本文主要是介绍光芒绽放:妙用“GLAD原则”打造标准的数据可视化图表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
光芒绽放:妙用“GLAD原则”打造标准的数据可视化图表
文章目录
- 光芒绽放:妙用“GLAD原则”打造标准的数据可视化图表
- 前言
- 一、可视化工具有哪些?
- 二、那如何做出正确可视化图表 ?GLAD原则
- 1.G原则
- 2.L原则
- 3.A原则
- 4.D原则
- 三、总结
- 最后
前言
之前读过一本书《人类简史:从动物到上帝》。是 1976年出生的赫拉利写的,在2016年我读了中文版 。该书在2011年出版的希伯来文版,另外还被翻译为45种语言。里面有一句经典的话是这么说的。
人类不了解自己,只好让科技替自己做决定。
也说到了关于数据和技术的深远影响
这个也是坚定我走数据这条路的原因。大家可以去看看。
一、可视化工具有哪些?
以下一些工具是比较常见的 可视化工具了,大家了解下(来源搜索引擎)
- Tableau: 一款功能强大的商业智能工具,支持创建交互式和高度定制化的可视化。
- PowerBI和Excel :微软推出的业务分析工具,能够将数据转化为丰富的报表和仪表板。
- Google Data Studio:谷歌的可视化工具,可以连接多种数据源,创建仪表板并与他人共享。
- D3.js:一个基于JavaScript的数据驱动文档库,用于创建动态和交互式的数据可视化。
- Matplotlib: 一个用于绘制静态、动态和交互式图表的Python库,特别适用于数据科学领域。
- Plotly:一个支持多种语言(包括Python、R和JavaScript)的绘图库,用于创建交互式图表。
- Infogram:一个在线可视化工具,适用于创建各种图表、图形和地
- QlikView/Qlik Sense:用于创建交互式仪表板的商业智能工具,支持实时数据析。
- Highcharts:一款用于创建交互式图表的JavaScript图表库。
- Chart.js:轻量级的JavaScript图表库,适用于在网页上创建简单的图表。
- Superset:Apache Superset是一个现代的数据探索和可视化平台。它功能强大且十分易用,可对接各种数据源,包括很多现代的大数据分析引擎,拥有丰富的图表展示形式,并且支持自定义仪表
在中国用的比较多的有
- 百度数据图谱: 百度推出的在线数据可视化工具,支持用户通过简单的拖拽操作创建各种图表.
- DataV 数据可视化: 阿里巴巴旗下的产品,提供丰富的可视化组件,支持实时数据展示、数据分析和仪表盘设计。
- 图格易达: 提供数据可视化、图表制作等服务,支持多种图表类型和数据源。
- FineReport/FineBI: 功能强大的报表和数据可视化工具,支持多种图表类型,适用于企业级数据分析和报告制作。
- 云图: 专注于大数据可视化的公司,提供可视化分析、数据展示等服务。
- 易观方舟: 主要用于移动应用数据分析和可视化,帮助企业更好地理解用户行为和趋势。
- smart BI:
- 观远 BI :
二、那如何做出正确可视化图表 ?GLAD原则
最近在 学习帆软BI,学到了GLAD原则分享给大家

GLAD原则是什么?
Good data and insight—需要好的数据和洞察
Less Nosie----去掉噪音和干扰因素
Accurate expression ----需要准确的表达
Distinct Mark —(突出分析重点 )

1.G原则
这个其实大家很好理解
所有的数据分析层次分一般分为几种
描述型分析:比如数据监控,比如上线一个新产品看产品状态
预测型分析:就是很来理解,比如回归,预测未来的销售额
诊断性分析:也很好理解,就是比如 有个销售员,通过各种维度和指标的分析,分析哪个销售更优秀。
指导型分析:通过分析,指导运营做业务决策,发挥更好的商业价值
- 需要满足MECE 原则 ,也就是 不重复,不遗漏,数据是否使用适当
比如 下面的图看出什么 ?
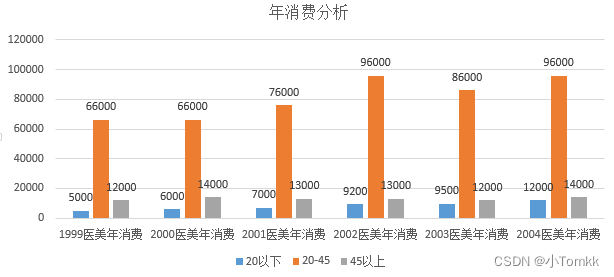
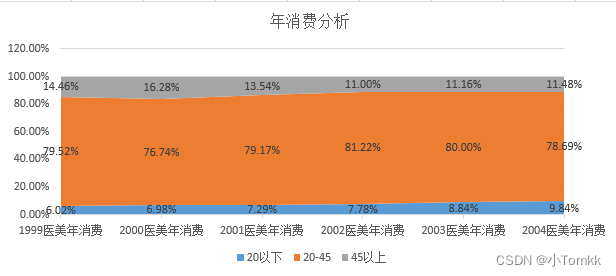
那如果换一个思路呢? 下图可以看出 20岁以下的医美人数每年占比趋势在增加。
2.L原则
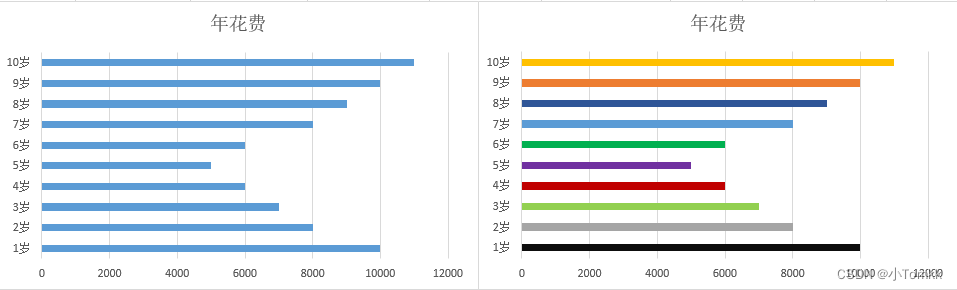
- 图表颜色降噪
图1正确,图2错误
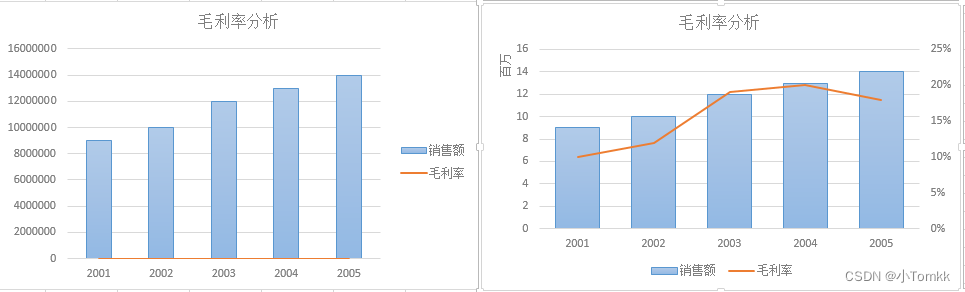
- 辅助信息降噪1
图1错误,图2正确(单位改为百万,双坐标)
- 辅助信息降噪2
图1错误,图2正确
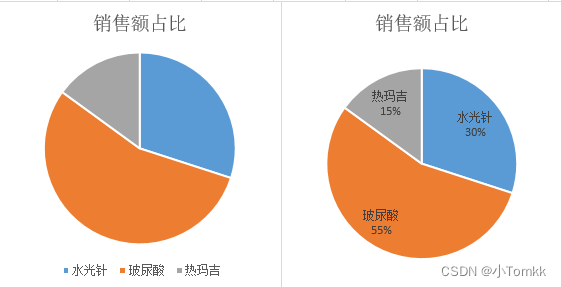
3.A原则
-
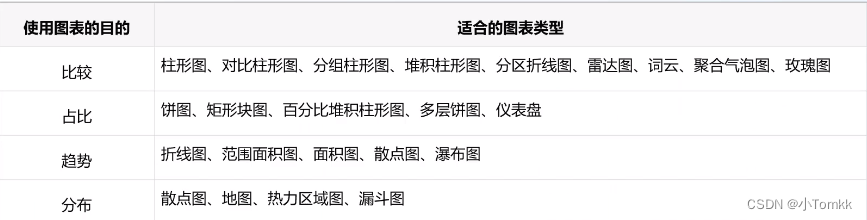
根据分析目的使用适合的图表
-
数据密度是否适合,数据密度小
图1错误,图2正确
图1
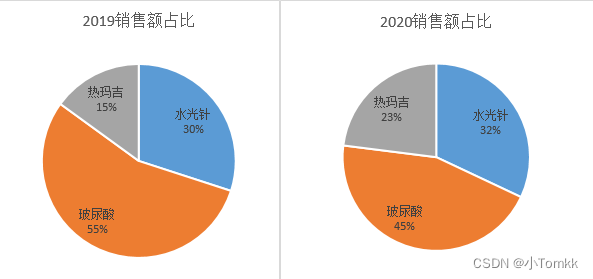
图2

-
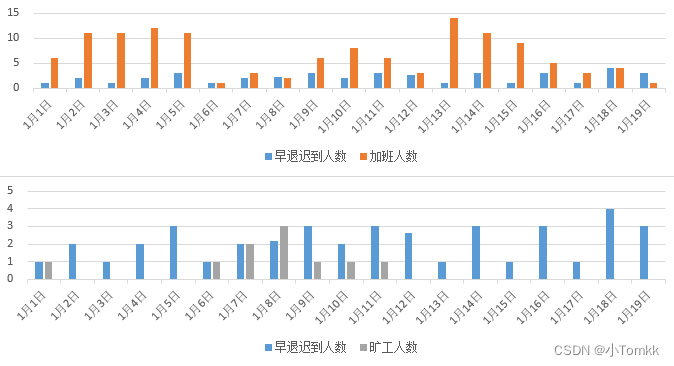
数据密度是否适合,数据密度大
图1错误,指标要多
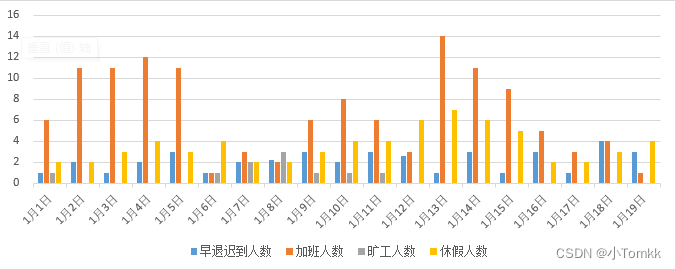
图2正确 (分2个图显示)
-
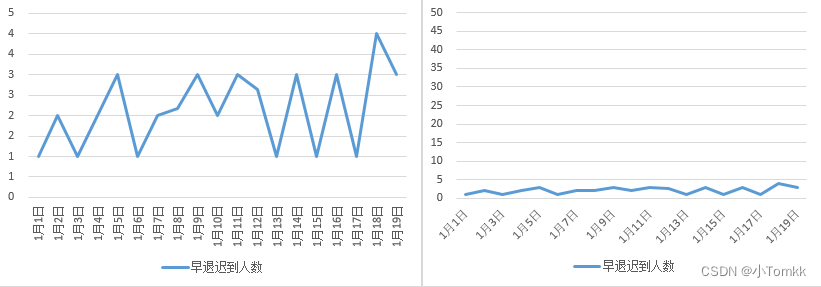
显示效果是否表达准确,坐标轴失真
图1正确 图2错误(坐标轴太大)
- 显示效果是否表达准确,过渡装饰
图1正确 图2错误(没有必要)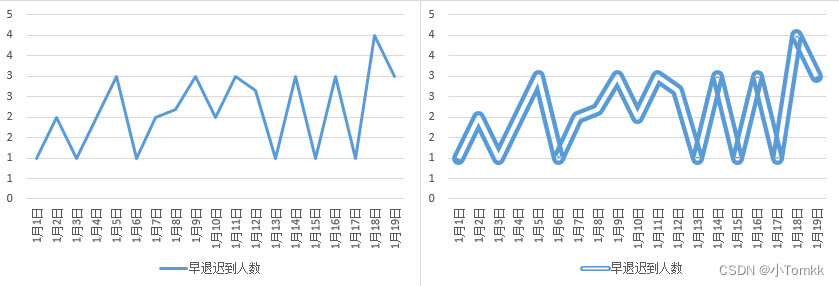
4.D原则
- 画龙点睛-打造视觉反差

-
画龙点睛-打造视觉反差

-
画龙点睛-是否突出的洞察标识(加入平均线)
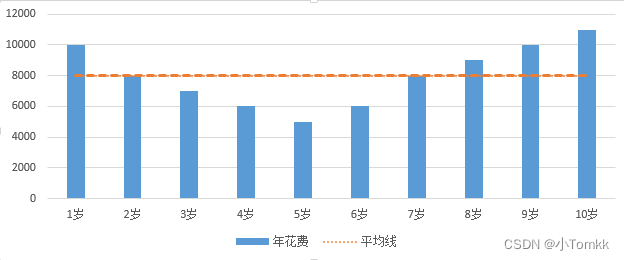
-
画龙点睛-是否突出重点
三、总结
本文 的GLAD原则 介绍主要来自《 乐见数据:商业数据可视化思维》一书马世权老师的书,大家可以去读一下。写技术博客也是一样是一种累计,需要写一些对自己或者对他人用的。如果你是数据分析师,是数据产品,是数据开发,或者是从事数据相关的工作或许上面文章对你有帮助。
最后
希望这个GLAD原则 ,对大家作可视化分析有帮助 。
一键三连,心想事成。
这篇关于光芒绽放:妙用“GLAD原则”打造标准的数据可视化图表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







