本文主要是介绍AGI之Agent:《A Generalist Agent一个通用型代理—Gato》翻译与解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AGI之Agent:《A Generalist Agent一个通用型代理—Gato》翻译与解读
导读;该论文提出了一个名为Gato的通用智能代理,其主要贡献点如下:
背景痛点:
>> 传统智能代理模型需针对每个具体域和任务进行专门设计,难以覆盖广泛任务。比如强化学习方法通常需要为每个单独的环境和任务设计专门的模型,增加了工程复杂度,限制了它们的灵活性和广泛性。
>> 使用不同网络模型训练不同任务效率低下,模型参数不易复用。
>> 传统方法难以充分利用数据规模的优势,难以在多个领域取得较好的效果。
>> 不同领域和任务的数据难以整合训练;
解决方案:
>> 提出一个通用统一的多模态多任务代理Gato,采用单个神经网络实现各种环境和任务。使用单一的跨领域通用Transform模型,实现不同模态、不同表征和不同载体的多任务多表征智能控制;
>> 使用类Transformer结构的神经网络对Token序列进行预测,实现单一网络模型覆盖不同任务。将所有的输入数据(包括文本、图像、运动数据等)序列化为单个token序列, batch后送入Transformer网络进行训练,并通过掩码函数只将预测目标设置目标,实现大规模多源数据的自监督学习;
>> 训练时采用遮蔽机制,仅对目标输出部分计算损失。引入提示条件来区分不同任务,并通过 masking函数只对目标输出 LOSS。
>> 对观测和动作进行统一的token表示,方便跨模态学习。训练数据来源广泛,包含语言、视觉、控制等多个领域600多种具体任务的数据。在604个控制环境上训练,包含仿真环境和现实机器人环境。
核心特点:
>> 统一模型架构,提高模型规模利用效率。实现了单一网络模型覆盖不同任务和不同媒介下的控制能力。
>> 不同任务可共享相同参数和数据表示,实现泛化学习。
>> 多模态数据可通用化表示,有利知识迁移。
>> 采用单一权重实现跨多个控制任务和语言对话任务的智能代理;
>> 能处理含视觉、运动和自然语言的复杂环境;支持语言对话、图像描述、机器人控制等广泛应用。可在限定规模下实现实时机器人控制。
>> 实现几百个控制任务的性能,同时也展示了对新任务快速适应的能力;
优势:
>> 有效减少为每个具体任务设计专门模型的工作量。充分利用计算资源训练大规模数据;模型性能随数据量和规模的增加继续提升;证实了通过扩大模型规模和数据规模可以实现通用代理这一假设。
>> 增强数据利用率,一个模型学习数据共享能力。
>> 微调后可实现新任务快速学习能力。可在多个领域(如对话、图像描述、游戏玩家等)表现出色。
>> 提供了一种通用化学习方法的新思路。相比专项学习,该通用学习方法学习效率更高。在机器人堆叠任务上与专家方法效果相当。
文章通过实验结果展示,Gato在许多控制和语言任务上都表现出优良的能力,并通过更大规模的数据训练可以不断提升其综合水平。该工作具有很重要意义,为建立通用智能代理奠定了基础。
目录
《A Generalist Agent》翻译与解读
Abstract
Figure 1: A generalist agent. Gato can sense and act with di˙erent embodiments across a wide range of environments using a single neural network with the same set of weights. Gato was trained on 604 distinct tasks with varying modalities, observations and action specifications.图1:通用代理。Gato可以使用相同一组权重在各种环境中感知和行动,采用不同的具象。Gato在604个不同的任务上进行了训练,涉及不同的模态、观察和动作规范。
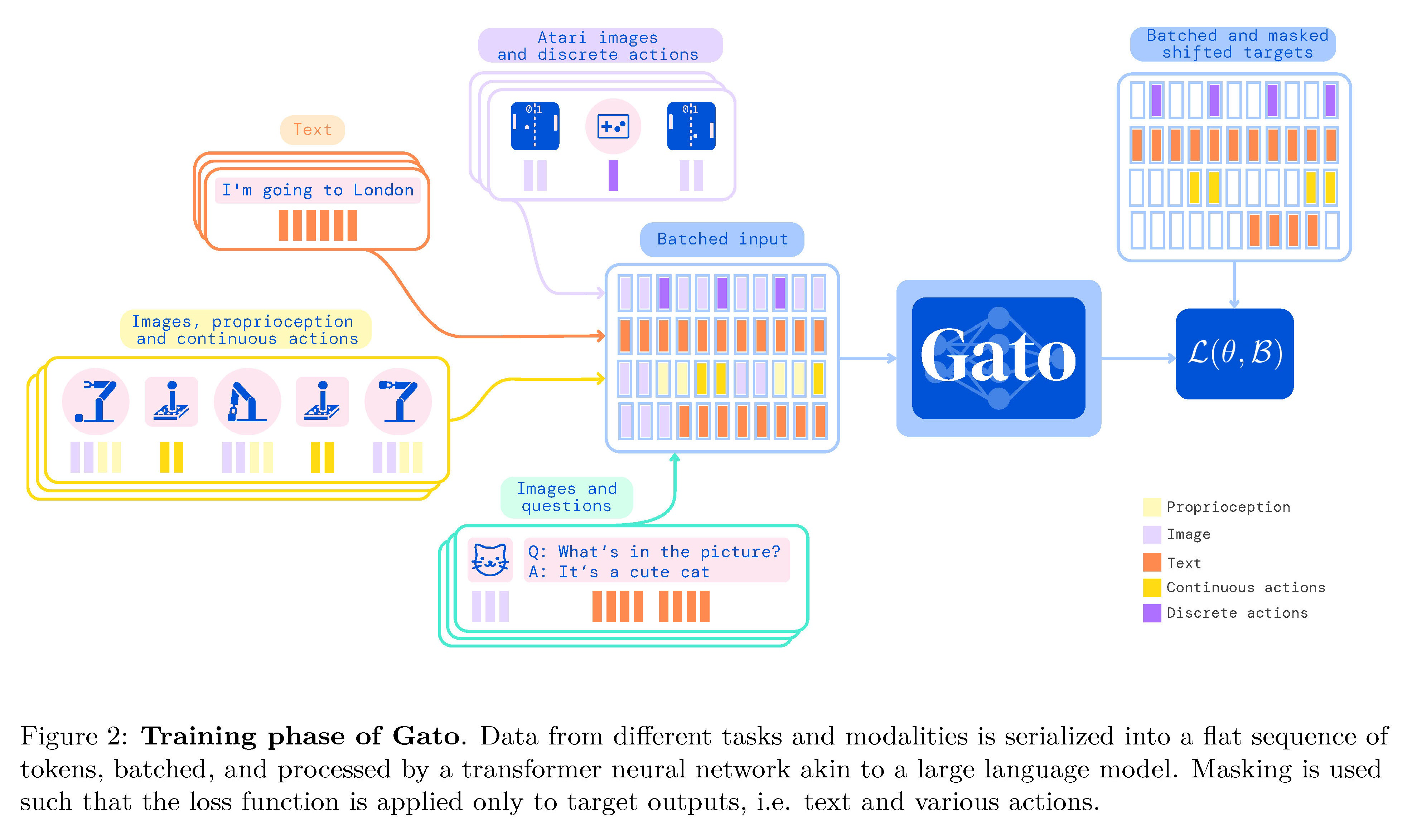
Figure 2: Training phase of Gato. Data from di˙erent tasks and modalities is serialized into a flat sequence of tokens, batched, and processed by a transformer neural network akin to a large language model. Masking is used such that the loss function is applied only to target outputs, i.e. text and various actions.图2:Gato的训练阶段。来自不同任务和模态的数据被串行化为一系列令牌,进行批处理,并由类似于大型语言模型的Transformer神经网络处理。掩码被使用,使损失函数仅应用于目标输出,即文本和各种动作。
1 Introduction引言
2 Model模型
2.1 Tokenization令牌化
2.2 Embedding input tokens and setting output targets嵌入输入令牌并设置输出目标
9 Conclusions
References
《A Generalist Agent》翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2205.06175 |
| 时间 | 2022年5月12日 |
| 作者 | Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, Nando de Freitas DeepMind |
| 总结 | 该论文描述了一个通用性代理程序Gato的开发,该代理程序是一个多模态、多任务、多体现形的通用政策。 >> Gato使用同一组权重进行训练,可以执行各种任务,如玩Atari游戏、给图像加注释、参与对话、使用真实机械臂堆叠方块等。 >> 该论文探讨了一个假设,即训练一个能够执行大量任务的代理程序是可能的,并且这个通用代理程序可以通过最少的附加数据适应成功执行更多任务。 >> 训练过程涉及将数据序列化为标记,并使用Transformer神经网络进行处理。 >> 文件提供了有关标记化方案、网络架构、损失函数和Gato部署的详细信息。 >> 研究的关键发现包括成功训练Gato在604个不同任务上,这些任务具有不同的模态,并展示了其在各种环境中的能力。 |
Abstract
| Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato. | 受到大规模语言建模的进展启发,我们采用类似的方法构建一个超越文本输出领域的通用代理。该代理被称为Gato,作为一种多模态、多任务、多具体现的通用策略。具有相同权重的相同网络可以在Atari游戏中玩耍、给图像加注释、聊天、用真实的机器人臂堆叠方块等等,根据上下文决定是输出文本、关节扭矩、按钮按压还是其他令牌。在本报告中,我们描述了Gato的模型和数据,并记录了其当前的能力。 |
Figure 1: A generalist agent. Gato can sense and act with di˙erent embodiments across a wide range of environments using a single neural network with the same set of weights. Gato was trained on 604 distinct tasks with varying modalities, observations and action specifications.图1:通用代理。Gato可以使用相同一组权重在各种环境中感知和行动,采用不同的具象。Gato在604个不同的任务上进行了训练,涉及不同的模态、观察和动作规范。
Figure 2: Training phase of Gato. Data from di˙erent tasks and modalities is serialized into a flat sequence of tokens, batched, and processed by a transformer neural network akin to a large language model. Masking is used such that the loss function is applied only to target outputs, i.e. text and various actions.图2:Gato的训练阶段。来自不同任务和模态的数据被串行化为一系列令牌,进行批处理,并由类似于大型语言模型的Transformer神经网络处理。掩码被使用,使损失函数仅应用于目标输出,即文本和各种动作。
1 Introduction引言
| There are significant benefits to using a single neural sequence model across all tasks. It reduces the need for hand crafting policy models with appropriate inductive biases for each domain. It increases the amount and diversity of training data since the sequence model can ingest any data that can be serialized into a flat sequence. Furthermore, its performance continues to improve even at the frontier of data, compute and model scale (Kaplan et al., 2020; Ho˙mann et al., 2022). Historically, generic models that are better at leveraging computation have also tended to overtake more specialized domain-specific approaches (Sutton, 2019), eventually. In this paper, we describe the current iteration of a general-purpose agent which we call Gato, instantiated as a single, large, transformer sequence model. With a single set of weights, Gato can engage in dialogue, caption images, stack blocks with a real robot arm, outperform humans at playing Atari games, navigate in simulated 3D environments, follow instructions, and more. While no agent can be expected to excel in all imaginable control tasks, especially those far outside of its training distribution, we here test the hypothesis that training an agent which is generally capable on a large number of tasks is possible; and that this general agent can be adapted with little extra data to succeed at an even larger number of tasks. We hypothesize that such an agent can be obtained through scaling data, compute and model parameters, continually broadening the training distribution while maintaining performance, towards covering any task, behavior and embodiment of interest. In this setting, natural lan-guage can act as a common grounding across otherwise incompatible embodiments, unlocking combinatorial generalization to new behaviors. | 在所有任务中使用单一神经序列模型有着显著的好处。它减少了为每个领域手工制作具有适当归纳偏见的策略模型的需要。它增加了训练数据的数量和多样性,因为序列模型可以摄取任何可以串行化为一系列令牌的数据。此外,即使在数据、计算和模型规模的前沿,其性能也会持续提高。在历史上,更擅长利用计算的通用模型也倾向于超越更专业化的领域特定方法,最终。 在本文中,我们描述了一个我们称之为Gato的通用代理的当前版本,它作为单一的大型Transformer序列模型实例化。通过一组权重,Gato可以参与对话、图像加注释、用真实的机器人臂堆叠方块、在Atari游戏中超越人类、在模拟的3D环境中导航、遵循指令等等。 虽然不能期望任何代理在所有可想象的控制任务中都表现出色,尤其是那些远离其训练分布的任务,但我们在这里测试的假设是,训练一个在许多任务上普遍具备能力的代理是可能的;并且这个通用代理可以通过很少的额外数据适应并成功地执行更多的任务。我们假设通过扩大数据、计算和模型参数的规模,不断扩大训练分布同时保持性能,可以获得这样的代理,以涵盖任何感兴趣的任务、行为和具象。在这种情况下,自然语言可以作为跨不同具象的共同基础,解锁对新行为的组合泛化。 |
| We focus our training at the operating point of model scale that allows real-time control of real-world robots, currently around 1.2B parameters in the case of Gato. As hardware and model architectures improve, this operating point will naturally increase the feasible model size, pushing generalist models higher up the scaling law curve. For simplicity Gato was trained o˜ine in a purely supervised manner; however, in principle, there is no reason it could not also be trained with either o˜ine or online reinforcement learning (RL). | 我们将培训重点放在允许实时控制现实世界机器人的模型规模的操作点,目前在Gato的情况下约为12亿参数。随着硬件和模型架构的改进,这个操作点将自然地增加可行的模型大小,推动通用模型沿着扩展法则曲线上升。为了简单起见,Gato是以纯粹监督的方式离线训练的;然而,原则上,也没有理由它不能使用离线或在线强化学习进行训练。 |
2 Model模型
| The guiding design principle of Gato is to train on the widest variety of relevant data possible, including diverse modalities such as images, text, proprioception, joint torques, button presses, and other discrete and continuous observations and actions. To enable processing this multi-modal data, we serialize all data into a flat sequence of tokens. In this representation, Gato can be trained and sampled from akin to a standard large-scale language model. During deployment, sampled tokens are assembled into dialogue responses, captions, button presses, or other actions based on the context. In the following subsections, we describe Gato’s tokenization, network architecture, loss function, and deployment. | Gato的指导设计原则是在可能的最广泛的相关数据上进行训练,包括图像、文本、自感知、关节扭矩、按钮按压以及其他离散和连续的观察和动作。为了处理这种多模态数据,我们将所有数据序列化为一系列令牌。在这种表示中,类似于标准的大规模语言模型,Gato可以进行训练和采样。在部署过程中,基于上下文,采样的令牌被组装成对话响应、图像标题、按钮按压或其他动作。在以下各小节中,我们描述了Gato的令牌化、网络架构、损失函数和部署。 |
2.1 Tokenization令牌化
| There are infinite possible ways to transform data into tokens, including directly using the raw underlying byte stream. Below we report the tokenization scheme we found to produce the best results for Gato at the current scale using contemporary hardware and model architectures. | 将数据转换为令牌有无限可能的方式,包括直接使用原始底层字节流。以下是我们发现在当前规模、硬件和模型架构下为Gato产生最佳结果的令牌化方案。 |
| Text is encoded via SentencePiece (Kudo & Richardson, 2018) with 32000 subwords into the integer range [0, 32000). • Images are first transformed into sequences of non-overlapping 16 × 16 patches in raster order, as done in ViT (Dosovitskiy et al., 2020). Each pixel in the image patches is then normalized between [−1, 1] and divided by the square-root of the patch size (i.e. p16 = 4). • Discrete values, e.g. Atari button presses, are flattened into sequences of integers in row-major order. The tokenized result is a sequence of integers within the range of [0, 1024). • Continuous values, e.g. proprioceptive inputs or joint torques, are first flattened into sequences of floating point values in row-major order. The values are mu-law encoded to the range [−1, 1] if not already there (see Figure 14 for details), then discretized to 1024 uniform bins. The discrete integers are then shifted to the range of [32000, 33024). | 通过SentencePiece(Kudo&Richardson,2018)对文本进行编码,使用32000个子词,转换为整数范围[0, 32000)。 >> 图像首先按照ViT(Dosovitskiy等,2020)中的方式转换为非重叠的16×16块序列。然后,图像块中的每个像素在[-1, 1]之间标准化,并除以块大小的平方根(即p16 = 4)。 >> 离散值(例如Atari按钮按压)被压平为按行主序的整数序列。令牌化结果是范围在[0, 1024)内的整数序列。 >> 连续值(例如自感输入或关节扭矩)首先被压平为按行主序的浮点值序列。如果尚未在范围[-1, 1]内,则对这些值进行mu-law编码(有关详细信息,请参见图14),然后离散化为1024个均匀的箱。然后,将离散整数移至范围[32000, 33024)。 |
| After converting data into tokens, we use the following canonical sequence ordering. • Text tokens in the same order as the raw input text. • Image patch tokens in raster order. • Tensors in row-major order. • Nested structures in lexicographical order by key. • Agent timesteps as observation tokens followed by a separator, then action tokens. • Agent episodes as timesteps in time order. Further details on tokenizing agent data are presented in the supplementary material (Section B). | 将数据转换为令牌后,我们使用以下规范的序列排序。 >> 文本令牌按照原始输入文本的顺序。 >> 图像块令牌按照光栅顺序。 >> 张量按行主序。 >> 按键的嵌套结构按键的字典序。 >> 代理时间步作为观察令牌,后跟分隔符,然后是动作令牌。 >> 代理剧集按时间顺序的时间步骤。 有关对代理数据进行令牌化的详细信息,请参阅补充材料(第B节)。 |
2.2 Embedding input tokens and setting output targets嵌入输入令牌并设置输出目标
| After tokenization and sequencing, we apply a parameterized embedding function f(·; e) to each token (i.e. it is applied to both observations and actions) to produce the final model input. To enable eÿcient learning from our multi-modal input sequence s1:L the embedding function performs di˙erent operations depending on the modality the token stems from: | 在令牌化和序列化之后,我们对每个令牌应用参数化的嵌入函数f(·; _x0012_e)(即应用于观察和动作)以产生最终的模型输入。为了从我们的多模态输入序列s1:L中高效学习,嵌入函数根据令牌的模态执行不同的操作。 |
部分文章已丢失……
9 Conclusions
| Transformer sequence models are e˙ective as multi-task multi-embodiment policies, including for real-world text, vision and robotics tasks. They show promise as well in few-shot out-of-distribution task learning. In the future, such models could be used as a default starting point via prompting or fine-tuning to learn new behaviors, rather than training from scratch. Given scaling law trends, the performance across all tasks including dialogue will increase with scale in parameters, data and compute. Better hardware and network architectures will allow training bigger models while maintaining real-time robot control capability. By scaling up and iterating on this same basic approach, we can build a useful general-purpose agent. | Transformer序列模型在多任务多具象策略方面是有效的,包括用于现实世界的文本、视觉和机器人任务。它们在少样本超出分布任务学习方面也显示出潜力。在未来,这些模型可以通过提示或微调作为学习新行为的默认起点,而不是从头开始训练。 考虑到扩展法则趋势,所有任务包括对话在内的性能将随着参数、数据和计算的规模增加而提高。更好的硬件和网络架构将允许训练更大的模型,同时保持实时机器人控制能力。通过扩展并迭代这种相同的基本方法,我们可以构建一个有用的通用代理。 |
References
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Ried- miller. Maximum a posteriori policy optimisation. Preprint arXiv:1806.06920, 2018.
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. Preprint arXiv:2005.00928, 2020.
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, et al. Do as i can, not as i say: Grounding language in robotic affordances.Preprint arXiv:2204.01691, 2022.
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. Preprint arXiv:2204.14198, 2022.
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul F. Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety. Preprint arXiv:1606.06565, 2016.
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. In International Conference on Computer Vision, pp. 2425–2433, 2015.
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. Preprint arXiv:1607.06450, 2016.
Paul Bach-y Rita and Stephen W Kercel. Sensory substitution and the human-machine interface. Trends in cognitive sciences, 7(12):541–546, 2003.
Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos. Preprint arXiv::2206.11795, 2022.
Gabriel Barth-Maron, Matthew W Hoffman, David Budden, Will Dabney, Dan Horgan, Dhruva Tb, Alistair Muldal, Nicolas Heess, and Timothy Lillicrap. Distributed distributional deterministic policy gradients. Preprint arXiv:1804.08617, 2018.
Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich Küttler, Andrew Lefrancq, Simon Green, Víctor Valdés, Amir Sadik, et al. DeepMind lab. Preprint arXiv:1612.03801, 2016.
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. Preprint arXiv:2108.07258, 2021.
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. Preprint arXiv:2112.04426, 2021.
Nick Bostrom. Superintelligence. Dunod, 2017.
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. Preprint arXiv:1606.01540, 2016.
TB Brown, B Mann, N Ryder, M Subbiah, J Kaplan, P Dhariwal, A Neelakantan, P Shyam, G Sastry, A Askell, et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, pp. 1877–1901, 2020.
Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Zolna, Yusuf Aytar, David Budden, Mel Vecerik, et al. Scaling data-driven robotics with reward sketching and batch reinforcement learning. Preprint arXiv:1909.12200, 2019.
Annie S Chen, Suraj Nair, and Chelsea Finn. Learning generalizable robotic reward functions from “in-the- wild" human videos. Preprint arXiv:2103.16817, 2021a.
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Ar- avind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in Neural Information Processing Systems, 34, 2021b.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. Preprint arXiv:2107.03374, 2021c.
Tao Chen, Adithyavairavan Murali, and Abhinav Gupta. Hardware conditioned policies for multi-robot transfer learning. Advances in Neural Information Processing Systems, 31, 2018.
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection. In ICLR, 2022.
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. Preprint arXiv:1504.00325, 2015.
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. BabyAI: A platform to study the sample efficiency of grounded language learning. Preprint arXiv:1810.08272, 2018.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways. Preprint arXiv:2204.02311, 2022.
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. In International Conference on Machine Learning, pp. 2048–2056, 2020.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In Annual Meeting of the Association for Computational Linguistics, pp. 2978–2988, 2019.
Coline Devin, Abhishek Gupta, Trevor Darrell, Pieter Abbeel, and Sergey Levine. Learning modular neural network policies for multi-task and multi-robot transfer. In IEEE International Conference on Robotics
& Automation, pp. 2169–2176, 2017.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec- tional transformers for language understanding. Preprint arXiv:1810.04805, 2018.
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Un- terthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. Preprint arXiv:2010.11929, 2020.
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-RL with importance weighted actor-learner architectures. In International Conference on Machine Learning, pp. 1407–1416, 2018.
22
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data- driven reinforcement learning. Preprint arXiv:2004.07219, 2020.
Hiroki Furuta, Yutaka Matsuo, and Shixiang Shane Gu. Generalized decision transformer for offline hindsight information matching. Preprint arXiv:2111.10364, 2021.
Caglar Gulcehre, Ziyu Wang, Alexander Novikov, Thomas Paine, Sergio Gómez, Konrad Zolna, Rishabh Agarwal, Josh S Merel, Daniel J Mankowitz, Cosmin Paduraru, et al. RL unplugged: A suite of benchmarks for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:7248–7259, 2020.
Jeff Hawkins and Sandra Blakeslee. On intelligence. Macmillan, 2004.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In
IEEE Computer Vision and Pattern Recognition, pp. 770–778, 2016a.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In
European Conference on Computer Vision, pp. 630–645, 2016b.
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In IEEE Computer Vision and Pattern Recognition, pp. 9729–9738, 2020.
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs). Preprint arXiv:1606.08415, 2016. Matteo Hessel, Hubert Soyer, Lasse Espeholt, Wojciech Czarnecki, Simon Schmitt, and Hado van Hasselt.
Multi-task deep reinforcement learning with popart. In AAAI, 2019.
Matteo Hessel, Ivo Danihelka, Fabio Viola, Arthur Guez, Simon Schmitt, Laurent Sifre, Theophane Weber, David Silver, and Hado van Hasselt. Muesli: Combining improvements in policy optimization. Preprint arXiv:2104.06159, 2021.
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. Preprint arXiv:2203.15556, 2022.
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Weinberger. Deep networks with stochastic depth. Preprint arXiv:1603.09382, 2016.
Wenlong Huang, Igor Mordatch, and Deepak Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. In International Conference on Machine Learning, pp. 4455–4464, 2020.
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. Preprint arXiv:2201.07207, 2022.
David Yu-Tung Hui, Maxime Chevalier-Boisvert, Dzmitry Bahdanau, and Yoshua Bengio. Babyai 1.1.
Preprint arXiv:2007.12770, 2020.
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A general architecture for structured inputs & outputs.Preprint arXiv:2107.14795, 2021.
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. Advances in Neural Information Processing Systems, 34, 2021.
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, pp. 4904–4916, 2021.
23
Melvin Johnson, Orhan Firat, and Roee Aharoni. Massively multilingual neural machine translation. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3874–3884, 2019.
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873):583–589, 2021.
Lukasz Kaiser, Aidan N Gomez, Noam Shazeer, Ashish Vaswani, Niki Parmar, Llion Jones, and Jakob Uszkoreit. One model to learn them all. Preprint arXiv:1706.05137, 2017.
Anssi Kanervisto, Joonas Pussinen, and Ville Hautamäki. Benchmarking end-to-end behavioural cloning on video games. In IEEE conference on games (CoG), pp. 558–565, 2020.
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. Preprint arXiv:2001.08361, 2020.
Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. Recurrent experience replay in distributed reinforcement learning. In International Conference on Learning Representations, 2018.
Zachary Kenton, Tom Everitt, Laura Weidinger, Iason Gabriel, Vladimir Mikulik, and Geoffrey Irving. Alignment of language agents. Preprint arXiv:2103.14659, 2021.
Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. CTRL: A conditional transformer language model for controllable generation. Preprint arXiv:1909.05858, 2019.
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. Preprint arXiv:1412.6980, 2014.
Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Annual Meeting of the Association for Computational Linguistics, pp. 66–71, 2018.
Vitaly Kurin, Maximilian Igl, Tim Rocktäschel, Wendelin Boehmer, and Shimon Whiteson. My body is a cage: the role of morphology in graph-based incompatible control. Preprint arXiv:2010.01856, 2020.
Alex X Lee, Coline Manon Devin, Yuxiang Zhou, Thomas Lampe, Konstantinos Bousmalis, Jost Tobias Springenberg, Arunkumar Byravan, Abbas Abdolmaleki, Nimrod Gileadi, David Khosid, et al. Beyond pick-and-place: Tackling robotic stacking of diverse shapes. In Conference on Robot Learning, 2021.
Alex X Lee, Coline Manon Devin, Jost Tobias Springenberg, Yuxiang Zhou, Thomas Lampe, Abbas Abdol- maleki, and Konstantinos Bousmalis. How to spend your robot time: Bridging kickstarting and offline reinforcement learning for vision-based robotic manipulation. Preprint arXiv:2205.03353, 2022.
Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, Jacob Andreas, Igor Mordatch, Antonio Torralba, and Yuke Zhu. Pre-trained language models for interactive decision-making. Preprint arXiv:2202.01771, 2022a.
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode. Preprint arXiv:2203.07814, 2022b.
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. Preprint arXiv:1711.05101, 2017. Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-VQA: A visual question
answering benchmark requiring external knowledge. In IEEE Computer Vision and Pattern Recognition,
pp. 3195–3204, 2019.
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. Teaching language models to support answers with verified quotes. Preprint arXiv:2203.11147, 2022.
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. In Proceedings of the conference on fairness, accountability, and transparency, pp. 220–229, 2019.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
Vernon Mountcastle. An organizing principle for cerebral function: the unit module and the distributed system. The mindful brain, 1978.
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. Preprint arXiv:2112.09332, 2021.
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. Preprint arXiv:1609.03499, 2016.
Pedro A Ortega, Markus Kunesch, Grégoire Delétang, Tim Genewein, Jordi Grau-Moya, Joel Veness, Jonas Buchli, Jonas Degrave, Bilal Piot, Julien Perolat, et al. Shaking the foundations: delusions in sequence models for interaction and control.Preprint arXiv:2110.10819, 2021.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Preprint arXiv:2203.02155, 2022.
Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The unsurprising effec- tiveness of pre-trained vision models for control. Preprint arXiv:2203.03580, 2022.
Vineel Pratap, Anuroop Sriram, Paden Tomasello, Awni Hannun, Vitaliy Liptchinsky, Gabriel Synnaeve, and Ronan Collobert. Massively multilingual ASR: 50 languages, 1 model, 1 billion parameters. Preprint arXiv:2007.03001, 2020.
Sébastien Racanière, Théophane Weber, David Reichert, Lars Buesing, Arthur Guez, Danilo Jimenez Rezende, Adrià Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, et al. Imagination- augmented agents for deep reinforcement learning. Advances in Neural Information Processing Systems, 30, 2017.
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.Preprint arXiv:2112.11446, 2021.
Scott Reed and Nando De Freitas. Neural programmer-interpreters. In International Conference on Learning Representations, 2016.
Machel Reid, Yutaro Yamada, and Shixiang Shane Gu. Can Wikipedia help offline reinforcement learning?
Preprint arXiv:2201.12122, 2022.
Stuart Russell. Human compatible: Artificial intelligence and the problem of control. Penguin, 2019. Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray
Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks. Preprint arXiv:1606.04671, 2016.
Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations, 2022.
Jürgen Schmidhuber. One big net for everything. Preprint arXiv:1802.08864, 2018.
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020.
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hyper- nymed, image alt-text dataset for automatic image captioning. In Annual Meeting of the Association for Computational Linguistics, pp. 2556–2565, 2018.
Noam Shazeer. Glu variants improve transformer. Preprint arXiv::2002.05202, 2020.
H Francis Song, Abbas Abdolmaleki, Jost Tobias Springenberg, Aidan Clark, Hubert Soyer, Jack W Rae, Seb Noury, Arun Ahuja, Siqi Liu, Dhruva Tirumala, et al. V-mpo: On-policy maximum a posteriori policy optimization for discrete and continuous control. In ICLR, 2020.
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(56): 1929–1958, 2014.
Richard Sutton. The bitter lesson. Incomplete Ideas (blog), 13:12, 2019.
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. DeepMind control suite. Preprint arXiv:1801.00690, 2018.
Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. LaMDA: Language models for dialog applications. Preprint arXiv:2201.08239, 2022.
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In
International Conference on Intelligent Robots and Systems, pp. 5026–5033, 2012.
Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems, pp. 200–212, 2021.
Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess, and Yuval Tassa. dm_control: Software and tasks for continuous control. Software Impacts, 6:100022, 2020.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. Simvlm: Simple visual language model pretraining with weak supervision. Preprint arXiv:2108.10904, 2021.
Ziyu Wang, Alexander Novikov, Konrad Zolna, Josh S Merel, Jost Tobias Springenberg, Scott E Reed, Bobak Shahriari, Noah Siegel, Caglar Gulcehre, Nicolas Heess, et al. Critic regularized regression. Advances in Neural Information Processing Systems, 33:7768–7778, 2020.
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. Preprint arXiv:2109.01652, 2021.
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models. Preprint arXiv:2112.04359, 2021.
Yuxin Wu and Kaiming He. Group normalization. In European Conference on Computer Vision, pp. 3–19, 2018.
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning, pp. 1094–1100, 2020.
Qinqing Zheng, Amy Zhang, and Aditya Grover. Online decision transformer. Preprint arXiv:2202.05607, 2022.
Konrad Zolna, Alexander Novikov, Ksenia Konyushkova, Caglar Gulcehre, Ziyu Wang, Yusuf Aytar, Misha Denil, Nando de Freitas, and Scott Reed. Offline learning from demonstrations and unlabeled experience. Preprint arXiv:2011.13885, 2020.
Konrad Zolna, Scott Reed, Alexander Novikov, Sergio Gómez Colmenarejo, David Budden, Serkan Cabi, Misha Denil, Nando de Freitas, and Ziyu Wang. Task-relevant adversarial imitation learning. In Conference on Robot Learning, pp. 247–263, 2021.
这篇关于AGI之Agent:《A Generalist Agent一个通用型代理—Gato》翻译与解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








