generalist专题
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
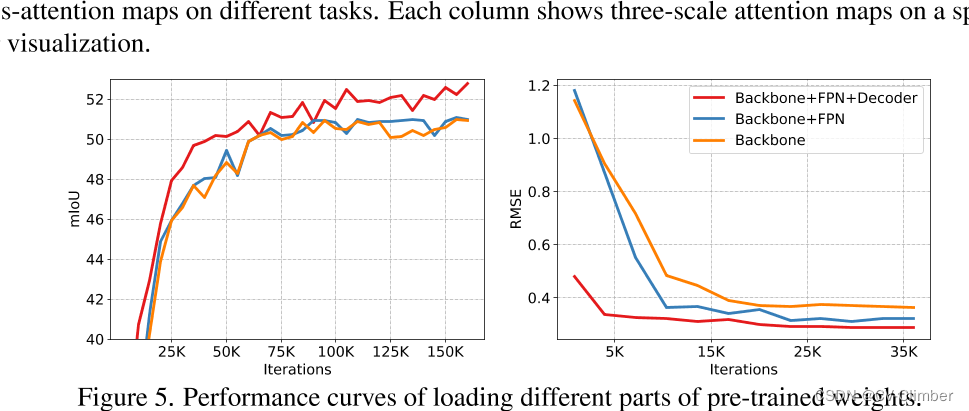
1 研究目的 现在存在的问题是: 目前,尽管自监督预训练方法(如Masked Autoencoder)在迁移学习中取得了成功,但对于不同的下游任务,仍需要附加任务特定的子架构,这些特定于任务的子架构很复杂,需要在下游任务上从头开始训练,这使得大规模预训练的好处无法得到充分利用,制了预训练模型的通用性和效率。 为了解决这个问题,论文提出了: GLID预训练方法,该方法通过统一预训练和
GiT: Towards Generalist Vision Transformer through Universal Language Interface
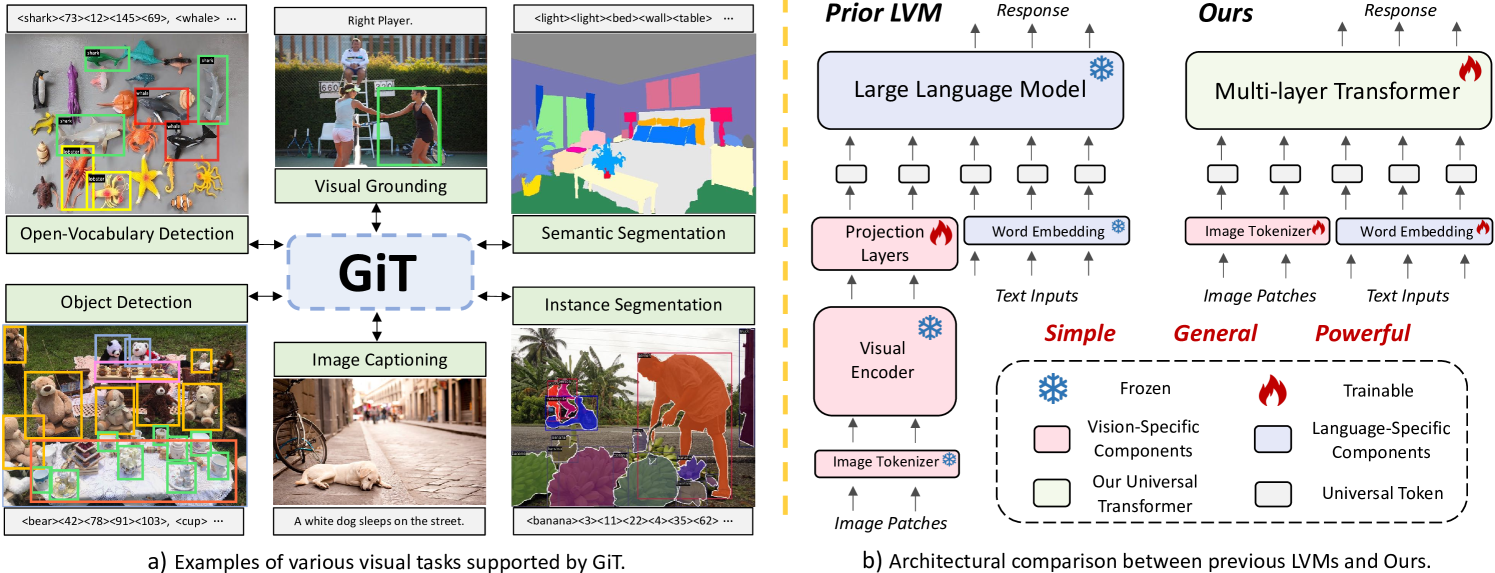
GiT: Towards Generalist Vision Transformer through Universal Language Interface 相关链接:arxiv github 关键字:Generalist Vision Transformer (GiT)、Universal Language Interface、Multi-task Learning、Zero-shot T

【EAI 014】Gato: A Generalist Agent
论文标题:A Generalist Agent 论文作者:Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenbe
AGI之Agent:《A Generalist Agent一个通用型代理—Gato》翻译与解读
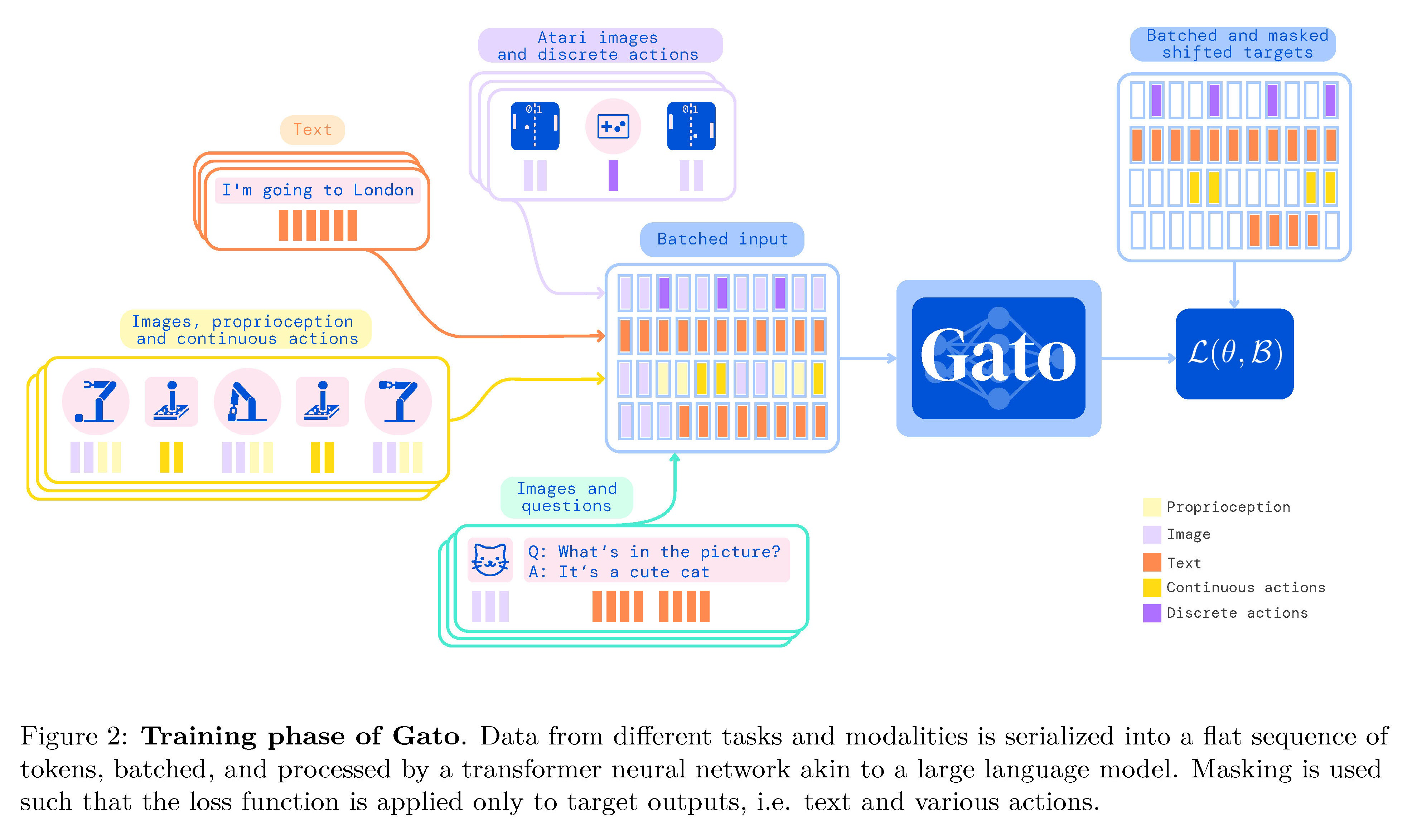
AGI之Agent:《A Generalist Agent一个通用型代理—Gato》翻译与解读 导读;该论文提出了一个名为Gato的通用智能代理,其主要贡献点如下: 背景痛点: >> 传统智能代理模型需针对每个具体域和任务进行专门设计,难以覆盖广泛任务。比如强化学习方法通常需要为每个单独的环境和任务设计专门的模型,增加了工程复杂度,限制了它们的灵活性和广泛性。 >> 使用不同网络模型训练不

【论文阅读笔记】InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
【论文阅读笔记】StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation 论文阅读笔记论文信息引言动机挑战 方法结果 关键发现相关工作1. 视觉语言基础模型2. 视觉通用模型 方法/模型视觉任务的统一说明训练数据构建网络结构 实验设计关键点检测分割图像增强图像编