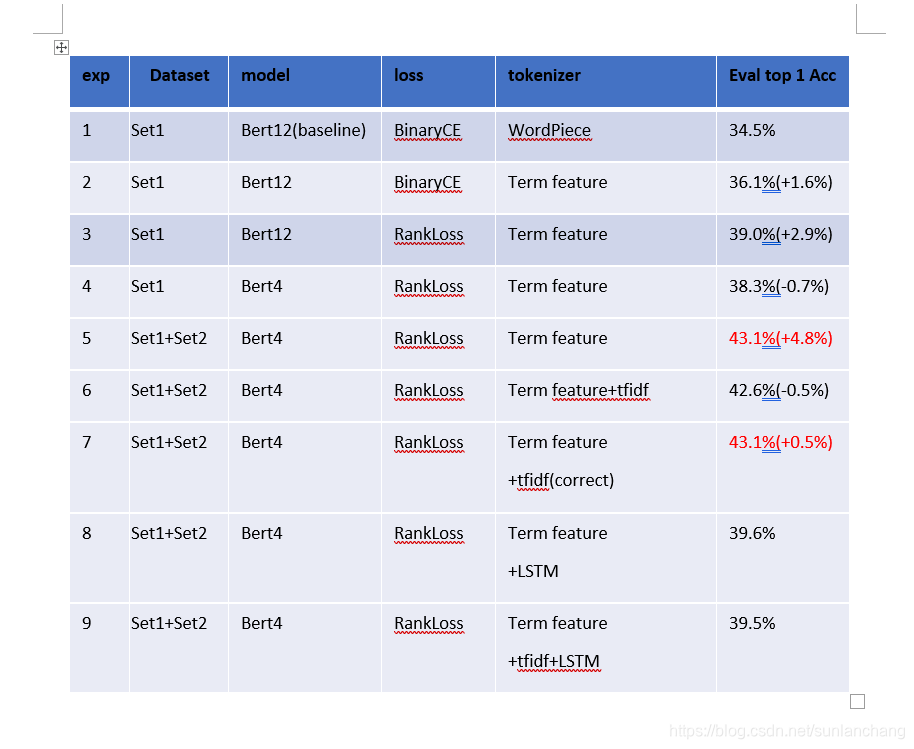
- 实验8在Bert之后加入LSTM效果变差了。实验9是先在bert后每个位置乘上了相应的tfidf值,再用LSTM效果相对与exp8低了0.1%
这篇关于Intend Classification Engine的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








