本文主要是介绍华为第二批难题一:基于预训练AI模型的元件库生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我的理解:华为的这个难道应该是想通过大模型技术,识别元件手册上的图文内容,与现有建库工具结合,有潜力按标准生成各种库模型。
正好,我们正在研究,利用知识图谱技术快速生成装配模型,其中也涉及到3D零部件的自动生成。
既然“3D零部件的自动生成”,与华为的这个难题有相似之处,如果华为都需要向外部征求技术方案,那我们就可以省一点力,暂时不要在这块上想太多,:P。
难题一:基于预训练AI模型的元件库生成
技术背景
1. 元件库的Symbol、2D封装,3D结构当前都是根据数据手册手工绘制,每个元件需要花费数小时绘制,每一家电子公司都需要花费大量人力处理;每年行业有数以万计的新元件诞生,迫切需要更为快捷的元器件库生成技术。
2. 传统的元件商城、第三方库提供商开发了自动生成技术,本质上还是规则驱动的自动化技术,泛化性和准确性差,后端需要大量的人工check和修改工作,迫切需要新技术加以改善。
3. 基于多模态预训练模型,能很好识别元件手册上的图文内容,与现有建库工具结合,有潜力按标准生成各种库模型。
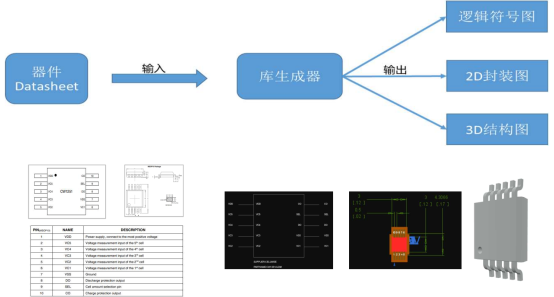
技术挑战
传统算法基于规则驱动的自动化设计技术,泛化性和准确性差,后端需要大量的人工check和修改工作。
多模态预训练模型有很好的语义理解、文本/表格/图形识别能力,可以很好解决泛化性问题,但对2D、3D物理图的高精度生成存在很大挑战。
技术诉求
技术需求:
提供基于多模态的专业电路设计预训练模型,输入元件Datasheet,输出该元件
Symbol符号库文件和封装图形库文件的生成,支持3D模型文件的生成。
技术指标:
1. 对于任意可解析、不加密、信息完整的Datasheet,Symbol符号库文件生成信息准确性大于99%;
2. 对于任意可解析、不加密、信息完整的Datasheet,封装图形库文件生成,图形精度0.01mm,识别信息描述准确性大于99%;
3. 对于任意可解析、不加密、信息完整的Datasheet, 3D模型文件生成,图形精度0.01mm。
集成需求:
集成华为云pEDA工具链EDM产品
约束条件:
使用预训练模型开发
参考文献
[1] S. Mori, Historical review of OCR research and development, 1992
[2] Tarek Ahmed Ibrahim Abdelaziz, Applications of integration of AI-based Optical Character
Recognition (OCR) and Generative AI in Document Understanding and Processing, 2023
[3] Fanghao Tian, Automatic Data Extraction Based on Semiconductor Datasheet for Design
Automation of Power Converters, 2022
联系人:吴瑾 lion.wujin@huawei.com
这篇关于华为第二批难题一:基于预训练AI模型的元件库生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







