本文主要是介绍Gated Neural Networks for Targeted Sentiment Analysis原文、翻译及代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址
代码地址
摘要
目标情感分析对给定文本文档中每个目标实体提及的情感极性进行分类。Seminal方法从自动句法解析树中提取人工离散特征,以捕获封闭句对目标实体提及的语义信息。最近,已经证明了不使用句法解析器就可以实现有竞争力的准确度,因为句法解析器在推文等嘈杂的文本上可能非常不准确。这是通过在根据目标实体提及的推文的简单和直观的分割上应用分布式词表示和丰富的神经池函数来实现的。在本文中,我们扩展了这一思想,提出了一个句子级的神经模型来解决池化函数的局限性,因为池化函数没有明确地模拟推文级语义。首先,采用双向门控神经网络来连接tweet中的单词,这样就可以在隐藏层上应用pooling函数而不是单词,以更好地表示目标及其上下文。其次,采用三路门控神经网络结构来模拟目标提及其周围上下文之间的交互。实验表明,与目前最好的目标情感分析方法相比,我们提出的模型给出了明显更高的准确率。
介绍
目标情感分析研究给定句子中对某些目标实体提及的意见极性的分类(Jiang等,2011;Dong等,2014;Vo和Zhang,2015)。一个例子如图1所示,输入是一组推文,“miley ray cyrus”、“taylor swift”、“Windows 7”、"nick cannon "和 "britney spears "等实体分别被标记为舆论目标。输出的内容包括每个实体上的三种方式(+、-、0)的情感标签。

在目标情感分析中,一个非常重要的问题是如何对目标与其上下文之间的关联进行建模,这可能涉及复杂的句法和语义结构,如谓语-论点链接、否定、共同引用甚至讽刺。Jiang等(2011)在给定推文的POS标签和依赖性链接以及其上下文推文上去丰富特征,以捕捉目标情感的两极性。Dong等(2014)使用词嵌入和神经网络来代替人工特征,但也依赖于句法依赖,而句法依赖是由自动POS标签和解析产生的。
与离散的人工特征相比,嵌入特征不那么稀疏,可以从大量的原始文本中学习,自动捕捉分布式句法和语义信息。因此,它们为复杂的语义问题(如否定和讽刺)提供了一个潜在的更优雅和有效的解决方案。Vo和Zhang(2015)利用了这一优势,通过定义神经池在多变量词嵌入上丰富的自动特征。如图2(a)所示,给定一个目标,他们将包围句分为三个段,在每个段上使用池化函数分别获得左语境、目标和右语境的特征。然后将自动特征输入到线性分类器中进行情感分类。

图2:基准模型和本文的模型 (She began to love miley ray cyrus since 2013 😃).
Vo和Zhang(2015)的方法避免了对自动句法解析器的依赖,因为自动句法解析器在推文上的准确率很高,从而使情感分类结果比Dong等(2014)有所提高。另一方面,它不能完全捕捉到推文和给定目标实体的语义信息。首先,池化函数可以从词序列中选择最有用的特征,但不能捕捉到tweet层面的底层语法和语义信息。其次,目标实体与其上下文之间的交互只在池化函数和线性分类器上隐式建模,而不是显式建模。
我们通过使用门控神经网络结构分别对包围推文的语法和语义,以及周围上下文和目标之间的交互进行建模,来解决上述两个局限性。循环神经网络(RNN)已经被证明在对句子进行建模时是有效的(Mikolov等,2010;Graves,2012;Cho等,2014b;Sutskever,Vinyals和Le,2014),可以捕捉词之间的长程依赖关系。门控递归神经网络(GRNN)(Cho等2014a)和长短期记忆(LSTM)(Hochreiter和Schmidhuber,1997)通过解决深层结构中的递减和爆炸梯度问题来促进递归网络的训练(Bengio,Simard和Frasconi,1994)。出于对效率的考虑,我们使用了一个简单的门控递归神经网络,该网络已被证明在几个任务中给出了与LSTMs相当的精度(Chung等人,2014)。
此外,我们还使用门控神经网络层,明确建模了左语境、右语境和目标之间的交互。对于一些推文,如 “我喜欢[Facebook]。”,左侧上下文(即 “我喜欢”)表示目标的情感类。对于一些推文,如 “我认为[变形金刚]很无聊。”,右侧上下文主导极性。对于 “击败[曼联]很有挑战性。“这样的推文,两种语境相互作用,表达目标的情感极性。据此,我们设计了一个介于左语境和右语境之间的门控神经网络层(图4),它明确地将左语境、右语境和两者的组合进行插值。
上下文对目标情感的影响还取决于目标实体本身。例如,如果X是 “成本”,则”[X]掉了 “的情感极性是”[X]+”,但如果X是 “收入”,则"[X]-"。相应地,我们在上述神经网络中加入目标到控制门。实验表明,与Vo和Zhang(2015)的方法相比,门控神经网络结构导致了情感分类精度的明显提高。我们将我们的系统和源代码在GPL下公开,网址为https://github.com/SUTDNLP/NNTargetedSentiment。
相关工作
针对性的情感分析与细粒度的相关的情感分析(Wiebe、Wilson和Cardie,2005;Jin、Ho和Srihari,2009;Li等,2010;Yang和Cardie,2013;Nakov等,2013),从给定的句子中共同提取意见表达、持有人和目标。与细粒度的情感相比,目标情感提供的操作细节较少,但另一方面需要较少的人工标注。也有关于开放领域目标情感的工作(Mitchell等,2013;Zhang,Zhang和Vo,2015),它同时识别意见目标和他们的情感。该任务可以看作是实体识别和目标情绪分类的联合问题。
其他相关任务包括面向方面的情感分析(Hu和Liu,2004;Popescu和Etzioni,2007),它从用户评论中提取产品特征和对它们的意见,以及面向话题的情感分析(Yi等,2003;Wang等,2011),它提取对某些话题或主题的特征和/或情感。这些任务在精神上接近于定向情感分析,但在领域和任务表述上有细微的变化。
传统的情感分析系统依赖于人工特征(Pang,Lee,和Vaithyanathan 2002;Go,Bhayani,和Huang 2009;Mohammad,Kiritchenko,和Zhu 2013).最近,分布式词表征(Socher等2013;Tang等. 2014;Vo和Zhang 2015)和深度神经网络结构(Irsoy和Cardie 2013;Paulus、Socher和Manning 2014;Kalchbrenner、Grefenstette和Blunsom 2014;Zhou等人2014;Dong等人2014;dos Santos和Gatti 2014)已经被用于该任务,给出了具有竞争力的准确性。我们的工作与这些方法一致,使用词嵌入和深度神经网络结构来自动利用推文的语法和语义结构。然而,我们模拟的是目标情感,而不是大多数先前的工作所做的文档级情感。据我们所知,我们是第一个使用深度神经网络对目标情感的句子进行建模的。
Baseline
我们以Vo和Zhang(2015)的模型为基线。如图2(a)所示,它将带有目标实体的推文作为输入,并输出每个目标的情感极性。对于每个给定的目标,该模型分三步计算情感类。
首先,给定推文中的每个词被映射到一个低维、实值的嵌入向量。其次,应用元素化的池化函数,分别从目标实体、左语境和右语境中提取有用的特征。 我们遵循Vo和Zhang(2015),使用最大、最小、平均、乘积和标准差池化结果的并集来实现自动特征。最后,将所有由池化函数产生的特征进行串联,并作为线性分类器的输入,预测目标的情感极性。
我们的基线是Vo和Zhang(2015)的简化版本,他们在完整的tweet上应用了池化函数,除了目标实体、左和右上下文,以提取tweet的全局特征。然而,我们并不包含这样的特征,因为我们的扩展模型明确地捕获了完整推文上的全局语法和语义信息。Vo和Zhang(2015)利用的另一个信息源是情感词典。为了单独研究网络结构的影响,我们在基线模型中不包含词汇。我们的神经模型不依赖任何外部资源。
使用双向GRNN对Tweet层面的句法和语义信息进行建模
基线模型没有明确地捕捉到输入推文的底层语义信息,如依赖关系、共同引用和否定范围。我们针对这一潜在的缺点,使用门控循环神经网络层对输入的推文级语法和语义信息进行建模,捕捉其词与词之间的相互作用。
我们提出的模型与基线模型的区别如图3所示,其中xi代表第i个词在输入tweet中的嵌入,不管它是属于目标、左语境还是右语境。对于基线模型(图3(a)),特征是直接从单个词嵌入中提取的。
循环推文模型(RNN)。我们对基线系统做了两个扩展。首先,可以通过在输入层上增加一个递归隐藏层来进行相对简单的扩展(图3(b))。在这个层中,每个节点hi对应于输入xi。不过,它并不是仅仅从词xi中获取信息,而是还与其前辈hi-1相连。形式上,hi的值是
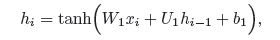
其中矩阵W1和U1以及向量b1为模型参数,tanh为激活函数。
隐藏节点hi间接地将tweet中的词从左到右连接起来,从而不仅收集了xi的信息,还收集了[x1, — ,xi-1]的信息。为了也能采集到[xi+1,— ,xn]的信息,其中n是tweet的大小,我们在反方向添加一个对应的hi。
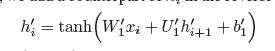
这里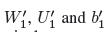 分别是W1、U1和b的对应关系。
分别是W1、U1和b的对应关系。
我们在hi ⊕ hi’而不是xi上应用池化函数,其中⊕代表向量连接,从双向递归序列模型中提取特征。

图3:基线、递推和门控递推模型之间的比较。门控信号zi和ri由xi和hi-1决定)。
门(GRNN)。第二种扩展是在递归隐藏层中加入门,控制隐藏层和输入层中节点之间的信息流。门控神经网络已经被证明可以通过更好的梯度传播来减少香草递归神经网络对序列末端的非正式偏差。
图3©所示为xi上的子网络结构。与图3(b)相比,主要有两个变化。
首先,引入了一个新的隐藏节点˜hi,它代表了hi-1和xi的组合。这里˜hi与图3(b)中的hi相似。其次,hi现在是由hi-1和˜hi的内插结果,权重由两个互补门zi和→1 - zi控制。hi-1对˜hi的贡献也由一个门ri控制。形式上来说。
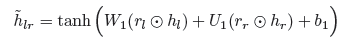
其中,
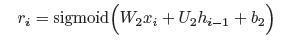
ri中的每个位控制hi-1中相应位对˜hi的贡献。此处
代表位元乘积运算,-,sigmoid是sigmoid激活函数。hi-1到˜hi的内插对hi的贡献可以公式化为:
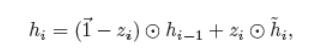
其中:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DQhi0Gaq-1610022043682)(C:\Users\WY\AppData\Roaming\Typora\typora-user-images\image-20210107112228487.png)]](https://img-blog.csdnimg.cn/20210107203855561.png)
在上式中,矩阵W1、W2、W3、U1、U2和U3以及向量b1、b2和b3为模型参数。
与图3(b)类似,门控递归神经网络也是双向应用,反方向的hi对应的是hi’,W1、W2、W3、U1、U2、U3、b1、b2和b3对应的参数是W1‘、W2’、W3‘、U1’、U2‘、U3’、b1‘、b2’和b3‘。在隐藏节点序列 hi ⊕ hi’上进行最大、最小、平均、积和标准差池化。
建立目标和周围环境之间的互动模型
三向门(G3)。图2(a)中的基线并没有明确模拟左语境和右语境在决定目标的情感极性时的交互作用。我们通过使用门控神经网络结构连接上下文来解决这一限制。如图4所示,我们用hl表示池化函数在左上下文上的输出,hr表示池化函数在左上下文上的输出,ht表示池化函数在目标实体跨度上的输出。
我们首先对hl和hr进行神经组合,用˜hlr表示。然后进行三向位智线性插值,将hl、hr和˜hlr进行组合。门控的直觉与门控递归隐藏层类似,门控控制每个源对目标情绪的贡献。这是因为情感信号可以由左语境、右语境或两者的结合来主导。在引言中已经讨论了一些例子。目标实体参与门控权重,因为对目标的情感极性取决于上下文和目标本身。
类似于门控递归神经网络层,其中hi-1和xi的组合形成˜hi,我们使用门控hl和hr的组合形成hlr。
从形式上看.
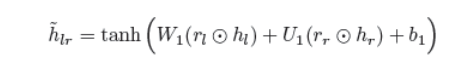
其中rl和rr分别是控制来自hl和hr的信号flow的位宽门。
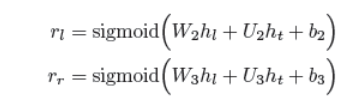
hl、hr和˜hlr之间的线性插值可以公式化为:
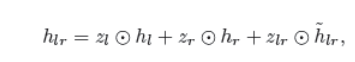
其中zl、zr和zlr为门控权重,zl+zr+zlr=→1,且
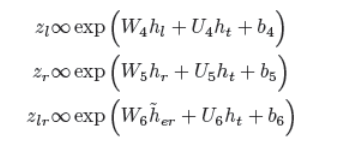
一个最终的说明是,我们对左语境、目标语境和右语境的池化结果进行维度还原,以得出hl、ht和hr。

在上式中,矩阵W1,W2,–,W9,U1,U2,–,U6和向量b1,b2,–,b9为模型参数。
训练方法
给定一组注解的训练例子,我们的模型被训练成最小化交叉熵损失目标,有一个l2正则化项,定义为
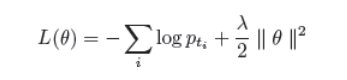
其中θ是模型参数集,pti是模型给出的第i个训练实例的概率,λ是正则化超参数。
我们应用在线训练,其中模型参数通过使用Adagrad(Duchi,Hazan和Singer,2011)进行优化。为了避免过度fitting,我们使用dropout技术(Hinton等人,2012),以固定的概率pdrop随机丢弃输入词嵌入的一些维度。
练,其中模型参数通过使用Adagrad(Duchi,Hazan和Singer,2011)进行优化。为了避免过度fitting,我们使用dropout技术(Hinton等人,2012),以固定的概率pdrop随机丢弃输入词嵌入的一些维度。
这篇关于Gated Neural Networks for Targeted Sentiment Analysis原文、翻译及代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






