本文主要是介绍属性图社区搜索--QD-GCN(Query-Driven Graph Convolutional Networks for Attributed Community Search),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.什么是ACS(attributed community search)
- 对于给定的查询节点 (节点+该节点的属性),找出其所属社区

2.ACS问题–传统方法
- 传统方法
传统方法分两步执行
1)structural matching:找出查询节点的候选社区结构
2)attribute filtering:优化属性函数,来缩小或筛选第一步选出的社区 - 缺点
1)将结构和属性分开处理,忽略结构和属性关联,现实世界的社区结构和属性是有关系的
2)传统社区搜索基于预定义的子图(先根据如下标准:k-core,k-truss,k-clique,k-edge connected component选出子图),但是现实世界中的图不能很好的严格满足这些标准
3)属性独立处理(例如GCN和GNN是相似的,传统的方式认为是完全不相关的两个词)
3.ACS问题–本文提出的方法(QD-GCN)
- QD-GCN方法介绍
design four learning components for different learning tasks
1)graph encoder
学习整张图的结构和属性特征(both structure and attribute of entire graph),input图的邻接矩阵A和特征矩阵F,产生graph embedding
2)structure encoder
学习与特定查询相关的局部结构特征(query-specific local structural features),为查询节点提供接口,学习查询节点局部特征,产生查询节点的映射 query-specific structural embedding
3)attribute encoder
学习查询节点相关的属性特征,为查询属性提供接口,产生query-specific attribute embedding
并基于属性结构二分图考虑属性的相似性。
4)feature fusion
融合上述三个编码器的输出,并获得最终的查询输出。融合的特征在训练过程中,也会传给结构和属性编码器

- 创新点
1)提出QD-GCN,能同时考虑社区结构和节点属性(解决了传统两阶段方法的问题)
2)对GCN进行改进,使其能支持查询操作(对于不同的查询节点,能输出其对应社区)
3)预测任意查询节点的社区·
4.ACS问题整体思路
- 设计一个基于监督式的模型,优化损失函数学习参数(模型输出 model output 和 真实值 lable)
- 训练集:查询节点(节点+属性)和 每个查询节点对应的社区结构 label
- output:根据训练好的模型,输出查询节点的所属社区
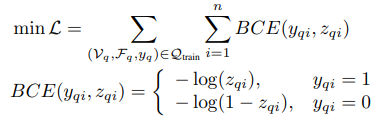
图注:训练数据
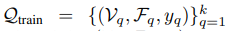
图注:指示向量,如果查询节点Vi在真实的社区中,则第i行为1
标签不应该为该节点所属社区的向量表示吗??然后和模型预测的社区结构算损失,反向传播优化
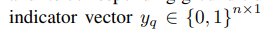
图注:对于查询节点,模型输出的向量
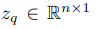
5.预备知识-GCN
- 每一层的信息传播规则
前一层的学习到的节点特征,乘可训练的权重矩阵W,乘归一化后的矩阵(目的为了提取邻居节点和自身的信息),再通过激活函数非线性变换,和传统神经网络差不多,只是针对图结构加了一个信息提取的矩阵
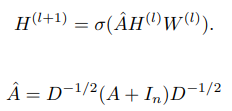
图注:分解上述公式–具体节点的学习过程,聚合前一层节点本身特征和邻居节点特征
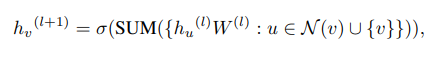
6.QD-GCN实现细节
-
Graph Encoder
输入邻接矩阵A和节点特征矩阵F,H矩阵初始化为按行归一化的特征矩阵F N×d
图注:传统GCN每层前向传播+self feature modeling +bias(对邻居特征及自身特征聚合,来学习每个节点表示)
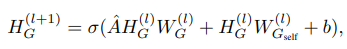
图注:最后一层编码器输出的graph embedding不用送进激活函数,因为fusion encoder有激活函数,其余两个编码器的embedding最终输出也不用送到激活函数
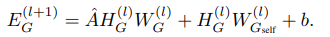
-
Structure Encoder
输入邻接矩阵A和查询节点矩阵I,为查询节点提供接口,(学习每个节点基于查询节点集的表示)

图注:信息传播方式
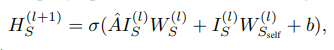
如何输入查询节点集到上式中,如何根据查询节点集学习每个节点的表示?
最短路径能反映任意节点到查询节点集的紧密程度,求每个节点到查询节点集的最短路径初始化矩阵I(每个节点到查询节点集的紧密程度),值越大说明节点离查询节点集合越近,其属于一个社区的可能性越大

I初始化为节点到查询节点集的最短路径长度,之后把融合编码器的输出作为输入
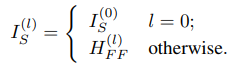
最终的structure embedding
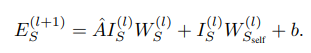
-
Attribute Encoder
提供查询属性接口,节点属性矩阵F和查询节点的属性矩阵Fq作为输入,(基于查询属性,产生每个节点的嵌入向量)
因为最终所查询的社区是节点的集合,所以需要将属性表示成节点形式(将属性和节点之间建立关系),构造structure-attribute bipartite graph,构造二分图的邻接矩阵(F是节点和属性的特征矩阵), 如果两个属性公共节点多,则属性更接近(能捕获属性之间的相似性)
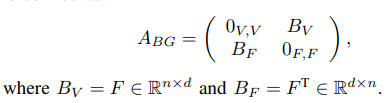
节点属性二分图卷积网络(Bipartite Graph Network)
目的:基于属性学习节点的嵌入向量
1)图注:为了将查询属性输入,将查询属性表示成one-hot形式d×1,用查询属性one-hot矩阵初始化IV,之后把属性侧的输出,作为节点侧的特征输入。0层每个节点先对于自身属性中,包含的所有查询属性聚合(既是自己的属性∩又又在查询属性集合中),这样每个节点在查询属性集合中的数量越多,此节点的权重越大(意味着学习到了每个节点基于查询属性的嵌入)

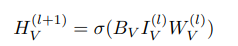
2)图注:二分图属性侧特征学习过程,用查询属性的one-hot编码,初始化矩阵IF,

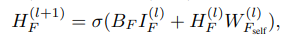
图注:二分图节点和属性学习过程,最终产生基查询属性的节点向量嵌入
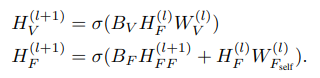
图注:去掉属性编码器最后一层激活函数,送入fusion encoder
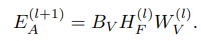
- Feature Fusion
聚合前面三个Encoder输出的embedding,AGG为聚合函数(例如sum),为了考虑结构和属性的关系,中间层将融合的特征输入到结构和属性编码器。
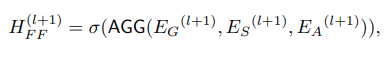
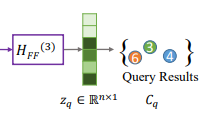
fusion encoder的最后一层输出融合前面三个编码器的各节点嵌入向量,将权重大(向量大)的节点划分为一个社区
7.论文实验
- 对比实验
1)对比两个非属性社区搜索算法(CTC,K-ECC),以及两个属性社区搜索算法(ACQ,ATC)
CTC:先找出包含查询节点集的k值最大的k-truss结构,然后移除离查询节点远的点和边
K-ECC:找出包含查询节点的k-edge connected component
ACQ:先找包含查询节点的k-core,然后筛选包含查询属性最多的k-core
ATC:先找包含查询节点的k-truss,然后通过属性评分函数对k-truss评分,筛选
2)自身对比,验证每个组件的必要性
3)聚合函数对比实验
4)输出层阈值r对比实验
通过四个编码器,有效的提取了全局特征和局部特征,以及查询节点和查询属性(将这些特征映射在节点的向量表示中),然后进行下游任务社区搜索(根据阈值 r 选择节点向量中数值大的几个点作为一个社区)
这篇关于属性图社区搜索--QD-GCN(Query-Driven Graph Convolutional Networks for Attributed Community Search)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



