本文主要是介绍针对LLM大模型承载网发布星智AI网络解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
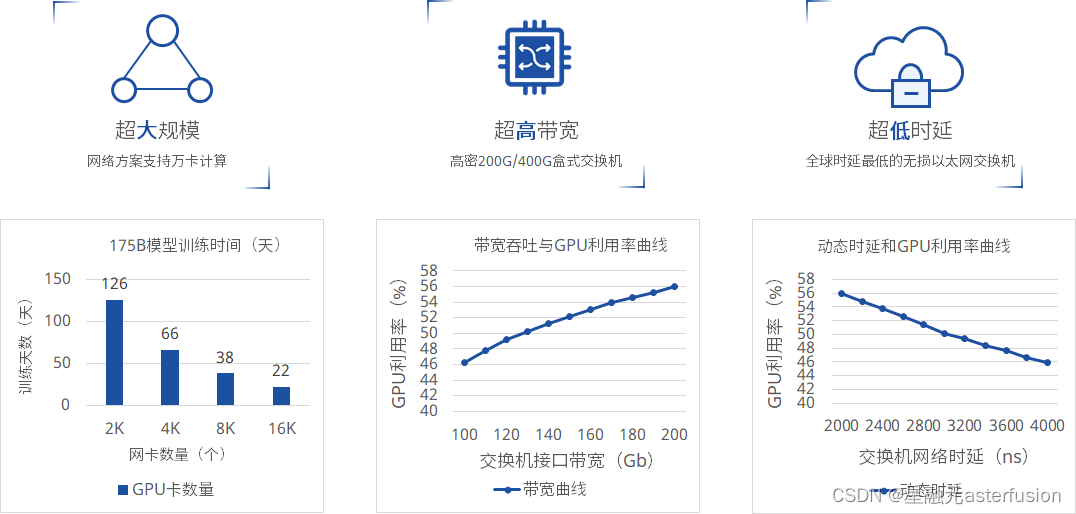
人工智能是数字经济的核心驱动力,AI 大模型是人工智能的新引擎。近年来,随着 ChatGPT 等生成式人工智能(AIGC)的突飞猛进,业内领军企业竞相推出万亿、10 万亿参数量级别的大模型,还对底层 GPU 支撑规模提出了更高的要求,达到了万卡级别。然而,如何满足如此庞大规模的训练任务,对网络的规模、性能、可靠性和稳定性等方面提出了前所未有的挑战。
一、AI大模型型对智算中心网络的需求
-
AI 应用计算量呈几何级数增长,算法模型向巨量化发展,当前 AI 超大模型的参数目前已经达到了千亿~万亿的级别。训练这样的模型,毫无疑问需要超高算力。AI 超大模型训练使用GPU训练,互联网络需求在100Gbps~400Gbps,使用RDMA协议来减少传输时延可提升网络吞吐。
- 在 AI 大模型训练场景下,机内与机外的集合通信操作将产生大量的通信数据量。流水线并行、数据并行及张量并行模式需要不同的通信操作,这对于网络的单端口带宽、节点间的可用链路数量及网络总带宽提出了高要求。
- 网络抖动会导致集合通信的效率变低,从而影响到 AI 大模型的训练效率。因此在AI 大模型训练任务周期中,维持网络的稳定高效是极其重要的目标,这对网络运维带来了新的挑战。
- 在数据通信传输过程中产生的网络时延由静态时延和动态时延两个部分构成,其中真正对网络性能影响比较大的是动态时延。动态时延包含了交换机内部排队时延和丢包重传时延,通常由网络拥塞和丢包引起。
- 由于 AI 大模型训练中集群规模大,这进一步增大了配置的复杂度。在庞大的架构和配置条件下,业务人员能够简化配置部署,有效保障整体业务效率。
AI 大模型对网络的需求主要体现在规模、带宽、时延以及稳定性等几个方面。从当前数据中心网络的实际能力来看,完全匹配AI 大模型的需求在技术上仍然有一定的差距。
二、传统承载网络在AI算力网络的不足
随着大模型训练对于算力需求的不断提升,智算GPU从千卡到万卡,面对万卡以上的建设需求,传统网络解决方案为三级CLOS架构,通常让一台服务器配8块GPU卡,对应的8张万卡连接到单个HB域中的8台Server Leaf上,实现同一卡号GPU在一个Server Leaf上通信。同时为了确保高速转发,每个层级要保证1:1无收敛,以128端口盒式设备为例,Server Leaf和Spine设备的端口分配为上下各64个端口,Super Spine设备的128个端口全部用于下行接入,基于这样的端口规划,整体网络规模有8个HB域,64个POD和64个Fabric,网卡接入规模为32768。
可以直观的看到,整体网络架构极为复杂,不但网络建设成本高,网络转发路径跳数多,并且后续的运维和故障排障极其困难。
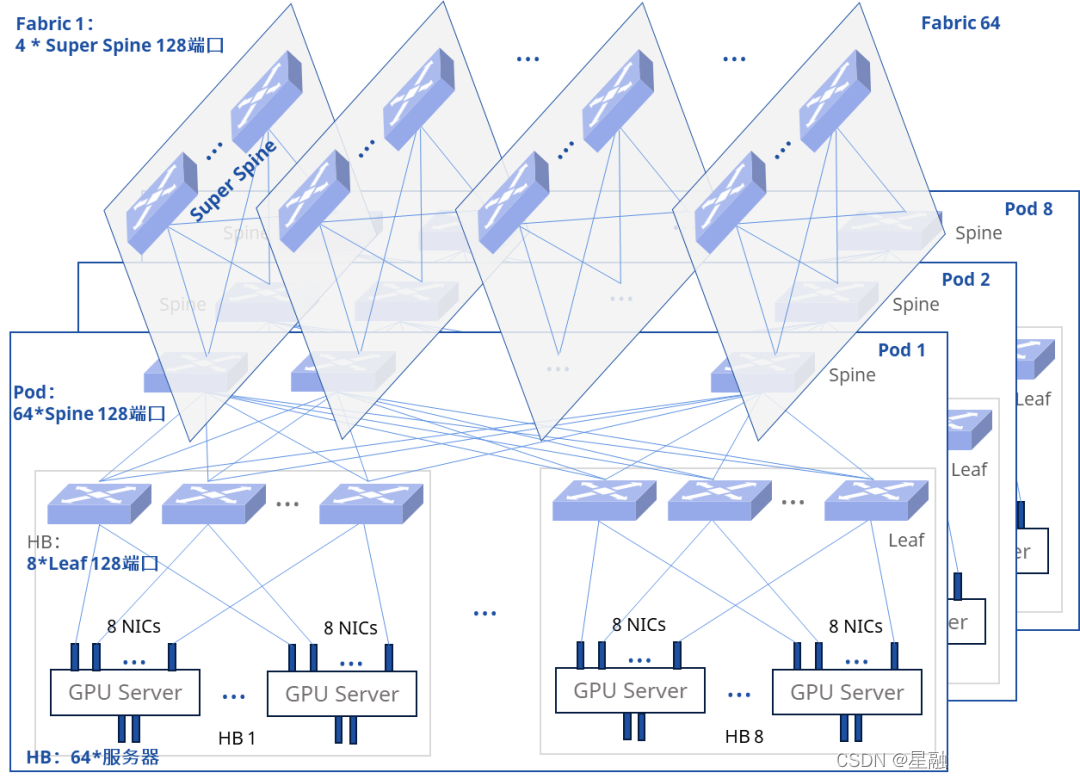
全Full Mesh网络成本高
- 跨 Leaf 交换机,转发路径有 3 跳,跨POD流量跳数更多,极大的增加了业务时延
- 网络结构复杂,运维以及故障排查困难
以32768个GPU,128端口交换机组网为例:
CLOS层数:3层
交换机需要:1280台=((64+64)*8)+256
光发射器数量:196608
| 两层胖数架构 | 三层胖数架构 | |
|---|---|---|
| 同GPU卡号转发条数 | 1跳 | 3跳 |
| 不同GPU卡号转发条数(无优化情况) | 3跳 | 5跳 |
为了缩小技术上的差距,星融元推出星智AI网络解决方案,针对LLM大模型场景构建了一张大规模、低时延、大带宽、高稳定、自动化部署的AI承载网。
三、Asterfusion星智AI网络解决方案
1、方案介绍
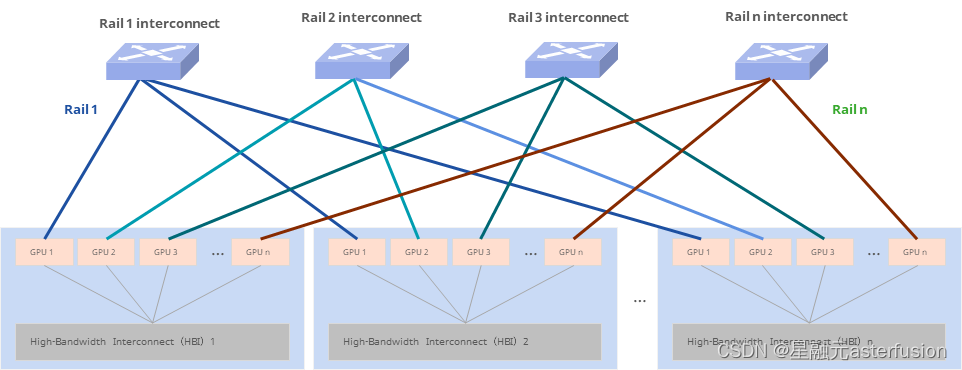
与传统方案相比,星智AI网络消除了跨GPU服务器不同GPU卡号之间的连接,只保留了与GPU相连的Leaf层交换机,将原本用于上连Spine的端口全部用于下连GPU,进一步提高Leaf交换机连接效率,并且这种网络架构仍然可以通过转发实现不同HB域之间的通信。
不同智算节点服务器间相同编号的网口需要连接到同一台交换机。如智算服务器 1 的 1 号 RDMA 网口,智算服务器 2 的 1 号 RDMA 网口直到智算服务器 N 的 1 号 RDMA 网口都连到 1 号交换机。

在智算服务器内部,上层通信库基于机内网络拓扑进行网络匹配,让相同编号的 GPU 卡和相同编号的网口关联。这样相同GPU 编号的两台智算节点间仅一跳就可互通。
不同GPU编号的智算节点间,借助NCCL通信库中的Rail Local技术,可以充分利用主机内GPU间的NVSwitch的带宽,将多机间的跨卡号互通转换为跨机间的同GPU卡号的互通。
星智AI网络解决方案轻松组建智算中心万卡网络,满足用户智算中心网络建设需求的同时,也避免了传统网络在智算中心的不足。
- 不影响性能的情况下,网络架构精简极大的降低用户网络建设成本
- 网络只需1跳,减少业务时延
- 网络结构简化,降低运维以及故障排查难度
以32768个GPU,128端口交换机组网为例:
CLOS层数:1层(Rail Only)
交换机需要:256台
光发射器数量:65536
网络成本最大可降低:75%
2、方案优势
性能提升①:提升单机网络带宽
(1)增加网卡的数量,初期业务量少,可以考虑CPU和GPU共用,后期给CPU准备单独的1到2张网卡,给GPU准备4或8张网卡;

(2)提升单机网卡带宽,同时需要匹配主机PCIe带宽和网络交换机的带宽;
| 网卡速率 | 40G | 100G | 200G | 400G |
|---|---|---|---|---|
| PCIe | 3.0*8 | 3.0*16 | 4.0*16 | 4.0或5.0*16 |
| 交换机Serdes | 4*10G | 4*25G | 4*50G | 8*50G |
性能提升②:应用RDMA网络(RoCE)
(1)借助RDMA技术,减少了GPU通信过程中的数据复制次数,优化通信路径,降低通信时延;
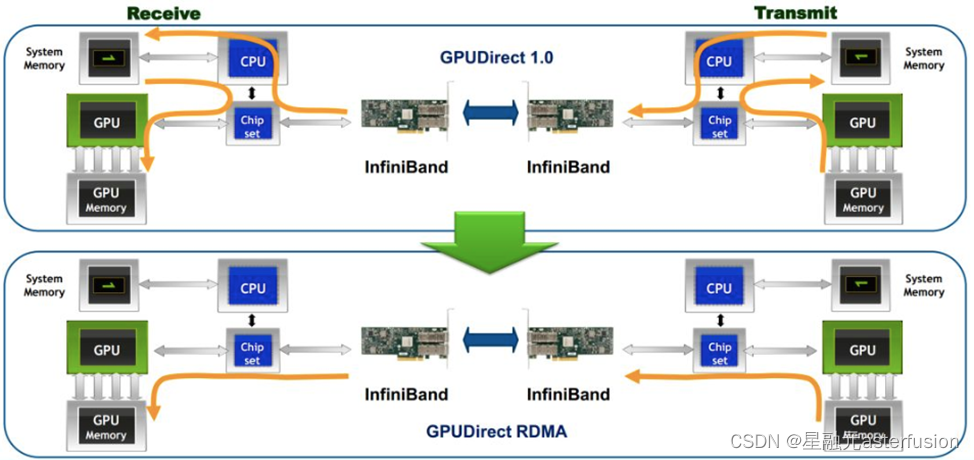
(2)通过Easy RoCE技术,一键下发过去比较复杂的RoCE相关配置(PFC、ECN等),有效帮助用户降低运维复杂度;
性能提升③:减少网络拥塞
(1)减少网络测时延提高GPU使用效率:超低时延~400ns;
(2)通过DCB协议组减少网络拥塞:PFC、PFC WatchDog、ECN构建全以太网零丢包低时延网络;
随着 ChatGPT、Copilot、文心一言等大模型应用的横空出世,AI 大模型下的智算中心网络也将带来全新的升级。星融元持续投入研发,星智AI网络解决方案在一次次客户实地检测中得到认可。我们将与AI厂商通力合作,逐步推动AI 大模型下的智算中心网络关键技术的成熟与落地,针对用户场景,我们不断追求更加美好的解决方案,期盼与众多合作伙伴共同打造大规模、高带宽、高性能、低时延以及智能化的 AI 大模型智算中心网络。
背景内容参考中国移动研究院《面向AI 大模型的智算中心网络演进白皮书(2023 年)》
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态。
这篇关于针对LLM大模型承载网发布星智AI网络解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







