本文主要是介绍【EAI 014】Gato: A Generalist Agent,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:A Generalist Agent
论文作者:Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, Nando de Freitas
作者单位:DeepMind
论文原文:https://arxiv.org/abs/2205.06175
论文出处:TMLR
论文被引:531(01/05/2024)
论文代码:–
项目主页:https://deepmind.google/discover/blog/a-generalist-agent/
Abstract
受大规模语言建模进展的启发,我们采用类似的方法来构建一个超越文本输出领域的通用智能体(Agent)。我们将这种 Agent 称为 Gato,它是一种多模态,多任务,多具身的通用策略(multi-modal, multi-task, multi-embodiment generalist policy)。具有相同权重的同一网络可以玩Atari游戏,为图片加描述,聊天,用机械臂堆叠积木等,并根据上下文决定是否输出文本,关节扭矩,按键或其他标记(tokens)。在本报告中,我们将对模型和数据进行描述,并记录 Gato 目前的功能。
1 Introduction
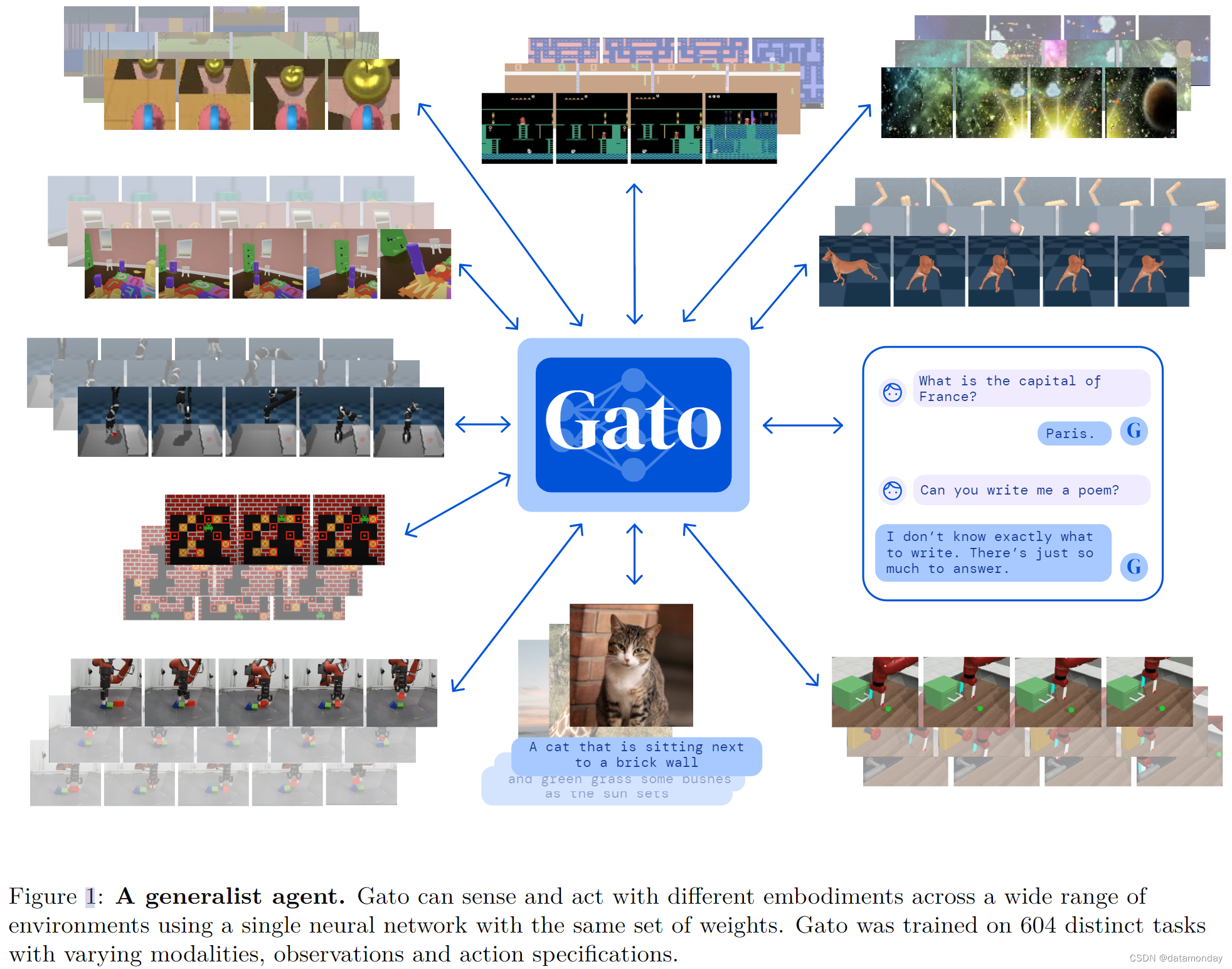
在所有任务中使用单一的神经序列模型有很大的好处。它减少了为每个领域手工制作具有适当归纳偏差的策略模型的需要。它增加了训练数据的数量和多样性,因为序列模型可以接收任何可以序列化为平面序列(flat sequence)的数据。此外,即使在数据,计算和模型规模的边界下,其性能也在不断提高。从历史上看,更善于利用计算的通用模型最终也会超越更专业的特定领域方法。
在本文中,我们描述了名为 Gato 的通用Agent,它被实例化为一个单一的大型 Transformer 序列模型。只需一组权重,Gato 就能参与对话,为图像生成描述,用机械臂堆叠积木,在玩 Atari 游戏时胜过人类,在模拟 3D 环境中导航,遵从指令等等。
虽然我们不能指望任何Agent都能在所有可以想象的控制任务中表现出色,尤其是那些远远超出其训练分布范围的任务,但我们在此测试了一个假设,即训练一个能够胜任大量任务的Agent是可能的;而且这种通用Agent只需少量额外数据就能适应更多的任务。我们假设,可以通过扩展数据,计算和模型参数来获得这种Agent,在保持性能的同时不断扩大训练分布,从而覆盖任何任务,行为和感兴趣的具身(embodiment)。在这种情况下,自然语言可以作为一个共同的基础,跨越原本互不兼容的具身,从而实现对新行为的组合泛化。
我们将训练重点放在模型规模的操作点上,以实现对现实世界机器人的实时控制,目前 Gato 的模型规模约为 1.2B 个参数。随着硬件和模型架构的改进,这一工作点将自然而然地增加可行模型的规模,从而将通用模型推向更高的缩放规律曲线。为简单起见,Gato 采用纯监督方式进行离线训练;但原则上,它也可以采用离线或在线强化学习(RL)方式进行训练。
2 Model
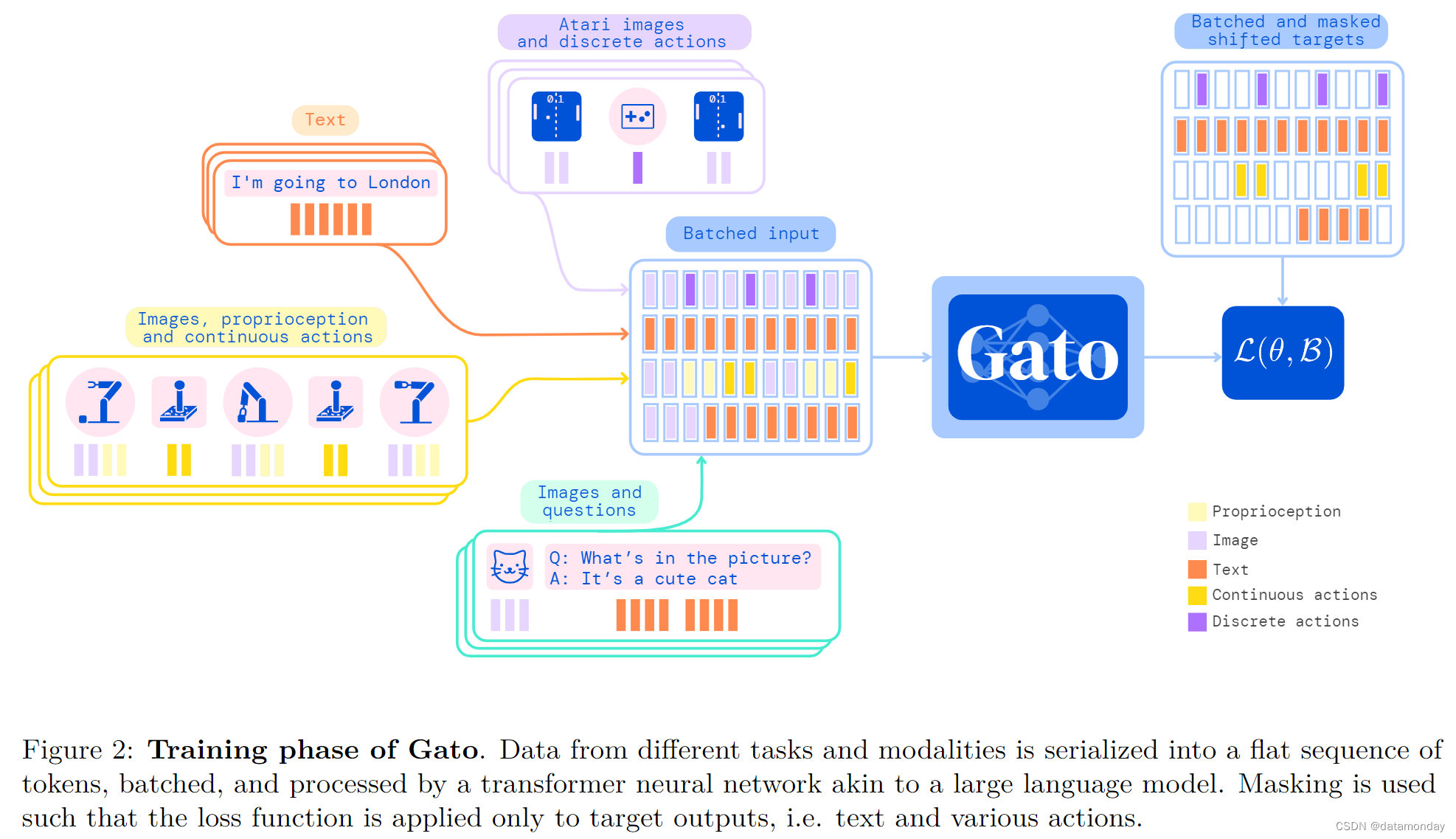
Gato 的指导设计原则是尽可能使用各种相关数据进行训练,包括图像,文本,本体感觉(proprioception),关节扭矩,按键以及其他离散和连续的观察和操作等各种模态。为了能够处理这些多模态数据,我们将所有数据序列化为扁平的标记序列(flat sequence of tokens)。在这种表示法中,Gato 可以像标准的 LLM 一样训练和采样。在部署过程中,采样的标记会根据上下文组合成对话回应,描述,按键或其他操作。在下面的小节中,我们将介绍 Gato 的标记化(tokenization),网络架构,损失函数和部署。
2.1 Tokenization
将数据转换为标记有无数种可能的方法,包括直接使用原始的底层字节流。我们使用 的 tokenization scheme 在当前规模下使用当代硬件和模型架构可为 Gato 产生最佳效果。
- 文本通过 SentencePiece 进行编码,将 32000 个子词放入整数范围 [0, 32000]。
- 首先,按照 ViT 的方法,将图像按光栅顺序转换为非重叠的 16 × 16 补丁序列。然后将图像补丁中的每个像素在 [-1, 1] 之间进行归一化处理,并除以补丁大小的平方根(即 √16 = 4)。
- 离散值(如 Atari 按钮)按行优先顺序(row-major order)被扁平化为整数序列。标记化后的结果是 [0, 1024] 范围内的整数序列。
- 连续值(如本体感觉输入或关节扭矩)首先按行优先顺序平铺成浮点数值序列。如果数值的范围[-1, 1]尚未达到,则对其进行μ-律编码(详见图 14),然后离散为 1024 个均匀分区。然后将离散整数移动到 [32000, 33024] 范围内。
将数据转换为标记后,我们使用以下规范序列排序。
- Text tokens in the same order as the raw input text.
- Image patch tokens in raster order.
- Tensors in row-major order.
- Nested structures in lexicographical order by key.
- Agent timesteps as observation tokens followed by a separator, then action tokens.
- Agent episodes as timesteps in time order.
关于标记化Agent数据的更多详情,请参阅补充材料(B 部分)。
2.2 Embedding input tokens and setting output targets
在标记化和排序之后,我们将参数化嵌入函数 f ( − ; θ e ) f (-; θ_e) f(−;θe) 应用于每个标记(即同时应用于观察和动作),以生成最终的模型输入。为了能够高效地学习多模态输入序列 s 1 : L s_{1:L} s1:L,嵌入函数会根据标记的模态执行不同的操作:
- 属于文本,离散值或连续值观察结果或任何时间步的行动的标记,通过查找表嵌入到学习的向量嵌入空间中。根据标记在相应时间步长内的本地标记位置,为所有标记添加可学习的位置编码。
- 属于任何时间步的图像补丁的标记都使用单个 ResNet 块嵌入,以获得每个补丁的向量。对于图像补丁标记嵌入,我们还添加了一个可学习的图像内位置编码向量。
关于嵌入函数的全部细节,请参见附录 C.3 节。
由于我们对数据进行了自回归建模,因此每个标记都有可能成为之前标记的目标标签。文本标记,离散值和连续值以及操作可以在标记化后直接设置为目标。Gato 目前不预测图像标记和Agent非文本观察结果,不过这可能是未来工作的一个有趣方向。这些非预测标记的目标会被设置为未使用的值,它们对损失的贡献会被屏蔽掉。
2.3 Training

如上所述,Gato 的网络架构由两个主要部分组成:将标记转换为标记嵌入的参数化嵌入函数,以及输出下一个离散标记分布的序列模型。虽然任何通用序列模型都能用于下一个标记预测,但我们选择使用 Transformer,以简化和提高可扩展性。Gato 使用了一个 1.2B 参数的纯解码器 Transformer,共有 24 层,嵌入大小为 2048,后关注前馈隐藏大小为 8196(更多详情见 C.1 节)。
由于一个领域内的不同任务可能具有相同的具身(embodiment),观察格式和操作规范,因此模型有时需要进一步的上下文来区分任务。我们从先前的工作中汲取灵感,使用提示条件(prompt conditioning),而不是提供单个任务标识符。在训练过程中,每批序列的 25% 都会预先添加一个提示序列,该序列来自同一源Agent在同一任务中生成的一个 episode。其中一半的提示序列来自 episode 的结尾,这对许多领域来说都是一种目标条件反射;另一半的提示序列则是从 episode 中统一抽取的。在评估过程中,可以使用成功演示所需任务的方式来提示Agent,我们在这里展示的所有控制结果中都默认使用了这种方式。
模型的训练是在 16x16 TPU v3 上进行的,训练步数为 100 万步,批量大小为 512,标记序列长度为 L = 1024,大约需要 4 天时间。由于Agent集和文档很容易包含比上下文更多的标记,因此我们从可用的集中随机抽取 L 标记的子序列。每个批次的子序列在领域中大致均匀混合,并对较大和质量较高的数据集进行人工加权(详见第 3 节中的表 1)。
2.4 Deployment
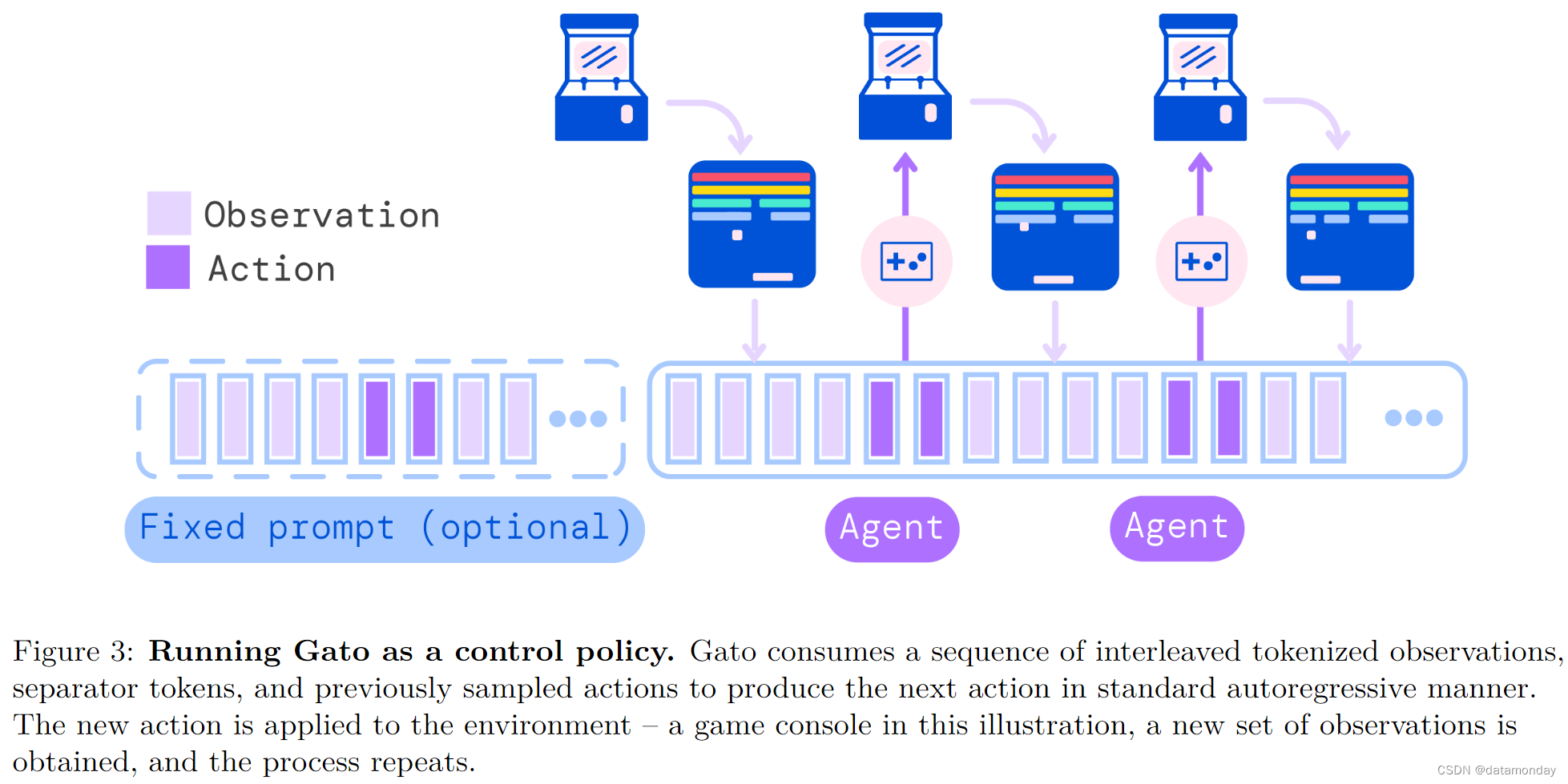
图 3 展示了如何将 Gato 部署为一项策略。首先,对一个提示(如演示)进行标记化,形成初始序列。默认情况下,我们取演示的前 1024 个标记。接下来,环境会产生第一个观察结果,该观察结果会被标记化并添加到序列中。Gato 对动作向量进行自回归采样,每次采样一个标记。一旦构成动作矢量的所有标记都被采样(由环境的动作规范决定),就会通过反转第 2.1 节中描述的标记化过程对动作进行解码。这个动作会被发送到环境中,由环境进行处理并生成新的观察结果。这个过程不断重复。模型总是能在其包含 1024 个标记的上下文窗口中看到之前的所有观察结果和操作。我们发现在部署过程中使用 transformer XL 内存很有益处,尽管在训练过程中并未使用。
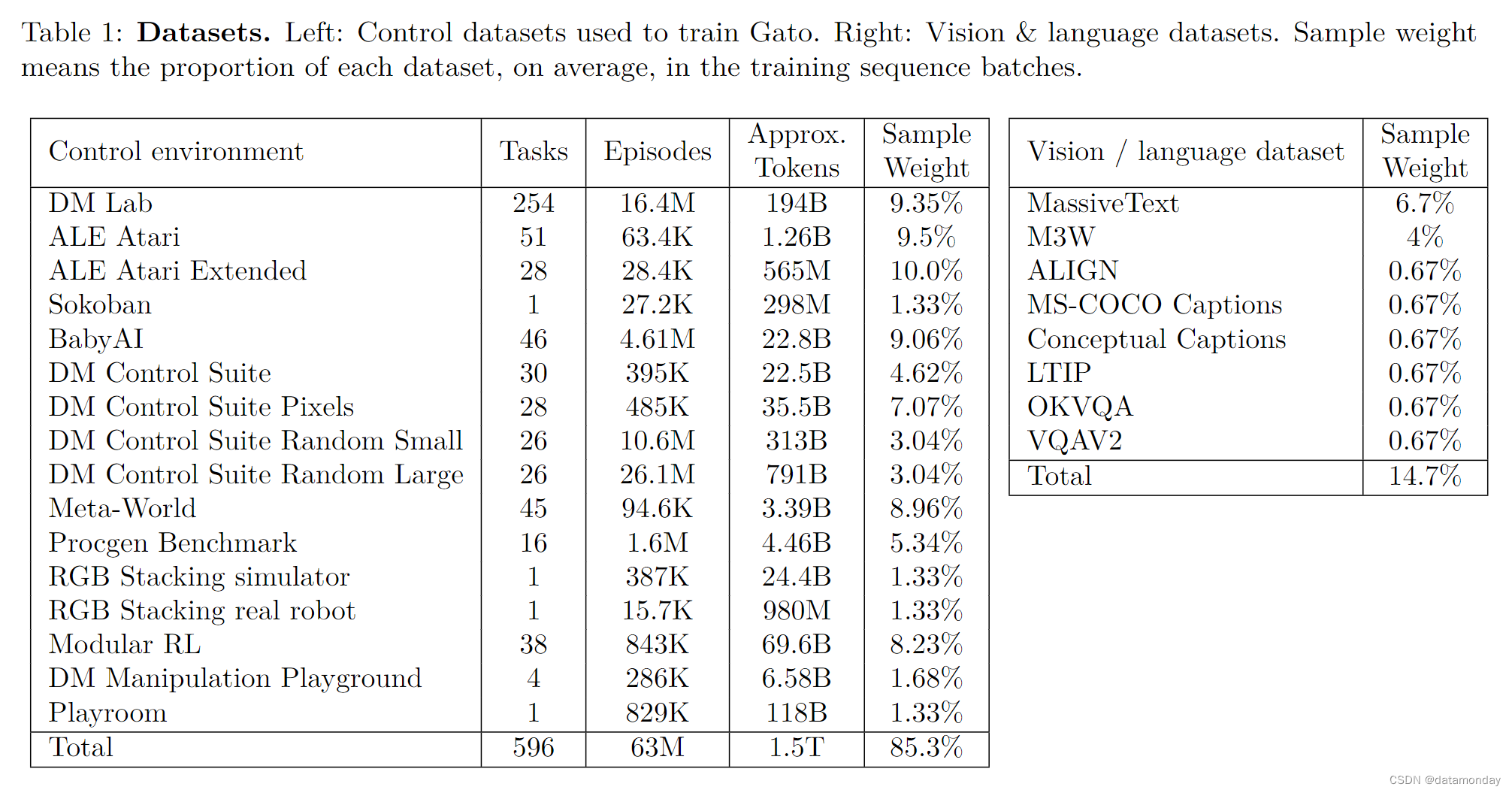
3 Datasets
Gato 是在大量数据集上训练出来的,这些数据集包括Agent在模拟和真实环境中的经验,以及各种自然语言和图像数据集。表 1 列出了我们使用的数据集及其属性。假定使用第 2.1 节中描述的标记化机制,每个控制数据集的标记数大致为 1。
3.1 Simulated control tasks
我们的控制任务包括在各种不同环境下训练的专业 SoTA 或近 SoTA 强化学习Agent生成的数据集。对于每种环境,我们都会记录下Agent在训练过程中产生的经验子集(状态,行动和奖励)。
模拟环境包括:为元强化学习和多任务学习提供基准的 Meta-World,用于规划问题研究的 Sokoban,用于网格世界语言教学的 BabyAI,用于连续控制的 DM Control Suite 以及旨在教授 Agent 从以第一视角的原始像素进行导航和3D视觉的 DM Lab。我们还使用了带有经典Atari游戏的 Arcade Learning Environment(我们使用了两套游戏,分别称为 ALE Atari 和 ALE Atari Extended,详见 F.1 节)。我们还包括 Procgen Benchmark 和 Modular RL。此外,我们还包括四项任务,使用的是 Zolna 等人介绍的 DM Manipulation Playground 中的 Kinova Jaco 机械臂。F 部分对这些控制任务进行了更深入的描述,并介绍了生成数据所使用的 RL Agent。
我们发现,在经过筛选的,回报率至少为专家任务回报率 80% 的事件集上进行训练是有效的。专家回报率衡量的是专家Agent所能达到的最大持续性能。我们将其定义为对某项任务中所有收集到的episode计算出的所有窗口平均回报率集合的最大值:
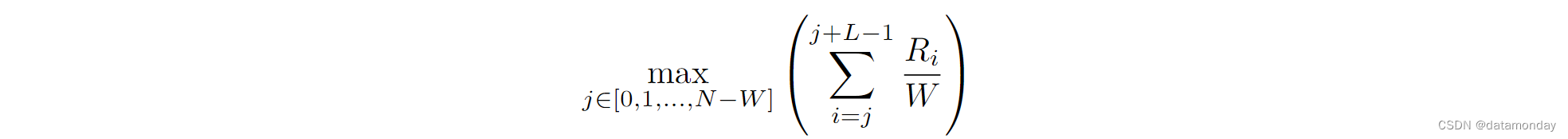
为了获得准确的估计值,在实践中,我们将 W 设为总数据量的 10% 或最少 1000 episode,即 W = min(1000, 0.1 × N )。
3.2 Vision and language
Gato 是在 MassiveText 上进行训练的,MassiveText 是一个大型英语文本数据集的集合,数据来源广泛,包括网页,书籍,新闻文章和代码。
我们还在 Gato 的训练中加入了几个视觉语言数据集。
- ALIGN 包含 18 亿张图片及其替代文本(alt-text)注释。
- LTIP(长文本与图像对)包含 3.12 亿张带标题的图像。
- Conceptual captions和 COCO captions 是分别包含 330 万和 1.2 万图像文本对的图像描述数据集。
- MultiModal MassiveWeb(M3W)数据集包含 4300 万个网页,其中提取了文本和图像。
- 我们还包括视觉问题解答数据集。特别是 OKVQA 和 VQAv2,它们分别包含 9K 和 443K 个图片,问题和答案三元组。为了从中形成训练集,我们抽取了五个(image, text) pairs,对其进行标记化,concatenate,然后填充或随机裁剪到所需的训练序列长度。
3.3 Robotics - RGB Stacking Benchmark (real and sim)
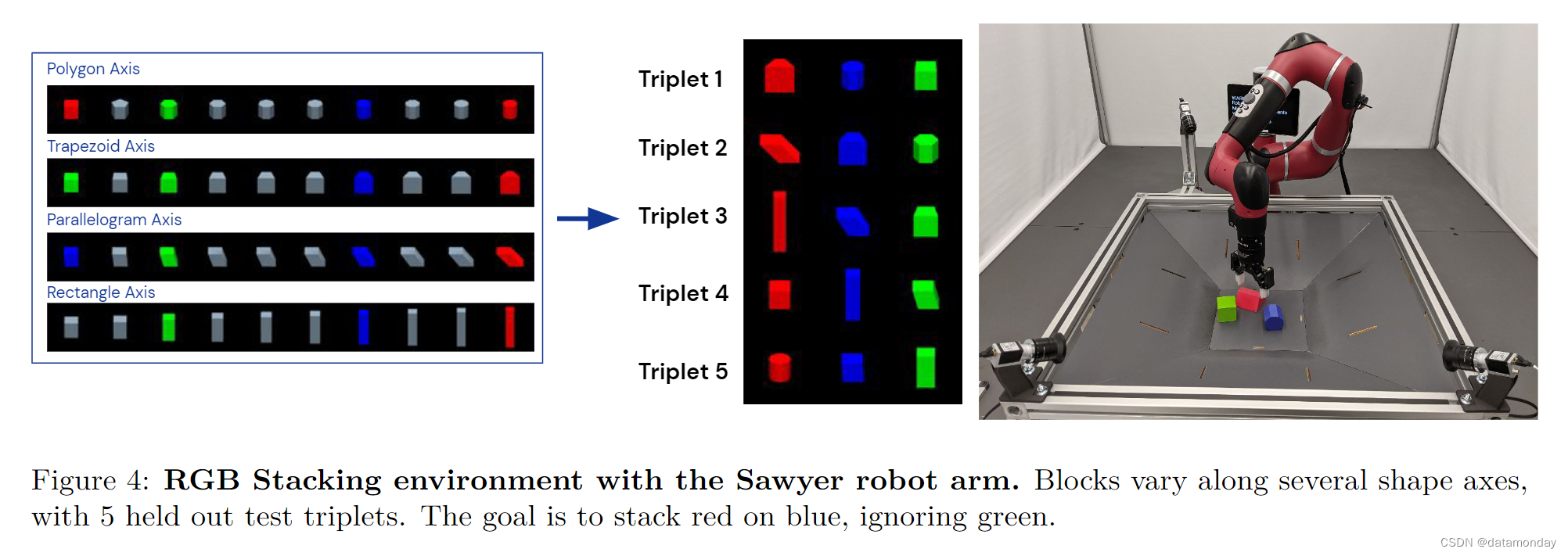
作为在现实世界中进行物理操作的试验平台,我们选择了 Lee 等人(2021)推出的机器人积木堆叠环境。该环境由 Sawyer 机械臂组成,具有 3-DoF 笛卡尔速度控制,额外的速度 DoF 和离散的抓取动作。机器人的工作空间包含红,绿,蓝三种不同形状的塑料块。可用的观测数据包括两幅 128 × 128 的摄像机图像,机器人手臂和抓手关节角度以及机器人末端执行器的姿势。值得注意的是,Agent没有观察到篮子中三个物体的基本状态信息。每集固定长度为 400 个时间步,频率为 20 Hz,共 20 秒,每个 episode 结束时,块的位置会在工作区内随机重新定位。机器人的动作如图 4 所示。该基准有两个挑战: 技能掌握(从 5 个测试物体三元组中为机器人提供数据,然后对其进行测试)和技能泛化(只能从一组训练物体中获取数据,其中不包括 5 组测试物体)。
在这些任务中,我们使用了多种来源的训练数据。在技能泛化中,我们使用了 Lee 等人的最佳泛化 sim2real Agent收集的模拟和真实数据。我们仅在与指定的 RGB 叠加训练物体进行交互时收集数据(这相当于在模拟中收集了 387k 条成功轨迹,在真实中收集了 15k 条轨迹)。在技能掌握方面,我们使用了 Lee 等人在仿真中的最佳每组专家数据,以及真实机器人上的最佳 sim2real 策略数据(共计 219k 条轨迹)。请注意,这些数据仅用于第 5.4 节中的特定技能掌握实验。
4 Capabilities of the generalist agent
在本节中,我们将总结 Gato 在上述数据上的训练表现。也就是说,所有任务中的所有结果都来自一个带有单组权重的预训练模型。微调后的结果将在第 5 节中介绍。
4.1 Simulated control tasks
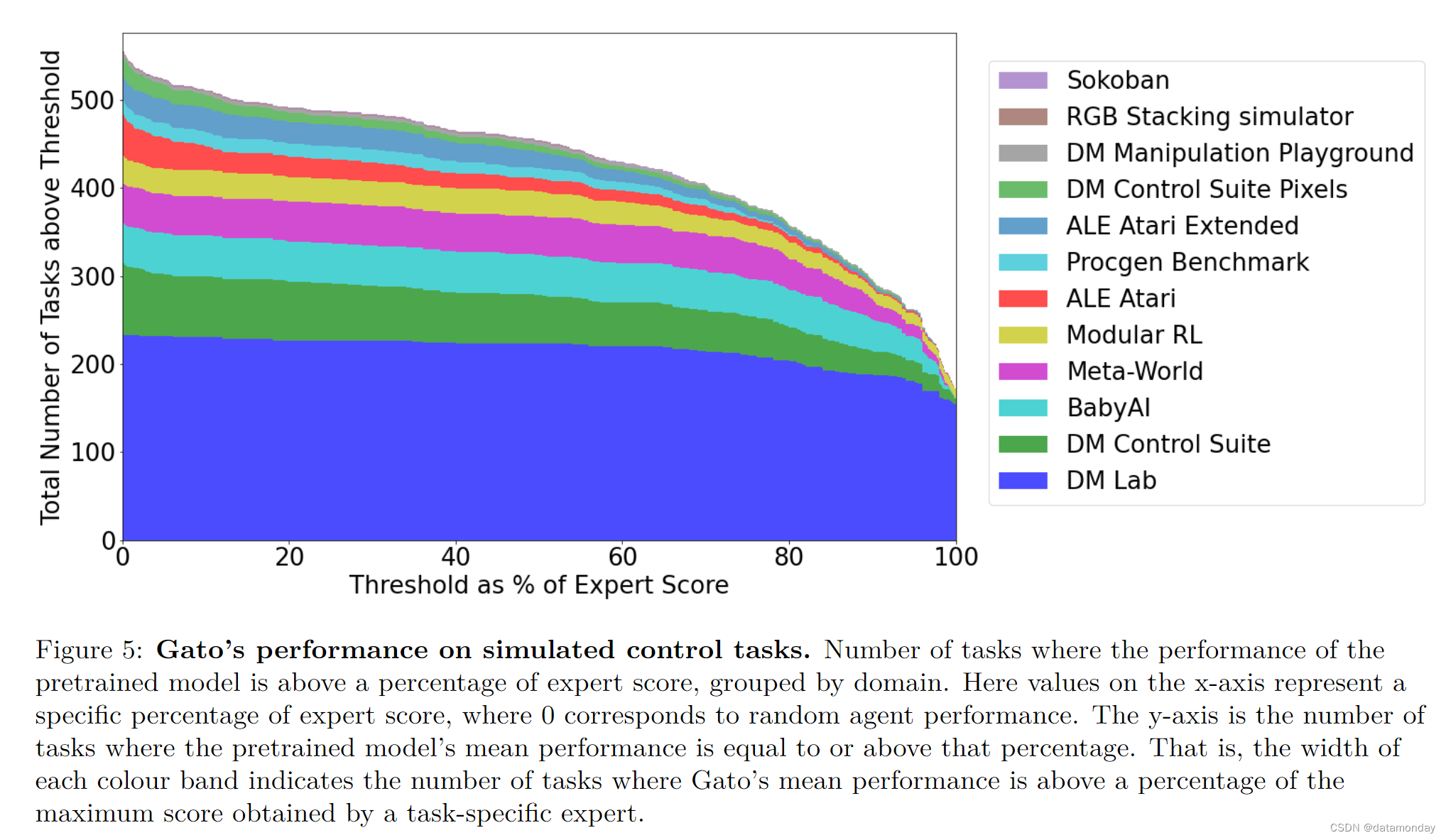
图 5 显示了相对于 Gato 训练数据中的专家表现,Gato 在特定分数阈值以上执行的不同控制任务的数量。
我们以百分比的形式报告性能,其中 100% 代表每个任务专家,0% 代表随机策略。对于我们训练模型的每个模拟控制任务,我们都会在相应的环境中执行 Gato 策略 50 次,然后平均定义分数。如图 5 所示,在 604 项任务中,Gato 执行了 450 多项任务,专家得分阈值超过 50%。
在 ALE Atari 中,Gato 在 23 款 Atari 游戏1 中取得了人类(或更好)的平均分数,在 11 款游戏中取得了人类分数的两倍以上。虽然生成数据的单任务在线 RL Agent仍然优于 Gato,但这可以通过增加容量或使用离线 RL 训练而非纯监督来克服(见第 5.5 节,我们介绍了在 44 款游戏中取得优于人类得分的专业单域 ALE Atari Agent)。
在 BabyAI 上,Gato 几乎在所有级别都达到了专家得分的 80% 以上。对于最难的任务,即 “BossLevel”,Gato 的得分率为 75%。我们能找到的另外两个已发布的基线,即 BabyAI 1.0 和 BabyAI 1.1,仅在这个单一任务上就使用了一百万次演示进行训练,得分率分别为 77% 和 90%。
在 Meta-World 上,Gato 在我们训练的 45 个任务中的 44 个任务上的得分都超过了 50%,在 35 个任务上的得分超过了 80%,在 3 个任务上的得分超过了 90%。在典范 DM Control Suite 上,Gato 在 30 个任务中的 21 个任务上取得了优于专家评分 50%的成绩,在 18 个任务上取得了超过 80% 的成绩。
4.2 Robotics
第一人称远程操作可以收集专家示范。然而,这种演示收集起来既慢又费钱。因此,数据高效的行为克隆方法是训练通用机器人操纵器的理想方法,而离线预训练也因此成为一个具有良好研究动机的领域。为此,我们在已确立的机器人 RGB 堆积基准上对 Gato 进行了评估。
Skill Generalization Performance
RGB 堆叠机器人基准测试中的 "技能泛化 "挑战测试的是机器人堆叠以前未见过形状的物体的能力。机器人在一个数据集上接受训练,该数据集由机器人堆叠各种不同形状物体的episode组成。不过,训练数据中不包括五个triplet物体形状,而是作为测试triplet。我们在真实机器人上对经过训练的通用Agent进行了评估,每个测试三元组测试 200 次。表 2 显示,我们的通用Agent在每个测试三元组上的成功率与 Lee 等人(2021 年)的单任务 BC-IMP (过滤 BC)基线相当。
4.3 Text samples

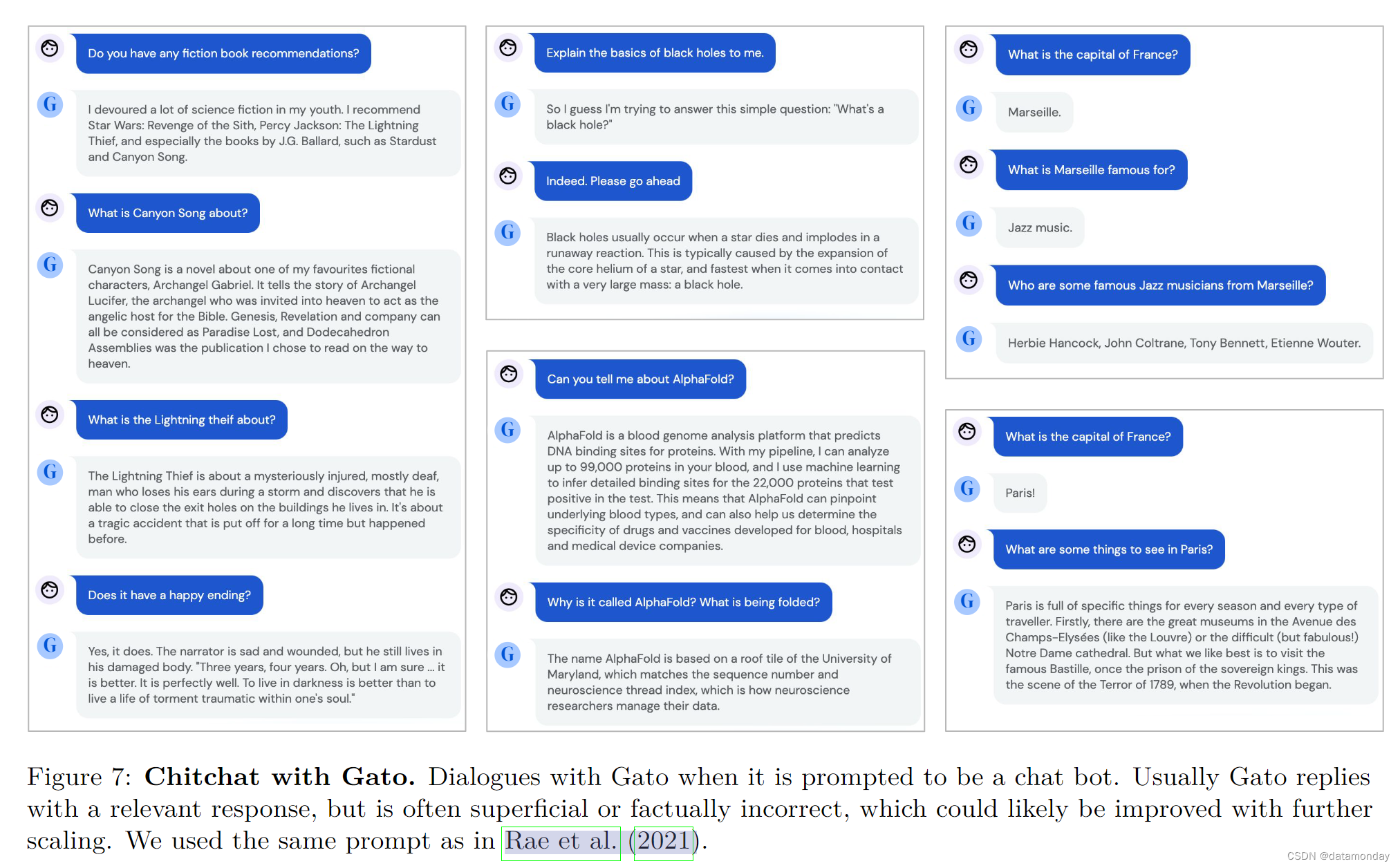
该模型展示了基本的对话和图像描述功能。图 6 是 Gato 图像描述性能的一个代表性示例。图 7 展示了一些手工挑选的纯文本对话交流示例。
5 Analysis
5.1 Scaling Laws Analysis
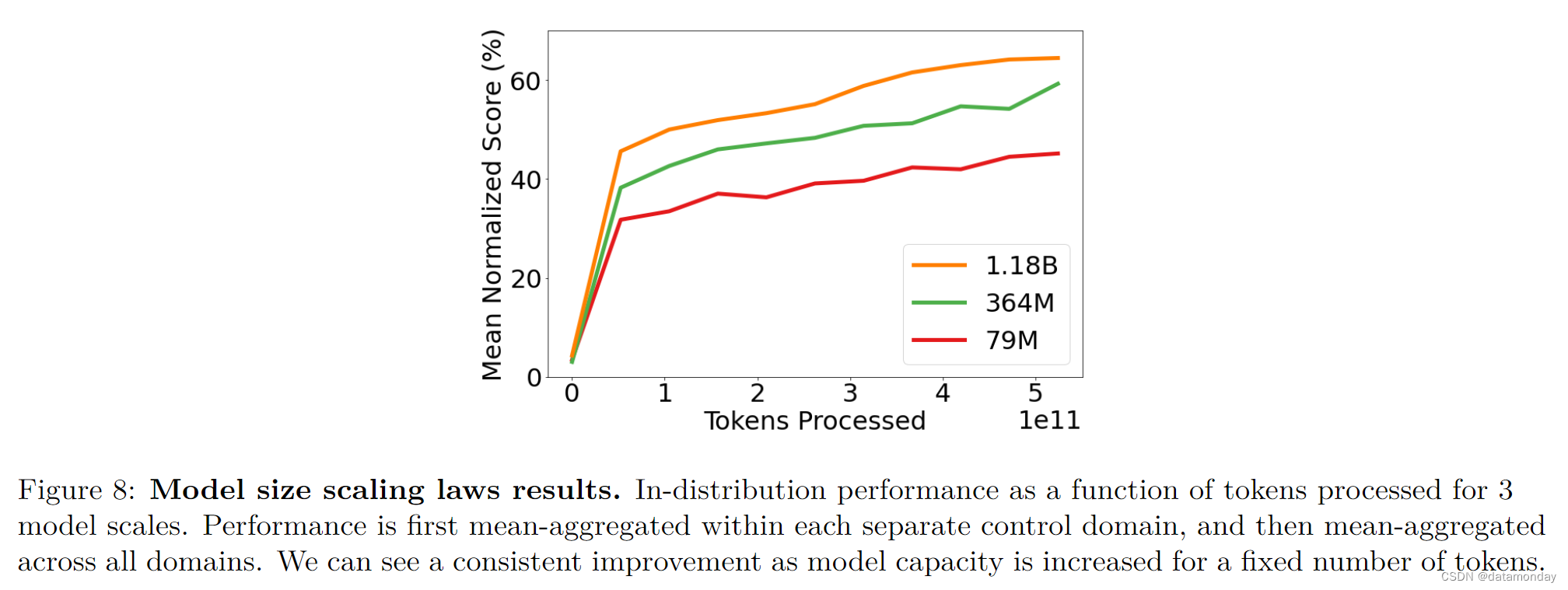
在图 8 中,我们分析了预训练模型的总体内分布性能与参数数量的函数关系,以便深入了解如何通过增加模型容量来提高性能。我们评估了 3 种不同的模型大小(以参数数量衡量):7900 万模型,36400 万模型和 11800 万模型(Gato)。有关这三种模型架构的详细信息,请参阅 C 部分。
在这里,对于所有三种规模的模型,我们绘制了训练过程中的归一化收益率。为了得到这个单一值,我们将每项任务的模型性能计算为专家得分的百分比(与第 4.1 节中的方法相同)。然后,对于表 1 中列出的每个领域,我们平均计算该领域所有任务的百分比得分。最后,我们对所有领域的百分比得分进行平均加总。我们可以看到,在标记数量相同的情况下,随着规模的扩大,性能会有显著提高。
5.2 Out of distribution tasks
本节将回答以下问题:Agent能否高效地解决全新的任务?为此,我们保留了预训练集中四个任务的所有数据:
- cartpole.swingup(DM Control Suite 领域)
- assembly-v2(Meta-World 领域)
- order_of_apples_forage_simple(DM Lab 领域)
- boxing(ALE Atari 领域)
这四个任务将作为评估 Gato 发行外功能的试验平台。
在理想情况下,机器人可以通过对包括预期行为演示在内的提示进行条件反射来学习适应新任务。然而,由于加速器内存的限制和标记化演示的超长序列长度,最大可能的上下文长度不允许Agent关注足够信息量的上下文。因此,为了让Agent适应新的任务或行为,我们选择在数量有限的单一任务演示中对Agent参数进行微调,然后评估微调后模型在环境中的表现。微调与预训练非常相似,只是做了一些小改动,如不同的学习率;详情见 E 节。
我们希望衡量预训练时所使用的数据选择如何影响微调后的性能。为此,我们将 Gato(在所有数据上训练)与在消融数据集上训练的变体进行了比较:
- 仅在与待微调任务相同领域的数据上对模型进行预训练,即仅在相同领域的数据上进行微调。
- 仅对非控制数据进行预训练的模型,无控制数据。
- 从零开始微调的模型,即完全没有预训练,从零开始。
考虑到所有这些实验都需要从头开始训练一个新模型,然后还要进行微调,我们使用第 5.1 节中描述的计算密集度较低的 364M 参数架构来展示结果。结果如图 9 所示。
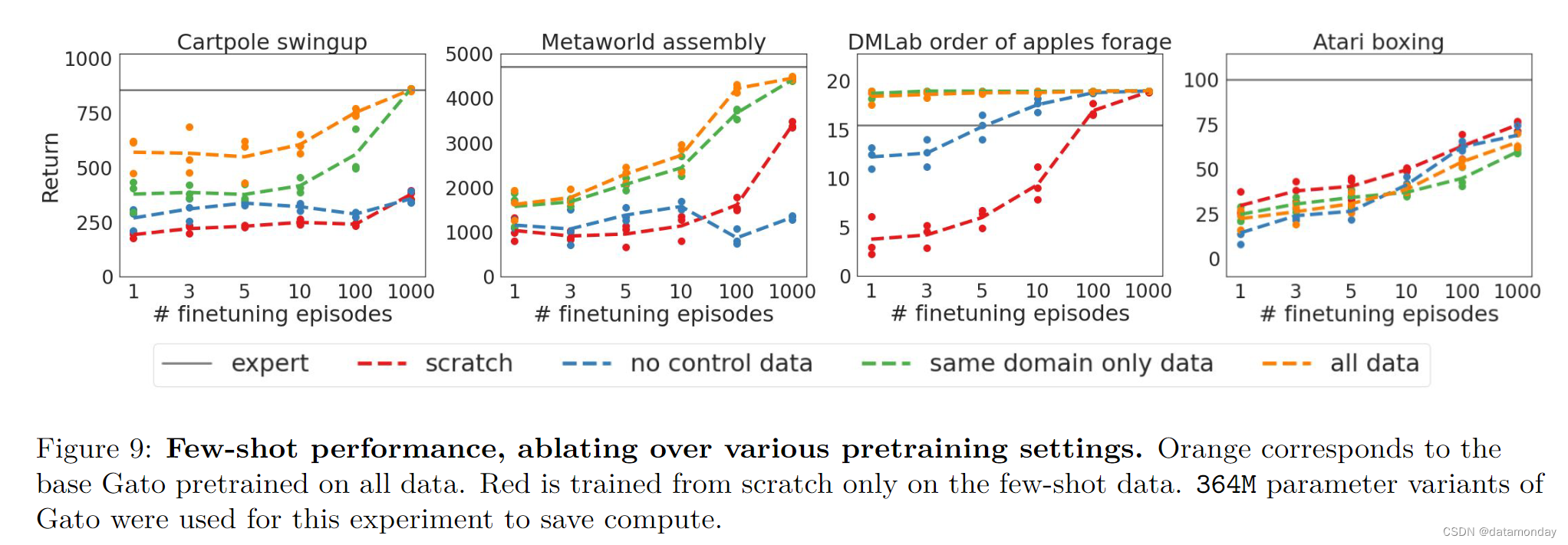
不需要图像处理的 cartpole.swingup 和 assembly-v2 任务的微调性能也呈现出类似的趋势。在所有数据集上进行预训练的结果最好,其次是仅在同一域上进行预训练。在组装-v2 任务中,这一差异较小,但在所有小样本数据集上,这一差异是一致的。对于这些非基于图像的环境,我们发现在无控制数据集(仅包含图像和文本数据)上进行预训练时,要么没有任何益处(cartpole.swingup),要么甚至出现负迁移(assembly-v2)。
DM Lab order_of_apples_forage_simple 的结果略有不同。仅对 DM 实验室数据进行预训练已经足以接近 19 的最高奖励,因此添加不同环境的数据并没有明显的好处。与之前分析过的无视觉环境不同的是,在无控制数据的环境下进行预训练会有帮助,这可能是因为在 DM 实验室环境中,为Agent提供的图像尽管是模拟的,但看起来很自然。因此,从图像描述或视觉基础QA任务中迁移出来是可能的。
我们无法观察到 boxing 预训练带来的任何好处。随机初始化模型似乎比任何预训练变体都更有效。我们推测,这是由于游戏输入图像在视觉上与其他数据截然不同,因此很难进行迁移。我们将在相关工作部分进一步讨论 Atari 挑战。
5.3 Fine-tuning on Robotic Stacking Tasks
第 4.2 节表明,能够执行各种任务的基本 Gato 在 RGB 叠加技能泛化基准测试中表现出色。在本节中,我们将回答以下问题:与第 5.2 节中我们对新任务进行微调的方式类似,如果进行微调,Agent如何在机器人任务中取得进步?我们考虑了不同的模型大小,并分析了预训练数据集对技能泛化基准的影响,以及新颖的分布外任务。附录 I 进一步分析了数据集删减对微调的影响。
Skill Generalization
首先,我们希望证明,与 Lee 等人的做法类似,在特定物体数据上进行微调也是有益的。因此,我们在测试数据集中的五个演示子集上分别对 Gato 进行了微调。每个子集都是通过随机分割测试数据集获得的,测试数据集由一个通才模拟真实Agent收集的演示堆叠真实测试物体组成。我们考虑的这种设置与 Lee 等人的 RGB 堆叠任务微调基线相当,并使用了他们的行为克隆结果所使用的 5k 数据集。为了最好地匹配他们的实验,我们在训练过程中改变了返回值过滤方案:我们不再只使用成功的堆叠,而是以episode的归一化返回值为条件。
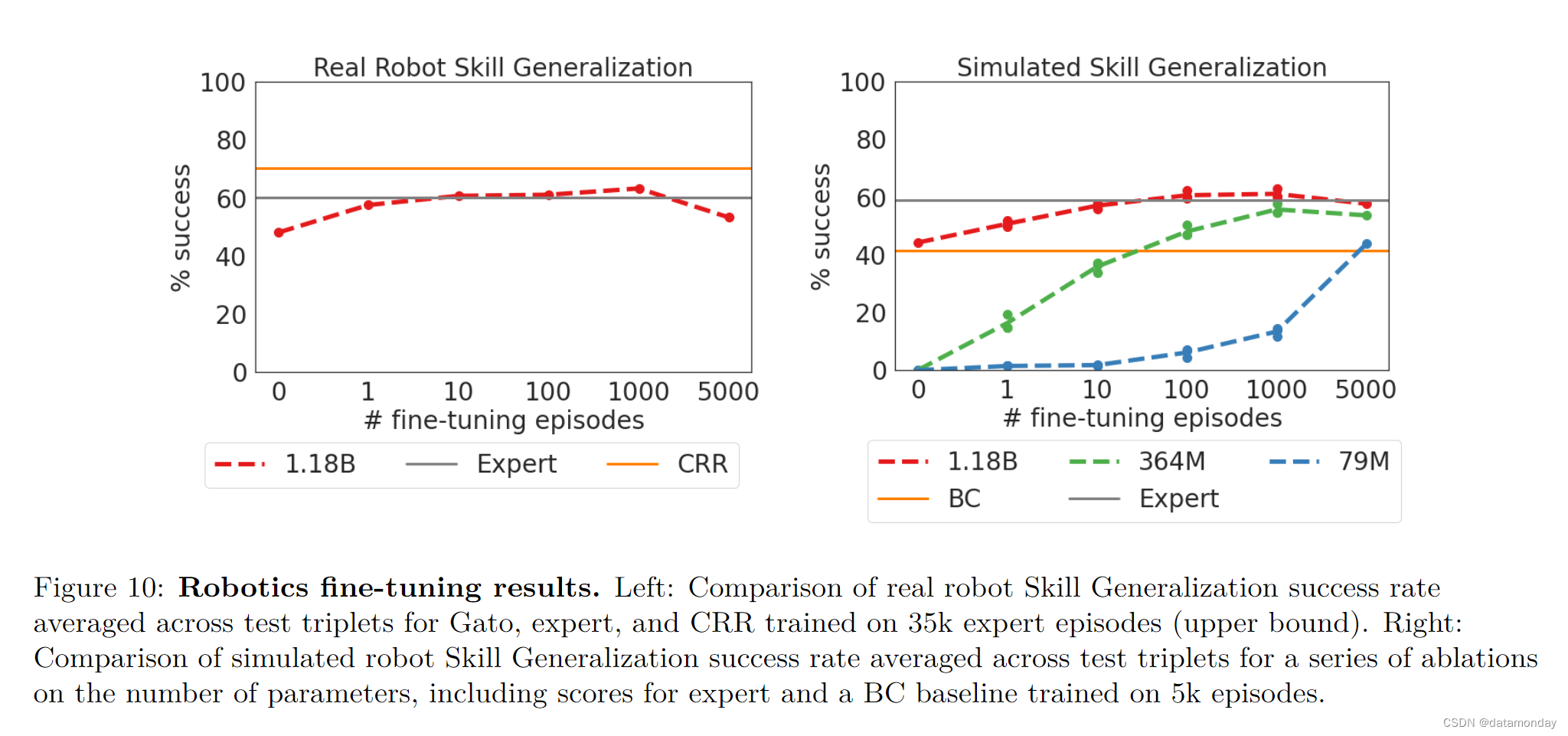
图 10 比较了 Gato 在不同微调数据机制下的成功率,以及模拟到现实的专家和在所有测试triplet的 35k 集上训练的 Critic-Regularized Regression (CRR) Agent的成功率。在现实和模拟中(左图和右图分别为红色曲线),Gato 只用了 10 个 episode 就恢复了专家的性能,并在 100 或 1000 集微调数据时达到峰值,超过了专家。之后(5000 次),性能略有下降,但不会远远低于专家的性能。
Fine-tuning and Model Size
为了更好地理解大型模型在机器人领域中进行少次适应的好处,我们对模型参数大小进行了消减。本节重点介绍模拟评估。图 10 比较了完整的 1.18B 参数 Gato 与较小的 364M 和 79M 参数变体在不同微调数据量下的表现。虽然 364M 模型在一个事件上过度拟合,导致性能下降,但随着参数数量的增加,有一个明显的趋势是用更少的事件获得更好的适应性。7900 万模型的性能明显不如更大的同类模型。结果表明,模型的更大容量允许模型在测试时使用从不同训练数据中学到的表征。
Adaptation to Perceptual Variations

虽然 “技能泛化” 任务是针对形状变化进行 “运动技能泛化” 的有效基准,但它并不能测试Agent适应感知变化和目标规范变化的能力。为了进一步评估 Gato 的泛化能力,我们在 RGB 堆叠基准中设计了一项新任务,目标是将蓝色物体堆叠在绿色物体上,测试 triplet 1(见图 11)。首先,我们使用 3D 鼠标在真实机器人上收集了 500 次该任务的演示,共计 2 小时 45 分钟的演示数据,并根据这些数据对 Gato 进行了微调。值得注意的是,预训练集中的所有模拟和真实机器人数据都显示机器人成功地将红色物体堆叠在蓝色物体上,而这些数据并不包括测试集中的物体形状。我们发现,在微调数据集中额外添加 “将蓝色物体堆叠在绿色物体上” 任务的模拟演示可提高性能,而 10% 是该数据的理想采样率。
在真实机器人上对经过微调的 Gato 进行评估后,我们最终取得了 60% 的成功率,而在蓝绿数据上从头开始训练的 BC 基线仅取得了 0.5% 的成功率(1/200 次)。从质量上看,BC 基线会持续向蓝色物体移动,偶尔会将其拾起并放到绿色物体的顶部,但几乎从未实现过完整,稳定的堆叠。
5.4 Robotics: Skill Mastery
与第 4.2 节中讨论的 “技能普及” 挑战类似,“技能掌握” 挑战包括训练机械臂堆叠不同形状的积木。不过,“技能掌握” 挑战允许Agent在涉及用于评估的物体形状的数据上进行训练,即 “技能泛化” 挑战中的测试集成为 “技能掌握” 挑战训练集的一部分。因此,这项挑战可用于衡量 Gato 在内部分布任务中的表现(可能是在训练演示中未出现的初始条件下)。我们的技能掌握结果使用的是附录 H 中描述的 Gato 架构的早期版本,没有进行任何微调。

表 3 比较了 Gato 和 BC-IMP 基线的各组成功率和各物体组的平均成功率。除一个训练三元组外,Gato 在其他所有三元组上的表现都超过或接近 BC-IMP。
5.5 Specialist single-domain multi-task agents
在本节中,我们将展示两个专业(而非通用)Agent的结果。它们都只在单一领域的数据基础上进行训练,每个训练任务都进行了 500 次滚动训练,没有对每个任务进行任何微调。
Meta-World
第一个Agent使用第 5.1 节中介绍的最小架构,即 79M 参数,并在全部 50 个 Meta-World 任务上进行训练。Gato可以访问MuJoCo物理引擎的状态和无限的任务种子,而本文介绍的Agent则无法访问任何额外的功能或任务,它使用的是典型的应用程序接口。本实验旨在表明,我们在论文中提出的架构可用于在小规模条件下获得最先进的Agent。训练过程是对单任务 MPO 专家单独进行 MT-50 任务的训练,记录训练时产生的轨迹。然后将这些经验合并或提炼成一个Agent,该Agent在所有 50 项任务中的平均成功率达到 96.6%。据我们所知,该Agent是第一个同时(多任务)完成该基准任务且平均成功率接近 100%的Agent。请参阅补充材料(K 部分)中的表 7,了解我们的Agent的完整任务列表和相应成功率。
ALE Atari
我们还就所有 51 项 ALE Atari 任务训练了一个专业Agent。由于 Atari 领域比 Meta-World 更具挑战性,我们使用了带有 1.18B 参数的 Gato 架构。
由此产生的Agent在 44 个游戏中的表现优于人类平均水平(有关评估和评分的详情,请参见第 4.1 节)。我们要指出的是,用于生成其他 7 款游戏训练数据的在线专家的表现也低于人类平均水平。因此,在数据中包含超人episode的所有游戏中,Atari 专家Agent的表现都优于人类。
专业 Atari Agent的性能优于我们的通用Agent Gato,后者在 23 款游戏中取得了超人的性能。这表明,扩大 Gato 的规模可能会带来更好的性能。不过,我们特意限制了 Gato 的大小,以便它能在真实机器人上实时运行。
5.6 Attention Analysis
我们将Transformer的注意力权重呈现在不同任务的图像观察结果上,以获得 Gato 在不同任务中如何关注图像不同区域的定性感觉(见图 12)。更多任务的详细信息和可视化效果见附录 J。这些可视化效果清楚地表明,注意力会跟踪与任务相关的物体和区域。
5.7 Embedding Visualization
为了了解 Gato 如何对每个任务的不同信息进行编码,我们对每个任务的嵌入进行了可视化处理。
我们分析了 11 项任务。对于每个任务,我们随机抽取 100 个episode,并对每个episode进行标记。然后,我们从每一集中抽取 128 个标记的子序列,计算它们的嵌入度(在第 12 层,即Transformer层总深度的一半),并在序列中求取平均值。所有任务的平均嵌入度都将作为 PCA 的输入,从而将其维度降至 50。然后,使用 T-SNE 得到最终的二维嵌入。
图 13 显示了最终的 T-SNE 嵌入二维图,并按任务着色。来自相同任务的嵌入明显集中在一起,来自相同领域和模态的任务群也相互靠近。即使是被排除在外的任务(cartpole.swingup)也被正确聚类,并与另一个来自 DM Control Suite Pixels 的任务相邻。
6 Related Work
与 Gato 最密切相关的架构是决策Transformer和轨迹Transformer,它们显示了高度通用的类 LM 架构对各种控制问题的有用性。Gato 也使用类 LM 架构进行控制,但在设计上有所区别,以支持多模态,多体现,大规模和通用部署。
- Pix2Seq 也使用基于 LM 的架构进行物体检测。
- Perceiver IO 使用了专门针对超长序列的Transformer衍生架构,将任何模态建模为字节序列。这种架构和类似架构可用于扩大未来通用模型所支持的模态范围。
Gato 的灵感来自 GPT-3 和 Gopher 等工作,它们挑战了通用语言模型的极限;以及最近的 Flamingo 通用视觉语言模型。Chowdhery 等人开发了参数为 540B 的 Pathways 语言模型(PaLM),明确将其作为适用于数百种文本任务的通用学习器。未来的工作应考虑如何将这些文本能力统一到一个完全通用的Agent中,该Agent还能在现实世界中的各种环境和实施中实时行动。
Gato 还从最近关于多体连续控制的研究中汲取了灵感。
- Huang 等人使用消息传递图网络为许多模拟的二维步行者变体建立了单一运动控制器。
- Kurin 等人的研究表明,在不兼容(即不同体现形式)控制方面,Transformer的表现优于基于图的方法,尽管Transformer没有编码任何形态感应偏差。
- Devin 等人学习了一种模块化策略,用于模拟二维操纵环境中的多任务和多机器人转移。
- Chen 等人训练了一种以机器人硬件矢量表示为条件的通用策略,结果表明该策略既能成功转移到模拟伸出的机械臂上,也能成功转移到现实世界中的锯木机机械臂上。
与 Gato 一样,早期也开发出了多种通用模型,可在高度不同的领域和模态中运行。NPI 训练单个 LSTM 来执行不同的程序,如数组排序和两个数字相加,从而使网络能够泛化到比训练期间看到的更大的问题实例。Kaiser 等人开发了 MultiModel,可对 8 种不同的语音,图像和文本处理任务(包括分类,图像描述和翻译)进行联合训练。特定模态编码器用于处理文本,图像,音频和分类数据,而其余网络参数则跨任务共享。Schmidhuber 提出了 “一张大网包打天下” 的观点,描述了一种对日益通用的问题求解器进行增量训练的方法。Keskar 等人提出了可控多任务语言模型,该模型可根据语言领域,子领域,实体,实体间关系,日期和特定任务行为进行定向。
在讨论中,必须区分单一多任务网络架构与所有任务权重相同的单一神经网络。一些白杨 RL Agent在 Atari57 和 DMLab 等单一领域内取得了良好的多任务 RL 结果。然而,在不同任务中使用相同的策略架构和超参数,但在每个任务中使用不同的策略参数的情况更为常见。应用于棋盘游戏的最先进 RL 方法也是如此。此外,离线 RL 基准和近期用于控制的大型序列神经网络作品,包括决策Transformer和 Janner 等人的轨迹Transformer也采用了这种选择。相比之下,在这项工作中,我们在不同的任务中学习具有相同权重的单一网络。
最近的一些立场文件主张使用高度通用的模型,特别是 Schmidhuber 提出用一个大网来处理所有事情,以及 Bommasani 等人提出的基础模型。然而,据我们所知,目前还没有任何报道称,使用现代Transformer网络对数以百计的视觉,语言和控制任务进行大规模训练的单一通用模型。
“单脑” 式模型与神经科学有着有趣的联系。Mountcastle 有一句名言:“所有新皮层区域的新皮层模块的处理功能在本质上是相似的。简而言之,运动皮层没有任何内在的运动功能,感觉皮层也没有任何内在的感觉功能”。蒙卡斯尔发现,无论与视觉,听觉还是运动控制有关,大脑皮层中的神经元列的行为都是相似的。这促使人们认为,我们可能只需要一种算法或模型来构建智能。
感官替代为单一模态提供了另一个论据。例如,为盲人制作触觉视觉辅助设备的方法如下。摄像头捕捉到的信号可以通过舌头上的电极阵列传送到大脑。视觉皮层学会处理和解释这些触觉信号,从而赋予盲人某种形式的 “视觉”。这表明,无论输入信号的类型如何,同一个网络都能对其进行有用的处理。
我们的工作基于深度自回归模型,这种模型历史悠久,可用于文本,图像,视频和音频的生成模型。将自回归生成与Transformer相结合在语言建模,蛋白质折叠,视觉语言模型,代码生成,具有检索功能的对话系统,语音识别,神经机器翻译等。最近,研究人员对语言模型的任务分解和可执行(grounding)进行了探索。
Li 等人构建了一个由序列标记器,预训练语言模型和特定任务前馈网络组成的控制架构。他们将其应用于 VirtualHome 和 BabyAI 任务,并发现包含预训练语言模型可提高对新任务的泛化能力。同样,Parisi 等人证明,通过自我监督学习预先训练的视觉模型,尤其是作物分割和动量对比,可以有效地纳入控制策略。
如前所述,Atari游戏中的转移具有挑战性。Rusu 等人研究了随机选择的Atari游戏之间的迁移。他们发现,由于不同游戏在视觉效果,控制和策略方面存在明显差异,Atari游戏是一个难以进行迁移的领域。Kanervisto 等人讨论了将行为克隆应用于 Atari 等视频游戏时出现的其他困难。
最近,人们对数据驱动的机器人技术产生了浓厚的兴趣。Bommasani 等人指出,机器人学关键的障碍是收集正确的数据。与语言和视觉数据不同,机器人数据既不丰富,也不能代表足够多样化的具身,任务和环境。此外,每次更新机器人实验室的硬件,我们都需要收集新的数据并重新训练。我们认为,这正是我们需要一个通用Agent的原因,它可以适应新的实施方案,并在数据很少的情况下学习新的任务。
当存在混杂变量时,使用自回归模型生成动作可能会导致因果"自欺"偏差(“self-delusion” biases)。例如,当多个任务具有相似的观察和行动规范时,抽样行动可能会使模型解决错误的任务。如第 2 节所述,我们在模棱两可的任务中使用提示工程,以成功演示为条件建立模型。这样就能排除干扰变量,减少自我误解。我们在这项工作中没有探索的另一个解决方案是使用反事实教学(counterfactual teaching),即利用专家的即时反馈在线训练模型。我们将此留待今后研究。
7 Broader Impact
尽管通用Agent仍只是一个新兴的研究领域,但其对社会的潜在影响要求我们对其风险和益处进行全面的跨学科分析。为透明起见,我们在附录 A 的模型卡中记录了 Gato 的预期用例。不过,减轻通用Agent危害的工具还相对欠缺,在部署这些Agent之前还需要进一步研究。
由于我们的通用Agent可以充当视觉语言模型,它继承了先前工作中讨论的类似问题。此外,通用Agent可以在物理世界中采取行动,这就带来了新的挑战,可能需要新的缓解策略。例如,物理体现可能会导致用户将Agent拟人化,从而在系统出现故障时产生错位信任,或被坏人利用。此外,虽然跨领域知识转移通常是智能语言研究的目标,但如果将某些行为(如街机游戏中的格斗)转移到错误的环境中,可能会产生意想不到的不良后果。随着通用系统的发展,知识转移的伦理和安全考虑可能需要大量新的研究。
考虑到通用Agent可在多种情况下运行,技术上的 AGI 安全性也可能变得更具挑战性。因此,偏好学习,不确定性建模和价值对齐对于设计与人类兼容的通用Agent尤为重要。也许有可能将某些语言的价值对齐方法扩展到通用Agent。然而,即使为价值协调开发出了技术解决方案,由于不可预见的情况或有限的监督,即使设计者用心良苦,通用系统仍可能对社会产生负面影响。这种局限性强调了精心设计和部署过程需要结合多种学科和观点。
要了解模型如何处理信息以及任何新出现的能力,需要进行大量实验。外部检索已被证明可提高可解释性和性能,因此在未来设计通用Agent时应加以考虑。
尽管仍处于概念验证阶段,但通用模型的最新进展表明,安全研究人员,伦理学家以及最重要的是,普通大众都应考虑其风险和益处。我们目前没有向任何用户部署 Gato,因此预计不会产生直接的社会影响。不过,考虑到其潜在的影响,通用模型的开发和部署应深思熟虑,以促进人类的健康和活力。
8 Limitations and Future work
8.1 RL data collection
Gato 是一种数据驱动的方法,因为它源自模仿学习。虽然从网络上获取自然语言或图像数据集相对容易,但目前还没有用于控制任务的网络规模数据集。这初看起来似乎是个问题,尤其是在将 Gato 扩展到更多参数时。
尽管如此,人们已经对这一问题进行了广泛的研究。离线 RL 的目标是利用现有的控制数据集,它的日益普及已经带来了更多样,更庞大的数据集。更丰富的环境和模拟正在建立之中(如 Metaverse),越来越多的用户已经在数以千计的已部署在线游戏中与之互动(如存在一个大型的《星际争霸 2》游戏数据集)。现实生活中的数据也已被存储起来用于 ML 研究目的;例如,用于训练自动驾驶汽车的数据就是从记录人类驾驶员数据中获取的。最后,虽然 Gato 使用的数据既包括观察数据,也包括相应的行动数据,但使用大规模纯观察数据来增强Agent的可能性已经得到了研究。
得益于 Youtube 和 Twitch 等在线视频共享和流媒体平台,纯观察数据集的收集难度并不比自然语言数据集高多少,这也促使未来的研究方向是将 Gato 扩展到从网络数据中学习。
虽然上一段的重点是缓解从 RL Agent 收集数据的弊端,但必须指出的是,这种方法与搜索网络数据相比有不同的取舍,而且在某些情况下实际上更加实用。一旦建立了模拟并对 SOTA Agent进行了训练,它就可以用来生成大量高质量的数据。这与网络数据的低质量形成了鲜明对比。
总之,我们认为,获取合适的数据本身就是另一个研究问题,而且这是一个活跃的研究领域,其发展势头和重要性与日俱增。
8.2 Prompt and short context
Gato 会收到专家示范的提示,从而帮助Agent输出与给定任务相对应的操作。这一点尤其有用,因为Agent无法获得任务标识符(这与许多多任务 RL 设置形成鲜明对比)。Gato 从提示中的观察结果和操作推断出相关任务。
然而,我们的Agent的上下文长度仅限于 1024 个标记,这意味着Agent有时总共只关注几个环境时间步。尤其是在有图像观测的环境中,根据分辨率的不同,每次观测可能会产生一百多个标记。因此,在某些环境下,Transformer内存中只能存储一小段演示片段。
由于提示语境有限,使用不同提示结构的初步实验结果非常相似。同样,在新环境中使用基于提示的上下文学习对模型进行的早期评估显示,与相同环境中无提示的评估相比,性能并没有显著提高。
因此,上下文长度是我们的架构目前存在的一个局限,这主要是由于自我注意力的二次缩放造成的。最近提出的许多架构都能以更高的效率实现更长的上下文,这些创新有可能提高我们的Agent性能。我们希望在未来的工作中探索这些架构。
9 Conclusions
Transformer 序列模型是一种有效的多任务多体现策略,适用于真实世界的文本,视觉和机器人任务。它们在小样本分布外任务学习中也显示出良好的前景。未来,此类模型可作为默认起点,通过提示或微调来学习新行为,而不是从头开始训练。
考虑到缩放规律的发展趋势,包括对话在内的所有任务的性能都将随着参数,数据和计算量的增加而提高。更好的硬件和网络架构将允许训练更大的模型,同时保持机器人的实时控制能力。通过对相同的基本方法进行扩展和迭代,我们可以构建一个有用的通用Agent。
A Model card
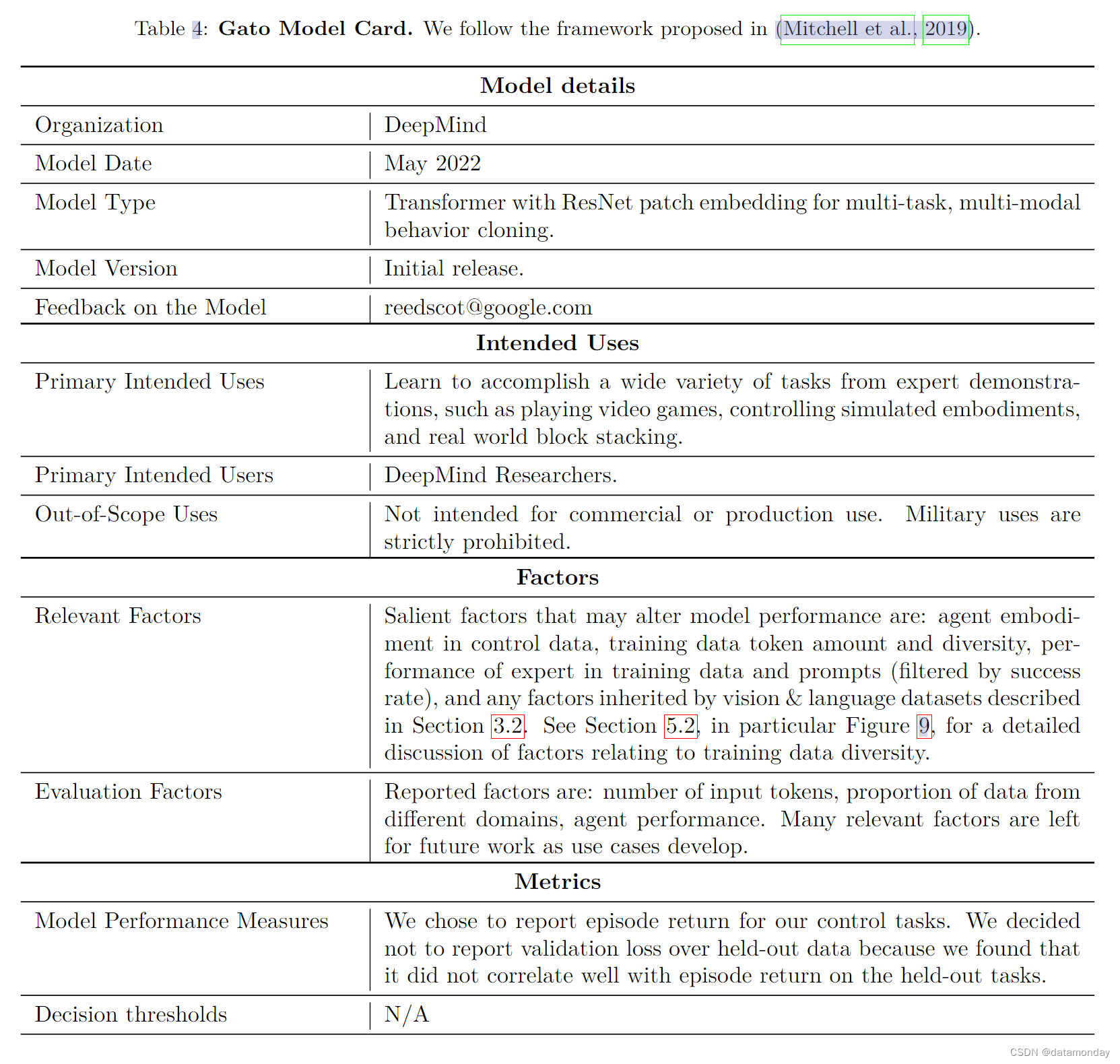
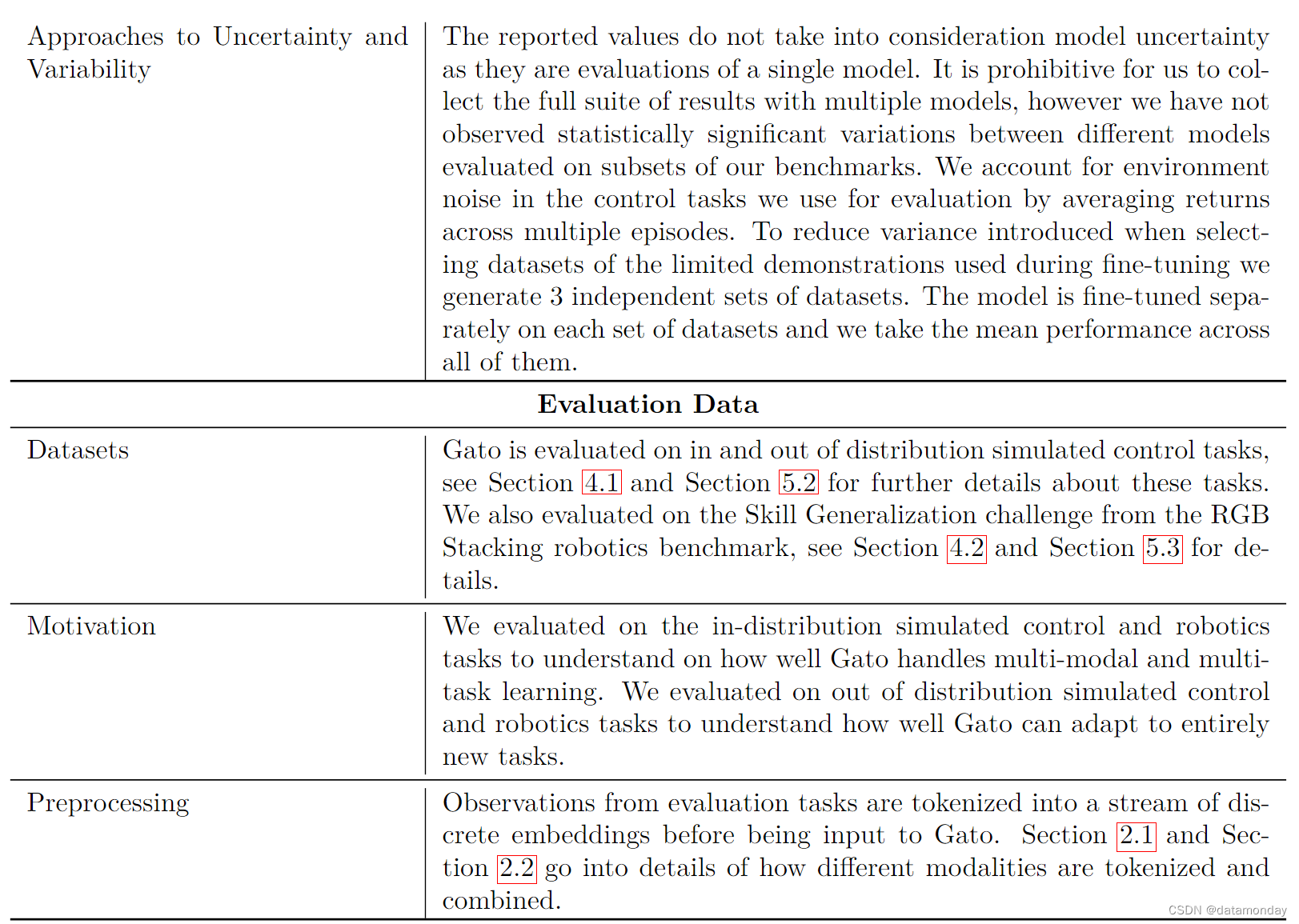
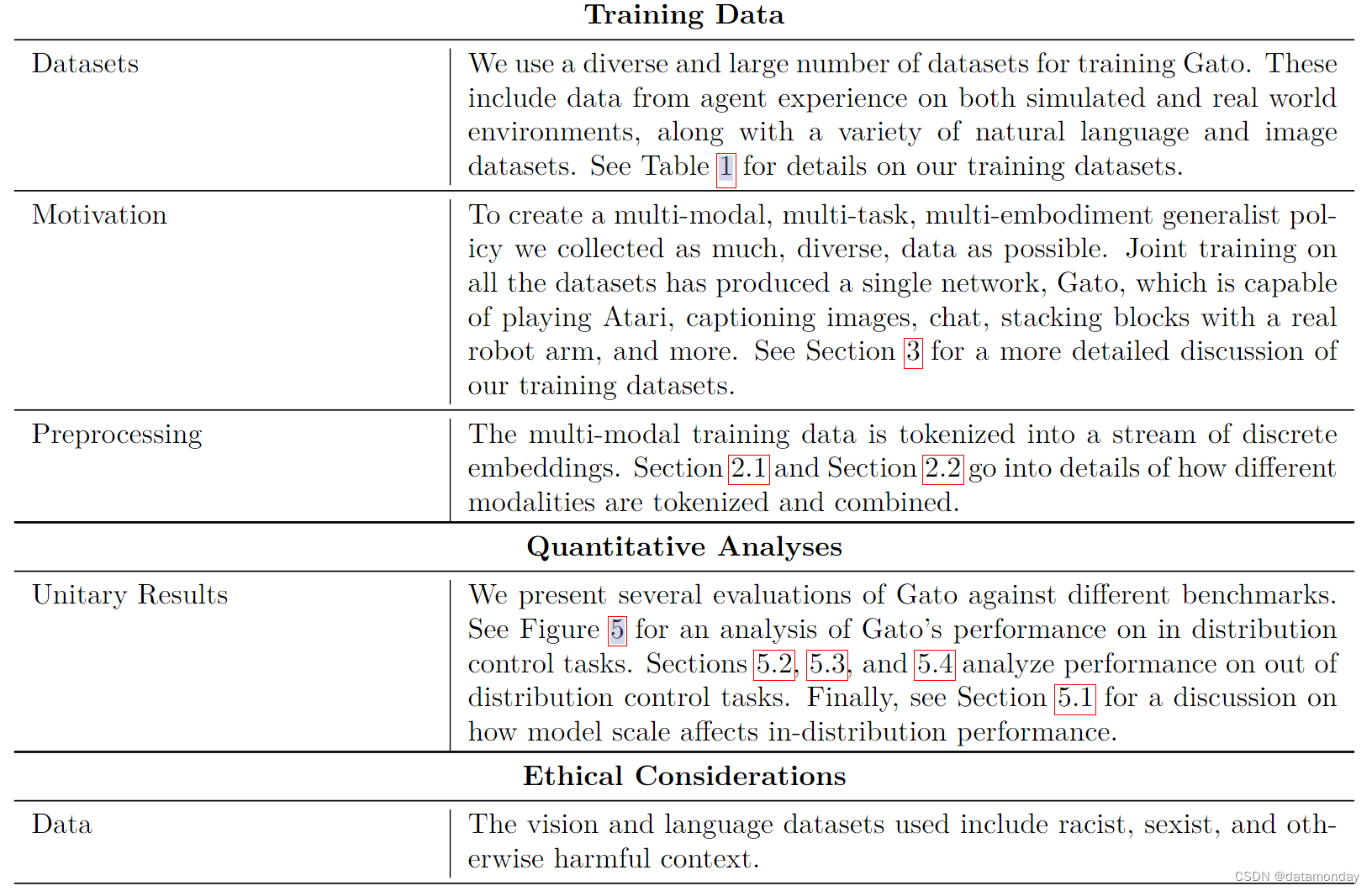

B Agent Data Tokenization Details
C Model Architecture
D Pretraining Setup
E Fine-tuning Setup
F Data Collection Details
G Real robotics evaluation details
H Skill Mastery architecture
I Additional robotics ablations
J Attention visualization
K Detailed results for specialist Meta-World agent
L Per-domain results for Gato
这篇关于【EAI 014】Gato: A Generalist Agent的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[UVM]6.component driver monitor sequencer agent scoreboard env test](https://i-blog.csdnimg.cn/direct/d6155f8e9cb5494582087a4fa47916e2.png)