本文主要是介绍(凯思奥)思考记录3:表设计,类插槽和高阶组件|函数,多级选项卡replace跳转,复用函数注入,代码特异性,形参的解构,后端报错设计,领域实体,数据的关联,相等|严格运算符,redis数据设计问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、思考小结
1、表设计
之前因为才两张表,用户而言业务外键是phone 而不是ID,随着业务和数据库复杂起来,发现phone并不是好的选择,最好还是id为外键,但是考虑到前期多处耦合phone修改起来有些麻烦,故之后与用户连表的外键均为id,之前则不论。(2020年3月,已通过自动化将外键调整为id)
2、关于删除资源
对于资源删除,真实的删除操作会引起资源的危险,以及占用服务器资源,还会影响关联数据的读取异常。相较这么高风险操作,那么硬盘的价格很低,所以还是选择扩充硬盘比较好。
3、类插槽和高阶组件|函数
写代码久了,容易生搬硬套,朝着业务的实现走,没有维度。
1.vue的插槽,即react组件包裹标签(<Com> <h1>我是组件内的标签</h1><Comp>)。2.高阶组件 3.高阶函数。而上述三个概念都可以用于组件的复用抽象上。
但是思索后,发现场景是不同的,得区分。
插槽:焦轻量,仅传递一段DOM而已。
高阶组件:侧重组件的DOM/UI,各种状态的管理与传递。
高阶函数:侧重逻辑过程,每一级函数干了什么事情。
4、多级选项卡&replace跳转
一般情况只有单级或者二级,而且选项也不多,那么可以直接写死onClick写push逻辑跳入hash,然后通过副作用检测hash的值,进行索引修改。
那么若三级以上,且选项很多,直接写死onClick非常麻烦,而且后期非常难维护,最好是动态生成。这就需要数组的形式进行遍历,动态添加onClick字段,传入统一方法进行hash读取并覆盖或添加。
replace和push 均为跳转,前者会覆盖历史栈,就适用选项卡的跳转。
5、复用函数注入
比如点击用户名称和点击用户头像,应该跳转的都是UserPage,那么这部分逻辑可以抽离入根组件,并注入props中。
但是问题是App组件并未包裹在Router内,故我审视了下,绝对将该部分复用函数,写入PrivateRoute中。
但是在PrivateRoute又不得不使用withRouter,问题产生了,withRouter似乎限制了路由的动态变化,也就是子组件路由参数永不变化。
因此,我卡住了。。。。
后来看到其实routeProps参数是通过回调函数传入的,那么可以设计成高阶函数的形式。
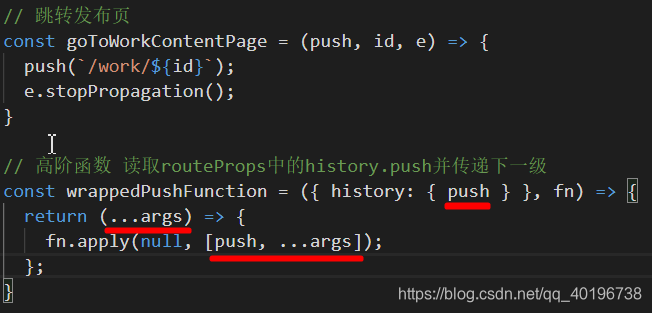
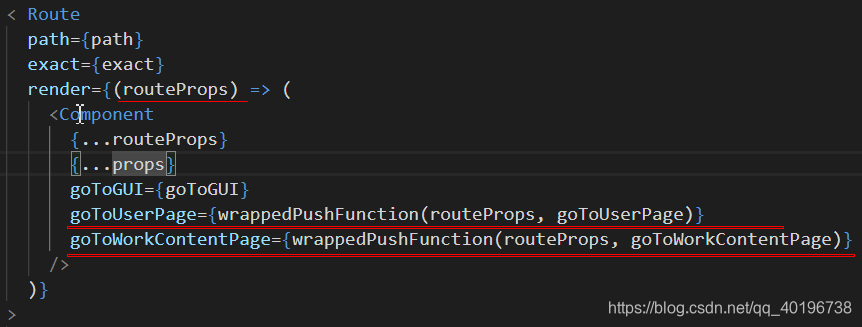
不过其实还是有点丑,但是至少是注入在根级组件的。
6、代码特异性
名称是我语义化定义的。在开发阶段肯定会出现有差异性甚至较特异的代码,但是随着开发的推进,此类代码很难进行修正,所以,我们应该考虑宽放管理它们,也就是按照代码的初衷去写逻辑,代码可以不服从管理。
emmmmmmmmm…
不过一定程度上,还是尽量减少特异性代码的出现,毕竟维护的复杂度就上去了。
7、对形参的解构
最好是大一统情况,如果针对ajax的异步返回,在没有合理的数据结构和默认参数下,最好先抓明确的参数(比如 data),然后在代码体内进行data解耦,避免产生解构报错。
8、后端报错设计
之前我没有针对异常进行代码的逻辑书写,现在发现有这个必要了,目前规则应如下。
后端接口逻辑 resolve和reject ,promise任务链出现问题均以reject或者 return Promise.reject() 去返回。通过 SuccessModel(errno = 0) 或ErrolModel(errno = -1)返回。
前端判断则通过 errno的值。
因为,我觉得非复杂业务,没有必要对错误的捕获做太细致的设计。只要能知道接口返回状态是否正确即可。
9、领域实体
redux为状态管理,其中一种专用于缓存已访问的产品数据,称之为领域实体,
entity,而entity和普通的state需区分。entity通常缓存字典类型的数据集合,比如用户1,用户2,产品1,产n…
10、数据的关联
比如用户10001 用户中心页,有 作品,收藏,关注
而某一作品 work/46,作品被该10001收藏了吗?
第一反应就是在作品返回的时候,去查用户&作品关联表,将映射返回。
其实不用,后端仅返回作品数据即可,而关系数据,通过用户自身的数据,进行一个代理,或者说映射。(前端拿到UserPageInfo,Info内有collect,collect 内包含作品id)我们通过此id,与当前路由paramId匹配即可。
11、相等|严格运算符
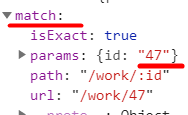
比如 react中的 props.match.params 匹配出来的id是字符串,所以要小心,将其Number再进行严格运算符===
12、redis数据设计问题
在使消息未读条目持久化时,我并非考虑到分类去管理未读条目。而去全部丢入userId: count。
开发MsgPage后,突然发现,其实必须做到条目的分类,对于用户体验才能进行提升。
但是目前来看,如果重新设计unreadCount有些吃力,影响较小,故,容忍。
这篇关于(凯思奥)思考记录3:表设计,类插槽和高阶组件|函数,多级选项卡replace跳转,复用函数注入,代码特异性,形参的解构,后端报错设计,领域实体,数据的关联,相等|严格运算符,redis数据设计问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





