本文主要是介绍线性判别分析(LDA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、说明
LDA 是一种监督降维和分类技术。其主要目的是查找最能分隔数据集中两个或多个类的特征的线性组合。LDA 的主要目标是找到一个较低维度的子空间,该子空间可以最大限度地区分不同类别,同时保留与歧视相关的信息。
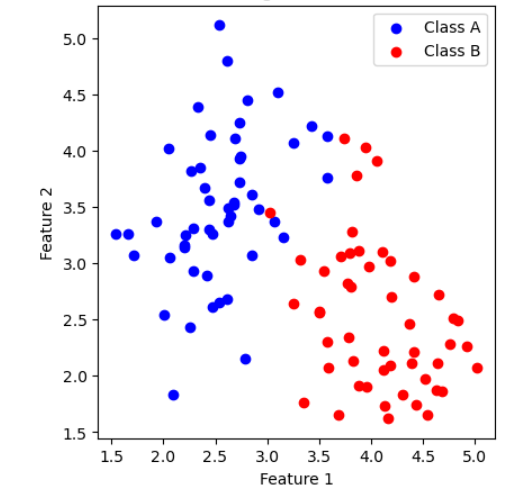
LDA 是受监督的,这意味着它需要了解类标签或类别。它试图在数据空间中找到最能区分类的方向(特征的线性组合)。LDA 使类间方差与类内方差的比率最大化。它通过查找要素的线性组合来实现,这些要素可以最大限度地提高类之间的可分离性。
然而,一个问题是,LDA与PCA有什么区别。LDA 面向分类和最大化类分离,而 PCA 则更通用,侧重于捕获数据方差
让我们看看计算数据集的 LDA 所涉及的步骤
二、步骤1:数据收集
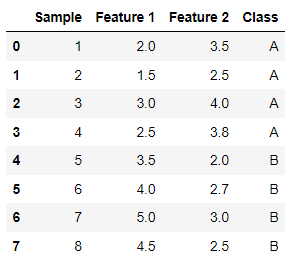
让我们从一个数据集开始,其中包含来自两个类(A 类和 B 类)以及两个特征(特征 1 和特征 2)的样本。
三、步骤 2:计算类均值
计算两个要素的每个类(A 类和 B 类)的平均向量。
A 类的平均向量:
Mean(Feature 1) = (2.0 + 1.5 + 3.0 + 2.5) / 4 = 2.5
Mean(Feature 2) = (3.5 + 2.5 + 4.0 + 3.8) / 4 = 3.45B 类的平均向量:
Mean(Feature 1) = (3.5 + 4.0 + 5.0 + 4.5) / 4 = 4.25
Mean(Feature 2) = (2.0 + 2.7 + 3.0 + 2.5) / 4 = 2.55四、步骤 3:计算类内散点矩阵 (SW)
SW 表示数据集的类内散点矩阵。它衡量每个类内数据的分布
要计算数据集的类内散点矩阵 (SW),您需要分别计算每个类的协方差矩阵,然后将它们相加。让我们一步一步地计算 A 类的 SW:
1.让我们将 A 类的平均向量表示为 ,我们已经计算过了:μ_A
μ_A = [Mean(Feature 1), Mean(Feature 2)] = [2.25, 3.45]2.计算A类的协方差矩阵
A 类的协方差矩阵计算如下:
Covariance Matrix for Class A (S_A) = Σ [(x - Mean Vector for Class A) * (x - Mean Vector for Class A)^T]Sample 1 (Class A):
Feature 1: 2.0
Feature 2: 3.5Calculate differences:
Diff1 = 2.0 - 2.25 = -0.25
Diff2 = 3.5 - 3.45 = 0.05Cov(Feature 1, Feature 1) = (Diff1 * Diff1) / (4 - 1) = (-0.25 * -0.25) / 3 = 0.0417
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) / (4 - 1) = (-0.25 * 0.05) / 3 = -0.0042 Sample 2 (Class A):
Feature 1: 1.5
Feature 2: 2.5Calculate differences:
Diff1 = 1.5 - 2.25 = -0.75
Diff2 = 2.5 - 3.45 = -0.95Covariance Matrix elements for Sample 2:
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) / (4 - 1) = (-0.75 * -0.75) / 3 = 0.1875
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) / (4 - 1) = (-0.75 * -0.95) / 3 = 0.2375Sample 3 (Class A):Feature 1: 3.0
Feature 2: 4.0
Calculate differences:Diff1 = 3.0 - 2.25 = 0.75
Diff2 = 4.0 - 3.45 = 0.55
Covariance Matrix elements for Sample 3:Cov(Feature 1, Feature 1) = (Diff1 * Diff1) / (4 - 1) = (0.75 * 0.75) / 3 = 0.1875
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) / (4 - 1) = (0.75 * 0.55) / 3 = 0.1375Sample 4 (Class A):Feature 1: 2.5
Feature 2: 3.8
Calculate differences:Diff1 = 2.5 - 2.25 = 0.25
Diff2 = 3.8 - 3.45 = 0.35Covariance Matrix elements for Sample 4:
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) / (4 - 1) = (0.25 * 0.25) / 3 = 0.04
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) / (4 - 1) = (0.25 * 0.35) / 3 = 0.029A 类的协方差矩阵:
| Cov(Feature 1, Feature 1) Cov(Feature 1, Feature 2) |
| Cov(Feature 2, Feature 1) Cov(Feature 2, Feature 2) |Covariance Matrix for Sample 1 (S1_A):
[[0.25, -0.025],[-0.025, 0.0025]]Covariance Matrix for Sample 2 (S2_A):
[[1.0, 0.95],[0.95, 0.9025]]Covariance Matrix for Sample 3 (S3_A):
[[0.25, 0.275],[0.275, 0.3025]]Covariance Matrix for Sample 4 (S4_A):
[[0.0, 0.0],[0.0, 0.1225]]S_A = S1_A + S2_A + S3_A + S4_A代入计算值:
S_A =| 0.0417 -0.0042 || 0.2375 0.0417 |同样,我们可以计算 B 类的协方差矩阵
Sample 5 (Class B):
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) = (-0.625 * -0.625) = 0.390625
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) = (-0.625 * -0.55) = 0.34375
Cov(Feature 2, Feature 1) = (Diff2 * Diff1) = (-0.55 * -0.625) = 0.34375
Cov(Feature 2, Feature 2) = (Diff2 * Diff2) = (-0.55 * -0.55) = 0.3025Sample 6 (Class B):
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) = (-0.125 * -0.125) = 0.015625
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) = (-0.125 * 0.15) = -0.01875
Cov(Feature 2, Feature 1) = (Diff2 * Diff1) = (0.15 * -0.125) = -0.01875
Cov(Feature 2, Feature 2) = (Diff2 * Diff2) = (0.15 * 0.15) = 0.0225Sample 7 (Class B):
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) = (0.875 * 0.875) = 0.765625
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) = (0.875 * 0.45) = 0.39375
Cov(Feature 2, Feature 1) = (Diff2 * Diff1) = (0.45 * 0.875) = 0.39375
Cov(Feature 2, Feature 2) = (Diff2 * Diff2) = (0.45 * 0.45) = 0.2025Sample 8 (Class B):
Cov(Feature 1, Feature 1) = (Diff1 * Diff1) = (0.375 * 0.375) = 0.140625
Cov(Feature 1, Feature 2) = (Diff1 * Diff2) = (0.375 * -0.05) = -0.01875
Cov(Feature 2, Feature 1) = (Diff2 * Diff1) = (-0.05 * 0.375) = -0.01875
Cov(Feature 2, Feature 2) = (Diff2 * Diff2) = (-0.05 * -0.05) = 0.0025S_B = S5_B + S6_B + S7_B + S8_BS_B = [[1.3125, 0.7],[0.7, 0.53]]计算类内散点矩阵 (SW)。将两个类的协方差矩阵相加即可得到 SW:
Within-Class Scatter Matrix (SW)
=S_A+S_B=S_W
= [0.0833 + 0.765625, -0.000833 + 0.39375][-0.000833 + 0.39375, 0.0025 + 0.2025]S_W = [0.848925, 0.393917][0.392917, 0.205]五、步骤 4:计算特征值和特征向量
在计算上,可以找到:
# Compute eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(S_W)从数学上讲,这可以找到:
- 计算S_W的倒数:
计算类内散点矩阵的逆数,表示为 S_W⁻¹。如果S_W不可逆,则可以使用伪逆。
S_W^(-1) = | 10.8103 -20.7762 || -20.7762 44.7628 |2.S_W^(-1)和S_B的乘积
S_W^(-1) * S_B = | 13.344 -6.953 || -4.543 11.953 |3.To 找到特征值 (λ),您需要求解特征方程,该方程由下式给出:
|S_W^(-1) * S_B - λ * I| = 0I是单位矩阵
| 13.344 - λ -6.953 |
| -4.543 11.953 - λ | 可以通过将每个特征值代入方程并求解相应的特征向量来找到特征向量。S_W^(-1) * S_B * v = λ * vv
六、步骤 5:对特征值进行排序
获得特征值后,按降序对它们进行排序以确定其重要性。您可以按如下方式在数学上表示这一点:
设特征值表示为 λ_1、λ_2、...、λ_p (其中 p 是要素或维度的数量)。
按降序对特征值进行排序:
λ_1 >= λ_2 >= ... >= λ_p七、第 6 步:选择组件
现在,您可以选择顶部特征值,其中是所需的降维水平。让我们将其表示为选择最大的特征值:kkk
λ_1, λ_2, ..., λ_k 这些特征值表示数据中最重要的判别方向。k
八、第 7 步:项目数据
选择特征值后,可以使用相应的特征向量将原始数据投影到新的低维空间上。此步骤降低了数据的维度,同时保留了最相关的信息。kk
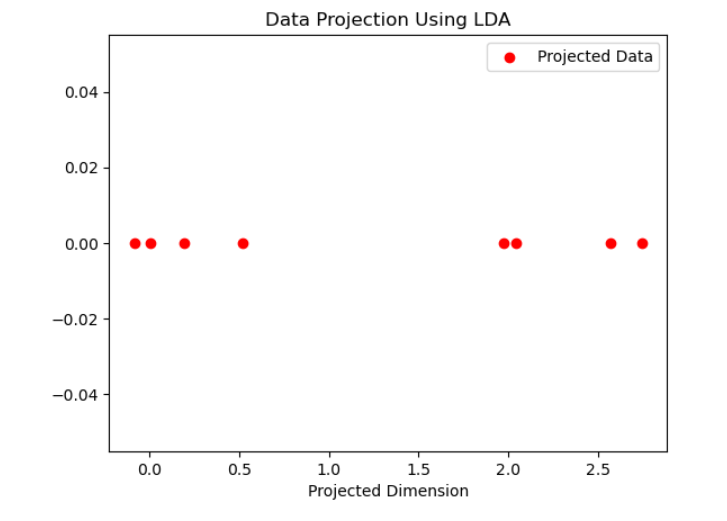
使用线性判别分析 (LDA) 中选定的特征向量将数据投影到低维空间上
这篇关于线性判别分析(LDA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!