本文主要是介绍今日arXiv最热NLP大模型论文:智能谈判Agent综述,一文读懂谈判桌上的人工智能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
谈判,就是大家坐下来聊聊,看怎么能达成共识,共同解决问题。可以是朋友间的闲聊,也可以是国与国之间的外交场合。
但谈判这事儿,说简单也不简单。人们往往会带着偏见和情绪,忽略了别人的好建议,导致结果不尽如人意。而且,谈判也是门技术活,不是谁都能轻易搞定的。
为了促进人类谈判过程,研究者们提出了智能谈判Agent,能够在多轮互动中辅助人类甚至直接与人类进行谈判。一个典型的谈判对话涉及到Agent和人类之间的多轮互动,彼此交换交易信息,并最终接受或拒绝交易,如下图所示:
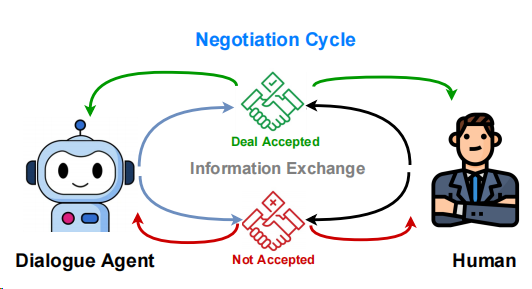
现在有了谈判Agent,就像请了个私人顾问,从买菜砍价到处理复杂的政治或法律事务,它都能给你支招。
以后吵架就带谈判Agent去,嘴笨的人有救了:“在我的Agent来之前,我是不会说一句话的。”

或许有小伙伴对谈判Agent不太熟悉,想进一步了解其中的门道,今天小编就给大家带来一篇关于谈判对话系统的综述,包括数据集、评估指标和建模方法等维度。一起来看看~
论文标题:
Let’s Negotiate! A Survey of Negotiation Dialogue Systems
论文链接:
https://arxiv.org/pdf/2402.01097.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
1. 人类谈判的理解与局限性
人类谈判的框架与过程
谈判者的偏好和策略共同塑造了谈判的潜在结果与互动过程,如下图所示。双方的偏好共同构成了可能达成的协议范围,而谈判策略,作为一种目标导向的行为,在影响互动的同时,最终决定了谈判者偏好所能实现的潜在结果的数量和质量。
简言之,偏好设定了可能的结果范围,而策略则在这个范围内决定了实际达成的结果。
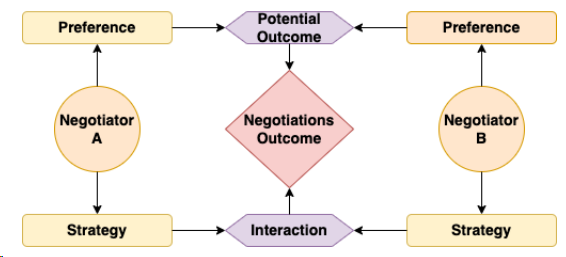
谈判中的人类局限性
谈判,尽管在日常生活中随处可见,如讨价还价等,但仍是一项充满挑战的任务。未经专业培训,许多人往往缺乏实现其期望目标的谈判技巧,不清楚应运用何种策略以及如何实施这些策略,因此人类谈判往往有以下难点:
-
在谈判中,准确识别和处理其他谈判者兴趣和偏好的隐含信息是比较困难的事。很多时候,谈判被视为一种竞争,这可能导致人们缺乏寻求或表达这些信息的动力。
-
人类的认知启发式、偏见和情绪也可能成为谈判中的障碍。例如,人们常常过度乐观地看待自己、世界和未来,这可能导致在谈判中过度估计和过于乐观。
-
谈判还可能导致参与者情绪化,从而增加理性处理信息的难度。
因此,开发有效的谈判对话Agent至关重要,这有助于人类更好地理解和控制这些不同因素,进而优化谈判结果。
2. 谈判对话系统的方法论概述
现有谈判对话系统的研究分为三大板块,如下图所示:
-
谈判者建模:目的是基于对话语境推断其他谈判者的显式信息
-
策略建模:学习在当前对话语境下选择要使用的策略。
-
行动学习:将以上谈判信息纳入机器学习框架中开发对话模型,将策略转化为可观察的行动或响应。
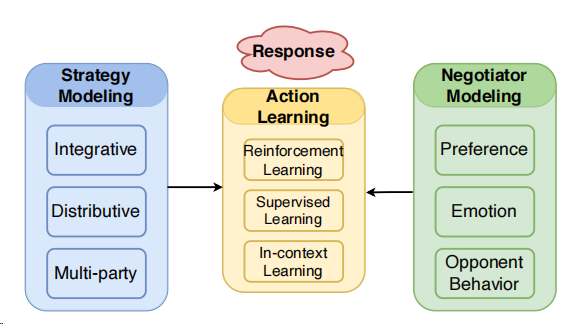
2.2 策略建模
谈判策略建模关注的是在谈判过程中使用的各种策略。这些策略可以是综合性的,旨在实现参与者之间的共同利益,也可以是分配性的,即以赢取最大个人利益为目标。
综合性策略
综合性策略 (也称为 “双赢” 策略建模)旨在实现参与者之间的共同利益。[1]提出了潜在动作强化学习(LaRL)框架用于对话策略建模,但受限于缺乏明确策略标签,只能分析隐含策略。[2,3]随后定义了“引出偏好”、“协作”和“共情”等明确策略,并通过分层神经模型捕捉用户偏好。[4]则提出了一种协作策略集,用于面试中的工作负荷和薪水协商,以达成雇主和员工间的一致。
分配策略
分配策略着重于实现个人利益最大化,当一个人坚持自己的立场或抵制对手的交易时,就会采用分配策略。
[5]提出了一套包含10个策略的说服方法,旨在促进他人向慈善机构捐款,涉及逻辑和情感吸引等。[6,7]对结构(例如,面临的行为、情绪)进一步探索。同时, [8]研究了四种对抗攻击策略,包括竞争、赋权、有偏见的处理和规避,每个类别都包含具体的战略行为,如攻击消息来源或强化个人偏好以否定观点。
多方策略
在多方情境中,策略建模需要考虑个体参与者、整个团体和子团体之间的不同态度和复杂关系。[9]尝试用多智能体强化学习框架建模多方谈判。[10]则用话语依赖树预测多方关系依赖。[11]通过图神经网络揭示了多方间的关系。然而,多方策略研究受限于缺乏相关数据集和基准。
2.3 谈判者建模
谈判者建模旨在从对话上下文中推断出其他谈判者的显性信息。这包括对谈判者的偏好、情绪和对手行为的建模。
偏好
偏好估计有助于Agent推断对手的意图,并猜测他们自己的话语会如何影响对手的偏好。[12] 提出基于频率的启发式方法估计谈判者偏好,但偏好建模的挑战在于需要完整对话。[13]采用基于规则的系统,通过分析部分对话中的语言特征识别用户偏好。[3]将偏好估计视为排名任务,提出基于变换器的模型,可直接在部分对话中训练,增强现实应用中的偏好建模。
情绪
情绪建模是指识别谈判者的情绪或情绪变化。[14]研究了谈判对话中的情绪感受和表达,预测了结果满意度和对伙伴的感知。[15]明确建模了情绪转变,采用预训练语言模型支持患者。[7]在说服性讨论中提出对话行为建模方法。[16]利用增强学习框架引发说服性信息中的情绪。
对手行为
对手行为建模指的是在谈判过程中检测和预测对手的行为。例如,在Craigslist数据集中提供了细粒度的对话行为标签,用于跟踪买家和卖家的行为。[17]提出基于DQN的对手行为建模框架,以估计对手的相反行动。[18]分离对手行为建模与话语生成,提高谈判系统精度。[19]基于心灵理论改进谈判系统,提出一阶模型计算心态预期值,并提供显式与隐式对话智能体变体。
2.4 行动学习
行动学习使谈判对话系统能够合理地结合先前的策略和其他谈判信息来生成高质量的回应。研究者们采用了多种策略学习方法,包括强化学习、监督学习和上下文学习。
强化学习
[20]开创了将强化学习技术应用于谈判对话系统的先河。[21]提出的OPPA使用系统行动预测目标智能体行为,奖励基于对话估计结构化输出。[22]采用模块化框架结合语言模型生成回复,通过回复检测器和RL奖励函数评估策略,但策略学习与回复生成分离。[23]提出综合框架,整合深度Q-learning与多通道谈判技巧,使智能体利用参数化DQN学习综合谈判策略,融合语言交流技能和出价策略。
监督学习
[24]使用Seq2Seq模型最大化训练数据可能性来学习行动。[18]提出应用监督模型优化特定对话奖励函数,包括价格效用、agent效用差异和话语数量。[25]首先训练策略预测器预测谈判策略,然后生成依赖于预测策略、用户话语和对话背景的回应。[26]结合策略图网络与Seq2Seq模型,创建可解释的政策学习范式。此外,[27]利用预训练BERT模型识别说服性谈判中的抵抗策略。同时,[28]提出端到端框架整合意图和语义槽分类、回应生成和过滤任务。
上下文学习
随着GPT-3.5和GPT-4等大型语言模型(LLM)的出现,零样本和少样本的上下文学习技术得到应用,也在谈判对话任务中得到应用。[29]将LLM应用于谈判场景,而[30]则将其用于“狼人”游戏。[31]提出了评估LLM Agent战略规划和执行能力的框架。在这些应用中,LLM作为Agent与其他LLM在特定情境下协商,以实现预定目标。
3. 谈判数据集的分类与分析
谈判数据集是谈判对话系统研究的基础,可以根据谈判类型、场景和数据规模进行分类。如下表所示,按其发布时间进行排序,展示谈判类型、情境、对话数量及相应的平均轮次,以及参与方属性。本文主要从综合谈判数据和分配谈判数据展开介绍。
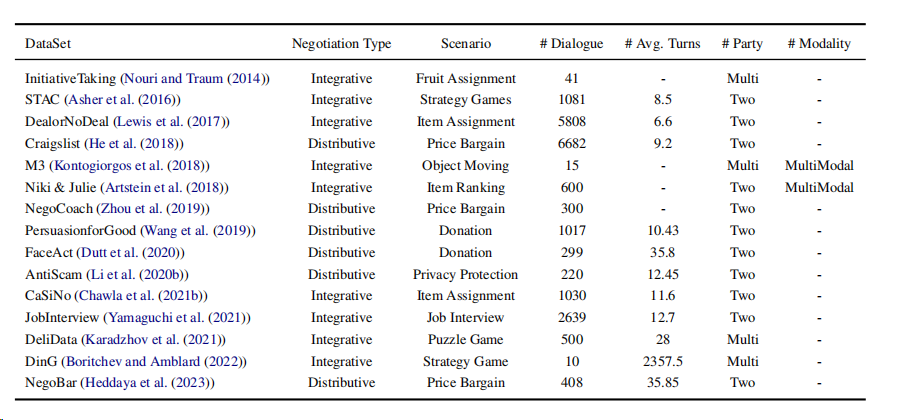
3.1 综合谈判数据集
综合谈判数据集涉及多个议题的谈判,为了实现最佳谈判目标,相关参与者应对多个问题进行权衡。
多人策略游戏
策略电子游戏让玩家之间口头交流进行交易,以实现任务和目标。如STAC数据集基于Catan游戏,玩家需要通过交流资源来完成任务,包括木材、小麦、羊等,以购买定居点、道路和城市。由于每个玩家只能获得自己的资源,他们必须相互交流。
物品分配谈判
物品分配场景涉及一组固定的物品以及对话中每个玩家的预定义优先级。由于玩家只能访问自己的优先级,他们需要相互协商以交换他们偏爱的物品。
-
InitiativeTalking:用于两家餐厅的所有者之间。他们讨论如何分配水果(即苹果、香蕉和草莓)并努力达成协议;
-
DealorNoDeal:两个参与者只能看到自己的 物品集合,并为每个物品赋予一个价值,要求 他们在谈判后最大化他们的总分。
-
CaSiNo:涉及露营邻居就额外的食物、水和木柴包进行谈判,每方对不同物品有不同的优先级。
求职面试谈判
JobInterview数据集包括招聘人员和应聘者之间关于薪资、休假、职位和工作地点的互动。参与者将获知对方的偏好和相应问题。在谈判过程中,与对方的反馈将被转达给参与者。
3.2 分配谈判数据集
分配式谈判是围绕一个固定的价值(即如何分配蛋糕)展开的讨论。在这种谈判中,参与者通常只讨论一个问题(例如物品价格),因此在这种谈判中几乎没有多个问题之间的权衡。
劝说捐赠
PersuasionforGood数据集关注慈善捐赠的说服谈判,谈判者需要说服对方进行捐赠。在数据标注过程中,给劝说者提供了一些劝说技巧和例句,而被劝说者只告诉他们这个对话是关于慈善的。标注者要在对话中至少完成十个话语,并被鼓励在对话结束时达成一致。
产品价格谈判
-
CraigslistBargain数据集基于现实生活中的商品价格谈判场景,买家和卖家需要就给定商品的价格进行谈判。
-
NegoCoach是一个类似的基准,但增加了一个谈判教练,监视双方标注者之间的消息,并实时向卖家推荐策略来获得更好的交易。
用户隐私保护
谈判参与者的隐私保护变得越来越重要。参与者(例如攻击者和防御者)的目标也是相互冲的。
Anti-Scam是一个专注于在线客服的基准。用户通过识别其对手是否试图窃取敏感个人信息来保护自己。Anti-Scam提供了研究此情景下人类引诱策略的机会。
通过对谈判对话系统的方法论和数据集的深入分析,可以更好地理解谈判过程中的策略选择、谈判者行为的动态以及如何将这些信息转化为有效的对话行为。这些研究为开发能够在各种真实场景中协助人类进行谈判的智能Agent提供了理论基础和实践指导。
4. 评估方法
下表展示了现有谈判对话基准中使用了各种度量标准:
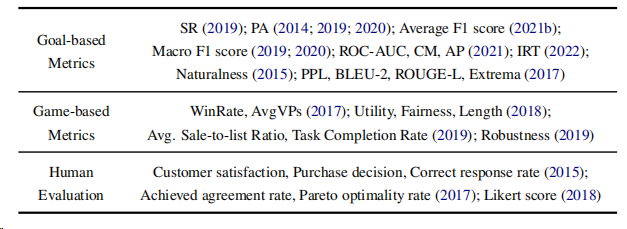
1. 目标导向评估指标
目标导向的评估指标主要关注于评估谈判Agent达成谈判目标的能力。这些指标通常是可量化的:
-
成功率(Success Rate, SR):评估评估Agent频繁地在其目标内完成任务的最常用度量标准。
-
预测准确性(Prediction Accuracy, PA),以及宏观/平均F1分数:评估Agent策略预测的准确性。
-
项目反应理论(IRT):分析对观众影响力的有效性。
此外,还有一些针对语言实现的指标,如自然度、困惑度(PPL)、BLEU-2、ROUGE-L和词嵌入极值匹配分数等。
2. 基于游戏的评估指标
与目标导向指标不同,基于游戏的评估指标提供了一个用户中心的视角来评估系统。
例如,在“卡坦岛”游戏中,研究者提出了胜率(WinRate)和平均胜点(AvgVPs)来分别评估人类和Agent的成功。
在产品价格谈判任务中,使用了特定任务分数来测试Agent的性能,包括效用、公平性和对话长度。此外,还有任务完成率和平均销售对比列表比率等指标。
3. 人类评估
人类评估作为Agent性能的主观评价方法,用于评估用户对对话系统的满意度。例如,使用用户模拟器作为销售人员与真实客户进行讨价还价,并让用户对客户满意度、购买决策和对话中的正确响应率进行注释。此外,还有达成协议率、帕累托最优率(Pareto optimality rate)和人类相似度(通过Likert标度手动评分Agent是否能像真人一样行动。)
5. 新兴领域与挑战:多模态、多方与跨文化谈判对话
1. 多模态谈判对话
现有的谈判对话研究很少考虑多模态信息,但人类在谈判中往往会利用包括文本、音频和视觉信息在内的多种模式。例如,参与者的面部表情和情绪可能是做出谈判决策的重要线索。未来的研究可以考虑将这些非文本信息纳入谈判对话中。
2. 多方谈判对话
现有的谈判对话基准和方法主要集中在两方谈判上,导致多方谈判对话的研究尚不深入。未来,应着重收集多方谈判场景中的对话数据,包括一般的多方谈判以及团队谈判。团队谈判尤为特殊,它涉及不同关系和角色的人员,常见于大型商业交易中,并凸显了多方间关系的至关重要性。
3. 跨文化与多语言谈判对话
当前谈判对话基准主要聚焦英语,对其他语言和文化探索不足。全球化背景下,涉及不同文化背景的对话愈发关键。因此,急需构建多文化和多语言的谈判对话系统。未来工作应将多语言话语及各国社会规范融入谈判对话基准中。
4. 真实世界场景中的谈判对话
以往工作提出了多种谈判对话基准,但多数基于人类众包创建,参与者扮演特定角色,未必能准确反映真实世界谈判,如政治、商业场景。因此,收集真实世界谈判对话,如商务会议录音或电话通话,或成为值得探索的研究方向。
总结与未来展望
本文通过系统性地回顾谈判对话系统的研究,总结了谈判对话系统的研究进展,还对数据集、评估方法和建模方法进行了分类和概述。希望本综述能够激发和促进在谈判对话系统领域的研究。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!


参考资料
[1]Tiancheng Zhao, Kaige Xie, and Maxine Eskenazi.2019. Rethinking action spaces for reinforcementlearning in end-to-end dialog agents with latent variable models.
[2]Kushal Chawla, Jaysa Ramirez, Rene Clever, Gale Lucas, Jonathan May, and Jonathan Gratch. 2021b.CaSiNo: A corpus of campsite negotiation dialogues for automatic negotiation systems.
[3]Kushal Chawla, Gale Lucas, Jonathan May, and Jonathan Gratch. 2022. Opponent modeling in negotiation dialogues by related data adaptation
[4]Atsuki Yamaguchi, Kosui Iwasa, and Katsuhide Fujita. 2021. Dialogue act-based breakdown detection in negotiation dialogues.
[5]Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. 2019. Persuasion for good: Towards a personalized persuasive dialogue system for social good.
[6]Jialu Li, Esin Durmus, and Claire Cardie. 2020a. Exploring the role of argument structure in online debate persuasion.
[7]Ritam Dutt, Rishabh Joshi, and Carolyn Rose. 2020. Keeping up appearances: Computational modeling of face acts in persuasion oriented discussions.
[8]Ritam Dutt, Sayan Sinha, Rishabh Joshi, Surya Shekhar Chakraborty, Meredith Riggs, Xinru Yan, Haogang Bao, and Carolyn Rose. 2021a. ResPer: Computationally modelling resisting strategies in persuasive conversations
[9]Kallirroi Georgila, Claire Nelson, and David Traum. 2014. Single-agent vs. multi-agent techniques for concurrent reinforcement learning of negotiation dialogue policies
[10]Zhouxing Shi and Minlie Huang. 2019. A deep sequential model for discourse parsing on multi-party dialogues.
[11]Jiaqi Li, Ming Liu, Zihao Zheng,Heng Zhang, Bing Qin, Min-Yen Kan, and Ting Liu. 2021. Dadgraph: A discourse-aware dialogue graph neural network for multiparty dialogue machine reading comprehension.
[12]Zahra Nazari, Gale M Lucas, and Jonathan Gratch. 2015.Opponent modeling for virtual human negotiators.
[13]Caroline Langlet and Chloé Clavel. 2018. Detecting user’s likes and dislikes for a virtual negotiating agent.
[14]Kushal Chawla, Rene Clever, Jaysa Ramirez, Gale Lucas, and Jonathan Gratch. 2021a. Towards emotionaware agents for negotiation dialogues.B
[15]Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Huang. 2021. Towards emotional support dialog systems.
[16]Kshitij Mishra, Azlaan Mustafa Samad, Palak Totala, and Asif Ekbal. 2022. PEPDS: A polite and empathetic persuasive dialogue system for charity donation.
[17]Zheng Zhang, Lizi Liao, Xiaoyan Zhu, Tat-Seng Chua, Zitao Liu, Yan Huang, and Minlie Huang. 2020. Learning goal-oriented dialogue policy with opposite agent awareness.
[18]He He, Derek Chen, Anusha Balakrishnan, and Percy Liang. 2018. Decoupling strategy and generation in negotiation dialogues.
[19]Runzhe Yang, Jingxiao Chen, and Karthik Narasimhan. 2021. Improving dialog systems for negotiation with personality modeling.
[20]Michael English and Peter Heeman. 2005. Learning mixed initiative dialog strategies by using reinforcement learning on both conversants.
[21]Tiancheng Zhao, Kaige Xie, and Maxine Eskenazi.2019. Rethinking action spaces for reinforcementlearning in end-to-end dialog agents with latent variable models.
[22]Zheng Zhang, Lizi Liao, Xiaoyan Zhu, Tat-Seng Chua, Zitao Liu, Yan Huang, and Minlie Huang. 2020. Learning goal-oriented dialogue policy with opposite agent awareness. I
[23]Xiaoyang Gao, Siqi Chen, Yan Zheng, and Jianye Hao. 2021. A deep reinforcement learning-based agent for negotiation with multiple communication channels.
[24] Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh,and Dhruv Batra. 2017. Deal or no deal? end-toend learning of negotiation dialogues.
[25]Yiheng Zhou, Yulia Tsvetkov, Alan W. Black, and Zhou Yu. 2020. Augmenting non-collaborative dialog systems with explicit semantic and strategic dialog history.
[26]Dialograph: Incorporating interpretable strategygraph networks into negotiation dialogues.
[27]ResPer: Computationally modelling resisting strategies in persuasive conversations.
[28]Yu Li, Kun Qian, Weiyan Shi, and Zhou Yu. 2020b. End-to-end trainable non-collaborative dialog system.
[29]Yao Fu, Hao Peng, Tushar Khot, and Mirella Lapata. 2023. Improving language model negotiation with self-play and in-context learning from ai feedback.
[30]Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, and Yang Liu. 2023. Exploring large language models for communication games: An empirical study on werewolf. arXiv preprint arXiv:2309.04658.
[31]Jiangjie Chen, Siyu Yuan, Rong Ye, Bodhisattwa Prasad Majumder, and Kyle Richardson. 2023. Put your money where your mouth is: Evaluating strategic planning and execution of llm agents in an auction arena. arXiv preprint arXiv:2310.05746.
这篇关于今日arXiv最热NLP大模型论文:智能谈判Agent综述,一文读懂谈判桌上的人工智能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





