本文主要是介绍阿里集团基于 Fluid+JindoCache 加速大模型训练的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者:王涛(扬礼) 陈裘凯(求索) 徐之浩(东伝)
一、背景
时间步入了 2024 年,新的技术趋势,如大模型/AIGC/多模态等技术,已经开始与实际业务相结合,并开始生产落地。这些新的技术趋势不仅提高了算力的需求,也给底层基础设施带来了更大的挑战。
在计算方面,以 GPU 和 FPGA 等异构硬件为例,他们通过短周期的迭代和演进来适应不断变化的需求。阿里集团通过统一调度、统一资源池以及全面弹性等调度手段满足了复杂的计算需求。
在存储方面,经典的微服务应用通过云原生化的方式,兼顾了性能和效率。但对于计算量增量最大的分布式 AI 训练、大数据等计算密集型应用,data locality 直接影响了计算作业的运行效率与吞吐,网络 I/O 的消耗还间接拉高了带宽成本,且在可预见的场景中,数据集规模的还会以较高的速率保持增长,如何通过合理的数据缓存亲和性技术加速数据访问,将是提升计算任务运行效率的同时降成本的关键。
大模型训练/多媒体等场景的数据集以图片和音频文件为主,天然适合将数据托管在 OSS 对象存储上,也是目前线上大多数计算作业的存储选型,以训练场景为例,具有以下读数据的特征:1)数据集顺序的随机化处理造成传统的单机缓存策略失效;2) 多个 epoch 会对数据集进行多轮读取;3) 作业间可能复用同个数据集。
综上,阿里巴巴集团内部多个 AI 平台业务面临的现状中,天然适合用分布式缓存/文件系统的形式进行 I/O 层面的加速。
二、面临的挑战
-
计算存储分离架构提升了数据访问与计算水平扩展的灵活度,但导致了数据访问高延时,对于训练等对数据缓存亲和性有显著诉求的场景延迟不友好:业务团队使用的机器学习任务在训练过程中要实时频繁访问 OSS 上的数据(以样本数据集与 checkpoint 为主),在 OSS 带宽受限或者压力较大时,访问 OSS 上数据速度比访问本地文件速度要慢 1~2 个数量级,且占据了用户大量的带宽成本;
-
Kubernetes 调度器数据缓存无感知,同一数据源多次运行访问依旧慢: 在现实应用中深度学习任务运行会不断重复访问同一数据,包括相同模型不同超参的任务、微调模型相同输入的任务、以及 AutoML 任务等。这种深度学习任务的重复数据访问就产生了可以复用的数据缓存。然而,由于原生 Kubernetes 调度器无法感知缓存,导致应用调度的结果不佳,缓存无法重用,性能难以提升;
-
OSS 成为数据并发访问的瓶颈点,稳定性挑战大: 大量机器学习任务在同时训练时都会并发访问后端 OSS 存储。这种并发机器学习训练造成的 IO 压力比较大,OSS 服务成为了性能单点,一旦 OSS 带宽出现瓶颈则会影响所有机器学习任务;
-
训练文件分散,元数据压力: 机器学习任务的训练数据文件通常会分散在不同路径下,读取文件需要耗费大量的时间在 list 操作上。对象存储的 list 操作性能较差,在进行大规模 list 时对 OSS 元数据压力很大,经常出现超时或者 list 失败的情况;
-
IO 稳定性对业务运行有直接影响:导致业务表现不稳定,甚至造成任务失败。基于 FUSE 的存储客户端更容易发生这样的问题,一旦这些问题无法自动修复,则可能中断集群训练任务。时刻保持 IO 的稳定性是保证业务顺利运行的关键途径之一。
在现实应用中,通过对于以上典型数据访问 pattern 的分析,我们发现 IO 性能问题会导致 GPU 等昂贵计算资源不能被充分利用。机器学习自身训练的特点导致了数据文件访问较分散,元数据压力较大。如果能够精细化地缓存元数据和文件数据,那么一方面可以提高缓存效率和磁盘利用率,另一方面也可以解决文件查找操作带来的元数据损耗。
三、面向深度学习任务的高效缓存调度加速系统
3.1 架构组件介绍
Fluid
Fluid 是一个开源可扩展的分布式数据编排和加速系统,以 Kubernetes 标准和对用户透明的方式为 AI 和大数据等数据密集型应用提供数据访问能力,其目标为构建云原生环境下数据密集型应用的高效支撑平台。
Fluid 通过 Kubernetes 服务提供的数据层抽象,可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源和 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。而具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题。用户只需以最自然的 Kubernetes 原生数据卷方式(PV/PVC)直接访问抽象出来的数据,剩余任务和底层细节全部交给 Fluid 处理。
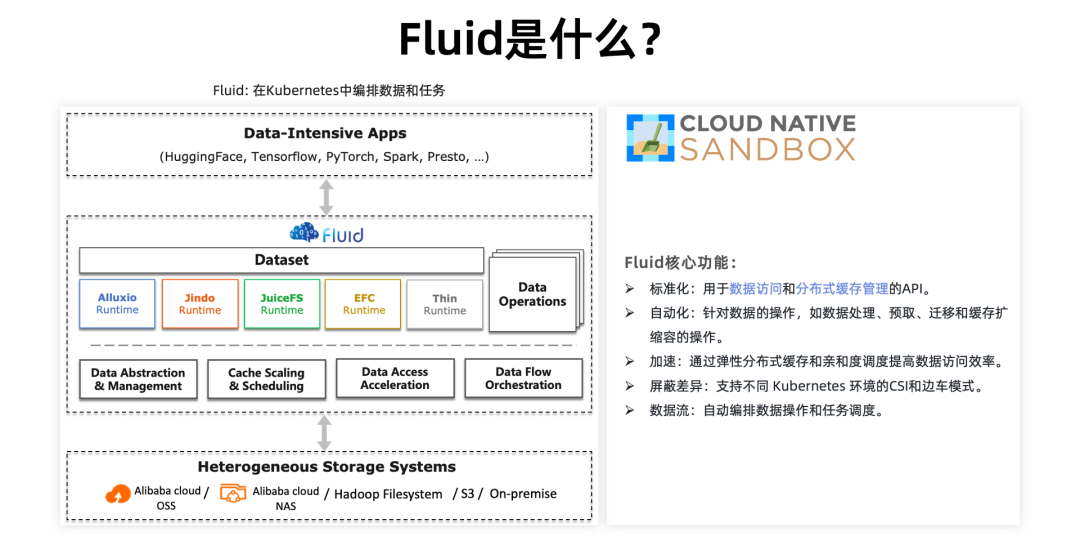
Fluid 支持多种 Runtime,包括 Jindo,Alluxio,JuiceFS 和 GooseFS;其中能力、性能和稳定性比较突出的是 JindoRuntime,有比较多的真实落地场景。JindoRuntime 是 Fluid 一种分布式缓存 Runtime 的实现,基于 JindoCache 分布式缓存加速引擎。
JindoCache
JindoCache(前身为 JindoFSx)是阿里云数据湖管理提供的云原生数据湖加速产品,支持数据缓存、元数据缓存等加速功能。JindoCache 能够为不同文件路径使用不同的 CacheSet 从而提供不同的读写策略,满足数据湖的不同使用场景对访问加速的需求。
JindoCache 可以用于如下场景:
-
OLAP(Presto 查询),提高查询性能,减少查询时间;
-
DataServing(HBase),显著降低 P99 延迟,减少 request 费用;
-
大数据分析(Hive/Spark 报表),减少报表产出时间,优化计算集群成本;
-
湖仓一体,减少 request 费用,优化 catalog 延迟;
-
AI,加速训练等场景,减少 AI 集群使用成本,提供更全面的能力支持。
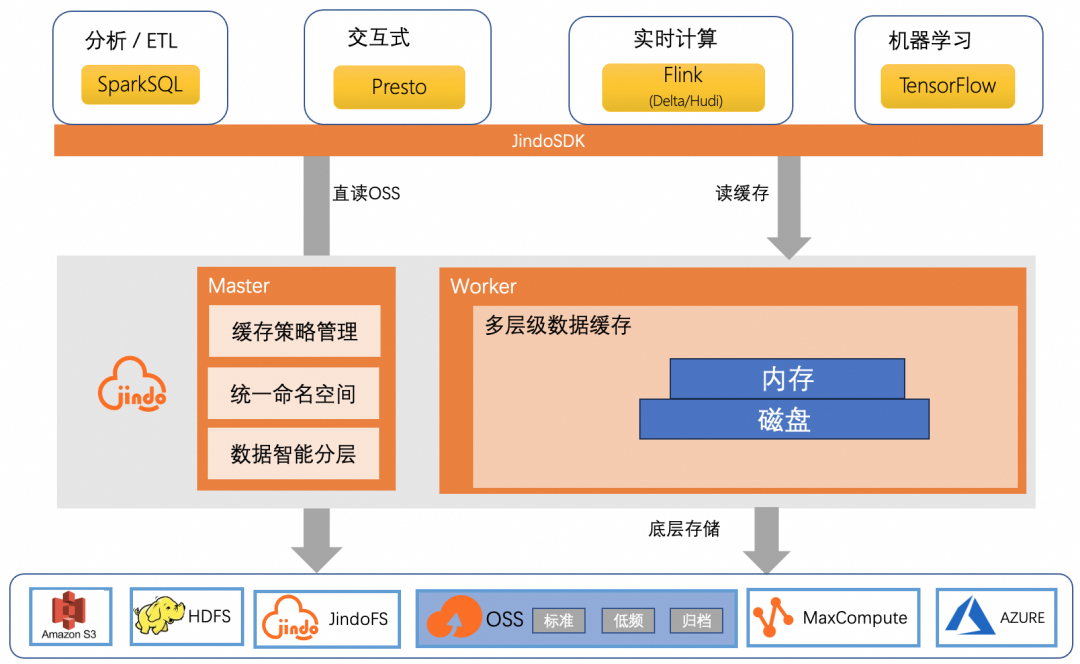
KubeDL
一套基于 K8S(ASI)的 AI 工作负载编排系统,负责管理分布式 AI 工作负载的生命周期、与一层调度的交互、容错与故障恢复、数据集、运行时加速等,高效支撑了集团统一资源池中不同平台的 AI 训练任务,包括但不限于淘系、阿里妈妈、达摩院等业务域,日均支撑 1w+训练任务的稳定运行。
项目整体架构图
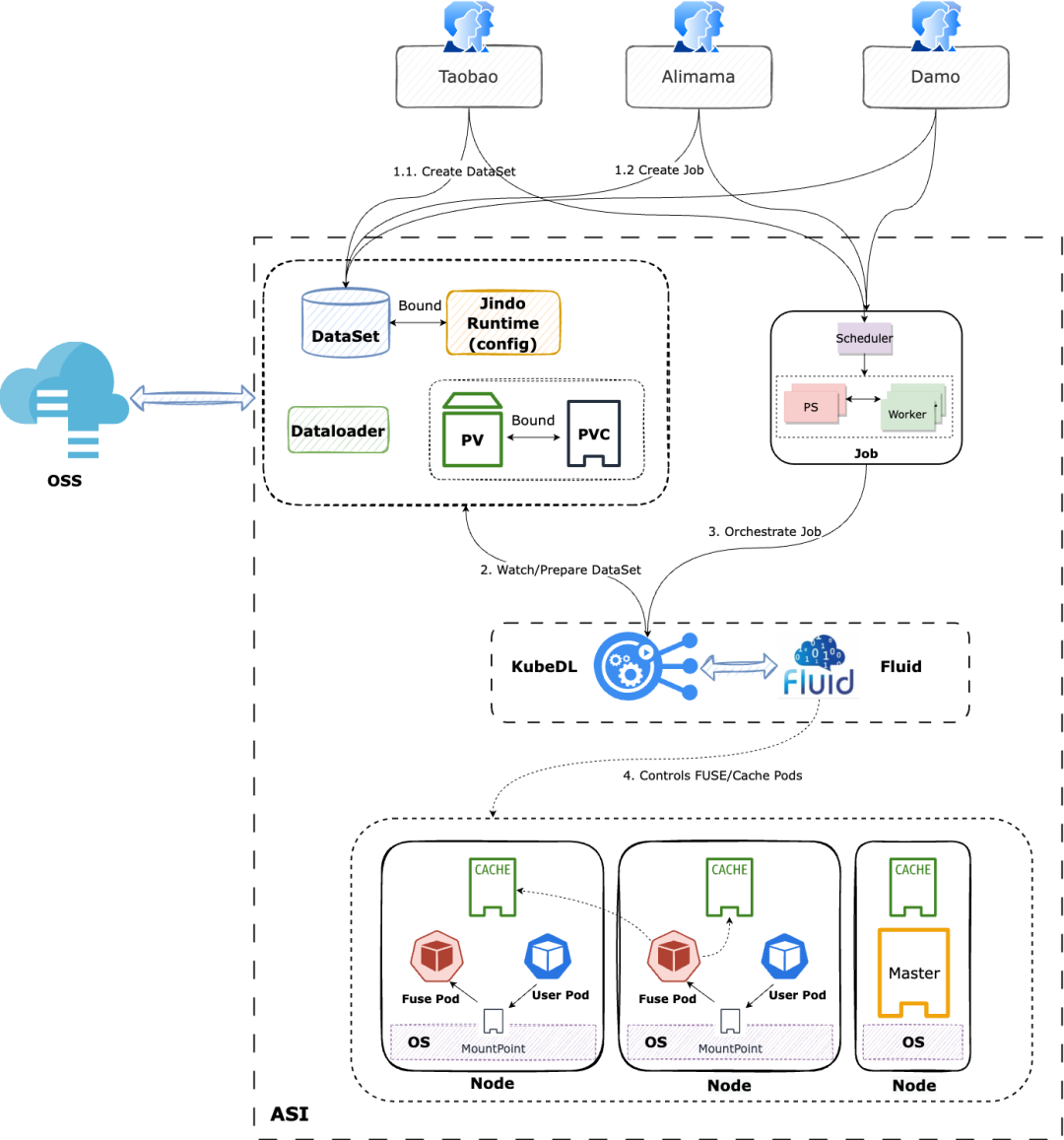
3.2 使用基于 JindoCache 的 Fluid 的原因
-
Fluid 可以将数据集编排在 Kubernetes 集群中,实现数据和计算的同置,并且提供基于 Persistent Volume Claim 接口,实现 Kubernetes 上应用的无缝对接。同时 JindoRuntime 提供对 OSS 上数据的访问和缓存加速能力,并且可以利用 FUSE 的 POSIX 文件系统接口实现可以像本地磁盘一样轻松使用 OSS 上的海量文件,pytorch 等深度学习训练工具可利用 POSIX 文件接口读取训练数据;
-
提供元数据和数据分布式缓存,可单独进行元数据缓存预热;
-
提供元数据缓存预热,避免训练文件在 OSS 上大量元数据操作、提供数据预热机制,避免在训练时刻拉取数据造成的数据访问竞争;
-
通过 KubeDL 调用 Fluid 数据亲和性调度能力,用户无需感知缓存存放的节点位置,以及弹性场景中不断随时可能迁移的节点环境,将有数据依赖的任务和已缓存的节点进行感知调度,实现尽可能的短路 short-circuit 读,最大化性能优势;
-
JindoCache 提供多种分布式缓存能力,可以根据业务需要选择合适的缓存策略。在当前场景中我们选择 Cache-Aside (Lazy Loading)的读缓存策略:当应用程序需要读取数据时,它首先检查缓存以确定数据是否可用。如果数据可用(缓存命中),则返回缓存的数据。如果数据不可用(缓存未命中),则会在底层存储查询数据,然后用从底层读取的数据填充缓存,并将数据返回给调用者。写缓存策略选择 Write-Through 即写时落缓存策略,应用程序向底层文件系统写入的文件,同时也会被写入缓存系统中,好处是下一次读取这部分数据的时候就可以直接从缓存系统中读取,大大提升了读取效率。
-
Fluid 支持 FUSE 挂载点自愈能力,可以自动检查并恢复因 OOM 等异常原因导致的 FUSE 挂载点断裂问题,避免数据访问异常,保障 AI 平台在线业务稳定运行。
3.3 落地实践
在集团场景的实践中,我们基于 KubeDL 的作业编排能力,结合 Fluid+JindoRuntime 的缓存引擎能力,同时充分利用了集团庞大异构计算资源池中闲置的内存/高性能磁盘等本地资源,端到端地为 AI 平台提供了数据 I/O 的加速能力。
-
集团庞大的统一异构资源池提供了差异化 SLO 的资源售卖等级,运行着高保障、Spot Instance、潮汐离线、普通离线 等多种不同等级的资源,以及搭配了多种代系的机型、SSD、高性能网卡等硬件,通过合理搭配 JindoCache 的多级缓存介质,我们能充分利用好统一资源池的闲置资源;
-
结合 JindoCache 缓存集群的组成特点,我们使用高保障的计算资源运行元数据服务,利用弹性的离线资源来运行 Cache 缓存节点服务(IO Bound 类型),在充分结合了集团资源池调度特点的同时最小化了用户成本;
-
结合 KubeDL 的分布式训练任务管理与 Fluid 数据集管理能力,我们针对不同用户的相同数据源自动进行数据集的跨作业复用,甚至不同平台的相同数据源也可以在统一资源池中自动复用,并且基于作业的引用计数,KubeDL 可以自动回收闲置的数据集以帮助用户主动节约成本;
3.4 经验分享
根据实践,我们总结了以下五个方面的经验供大家参考。
-
选择合适的缓存节点: 使用 JindoRuntime 可以获得更好的数据本地性能,在实际生产中我们发现不是所有节点都来做缓存性能就比较好。原因是有些节点的磁盘和网络 IO 性能不是很好,这个时候需要我们能够把缓存节点尽量选择到一些大容量磁盘和网络较好的节点上。Fluid 支持 dataset 的可调度性,换言之,就是缓存节点的可调度性,我们通过指定 dataset 的 nodeAffinity 来进行数据集缓存节点的调度,从而保证缓存节点可高效的提供缓存服务。
-
配置缓存容量与路径: 通过 dataset 的 Mounts 和 JindoRuntime 的 tieredstore 可以设定数据的挂载目录。同时,为避免数据量过多而导致缓存量过于庞大,可手动配置 JindoRuntime 的 tieredstore 来约束缓存的最大容量与水位线(超过水位线的数据会被自动丢弃),tieredstore 也包含对缓存存放路径的设定与存储层(SSD/MEM/HDD)的设定,以满足各种场景的需要。对于多节点的场景,使用 dataset 的 replacement 可以支持在同一集群上部署多个 dataset。
-
设定缓存安全策略: 在 Fluid 中创建 Dataset 时,有时候我们需要在 mounts 中配置一些敏感信息,如 oss 账号的 accessKeyId、accessKeySecret 。为了保证安全,Fluid 提供使用 Secret 来配置这些敏感信息的能力。通过创建 Secret,dataset 以 EncryptOptions 字段指定 Secret 的 name,实现对敏感信息的绑定。
-
数据预加载: 对于已经创建完成的 dataset 和 jindoruntime,第一次访问挂载的数据会经历一次下载数据目录下全部文件的过程,这就产生了一个问题:若数据所在的目录存在无需使用的其他数据,会造成无意义的空间资源与网络资源浪费。为避免这种问题,Fluid 既支持对数据的预加载,同时也支持元数据缓存。通过创建 dataload 读取所要预加载数据路径信息,可以动态将数据注入。dataload 支持缓存元数据与屏蔽非预加载数据的访问,这样就大大降低的数据访问效率。
-
启用 Fluid FUSE 挂载点自愈能力:在线业务运行过程中,FUSE 进程可能因为内存资源不足以及其他原因崩溃重启,造成业务容器内 FUSE 挂载点断联,出现数据访问异常并影响在线业务可用性。通过启用 Fluid FUSE 挂载点自愈能力,Fluid 自动检测并修复此类断联挂载点,持续保障在线业务稳定运行。
3.5 实践结果
读样本加速
以生产环境中的真实用户作业为基础,我们对 JindoCache 的效果进行了一次端到端的验证。
-
目标任务:LLAMA 13B 的预训练任务
-
实验环境:
-
集群 &机型:高性能网络集群 A800 服务器,搭载 RDMA 网卡与 Nvme 高速硬盘;
-
JindoCache 规格:默认值为 24*32Gi Cache Worker,以 Nvme 盘为存储介质(相对内存的性价比更高);
以下为实验结论:
LLaMa 13B 预训练模型
监控数据-无缓存直连。
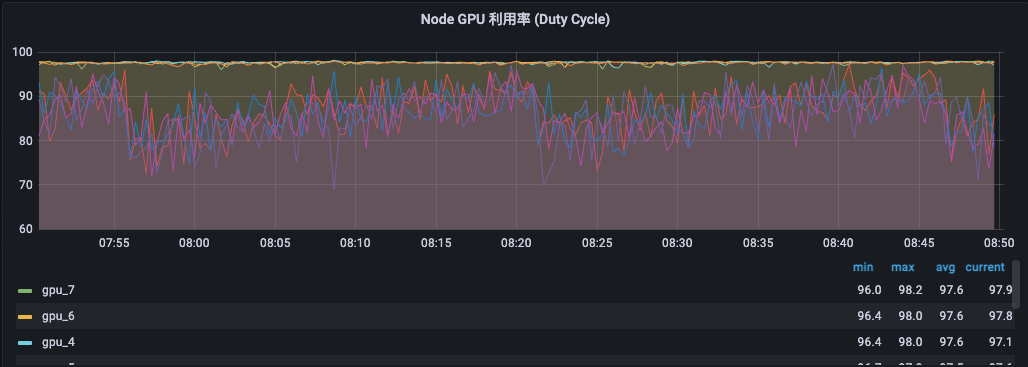
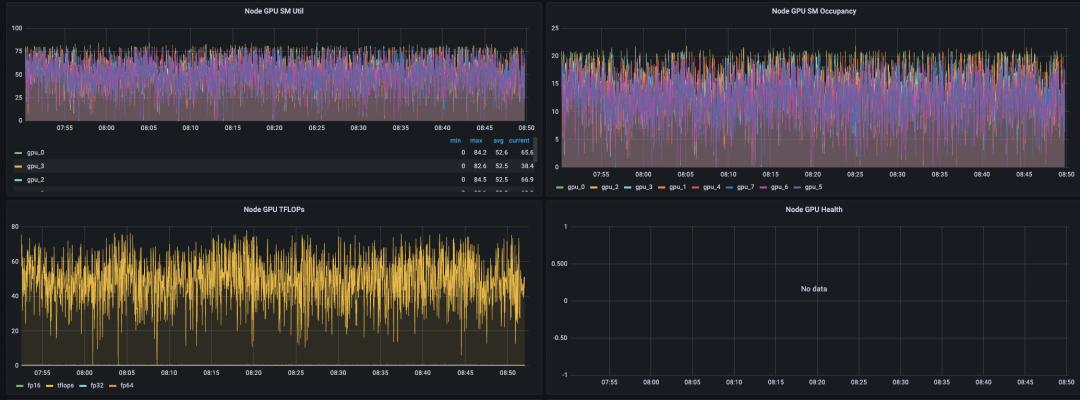

监控数据-开启缓存。
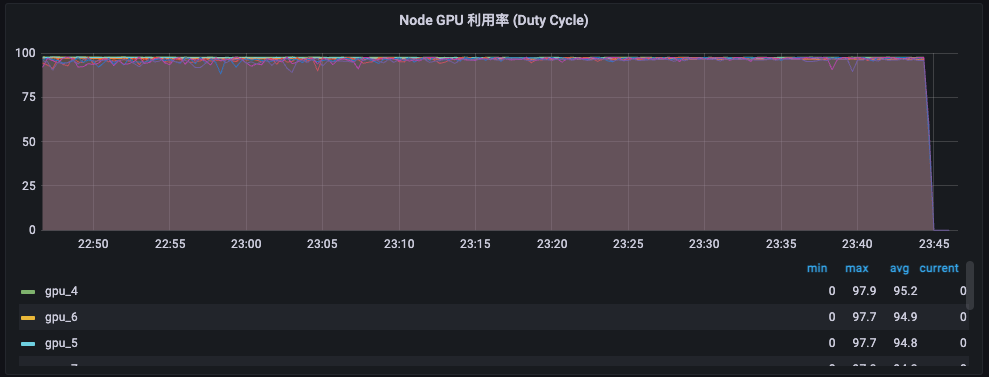
整机的平均 GPU 利用率同样接近 100%,但是各卡的负载较为均匀,都接近 100%。
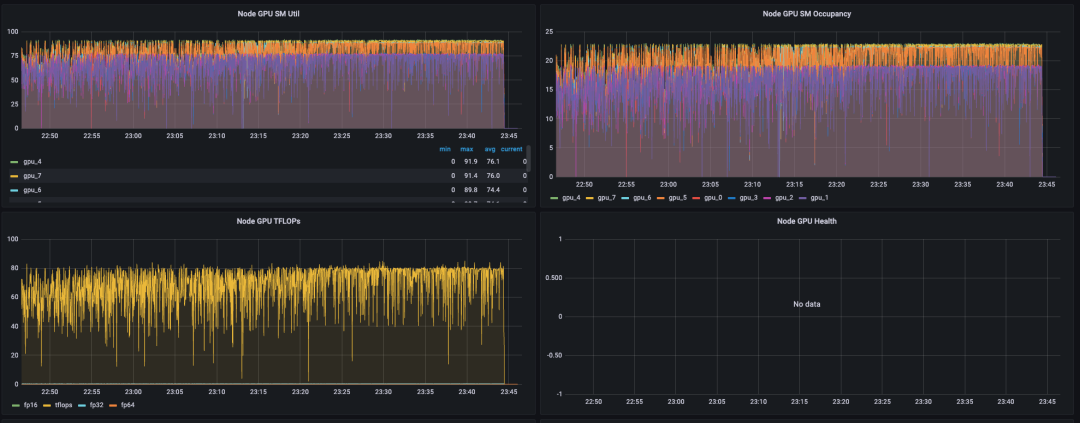
Checkpoint 加速
训练/离线推理场景
分布式训练任务在每次重启任务时都会 load checkpoint 模型文件以继续训练,模型大小从几百 MB 到几十 GB 不等;除此之外还有大量的离线推理任务,大量使用了统一资源池中的 Spot Instance 弹性 GPU 资源,每个推理任务都会随时被抢占,并在 FailOver 之后重新加载模型做离线推理,因此会有大量 Job 在“生生灭灭”中加载同一个 Checkpoint 文件。
通过 JindoCache 的分布式缓存加速,我们将“多次远端读”变成了“单次本地读”,极大加速了 Job FailOver 速度的同时还为用户节约了多次反复读的带宽成本,在典型的大模型场景中,7b 参数量搭配 fp16 精度,模型文件的体积约 20Gb,通过 JindoCache 加速我们将用户每次加载模型的耗时从 10min 缩短到了约 30s。
训练 Spot 场景(写时落缓存)
分布式训练的 Spot 场景中,同步训练任务通常会在被抢占之后 FailOver 重新全局重启并续跑,KubeDL 会与一层调度配合,以交互式抢占的方式通知到训练任务的 Rank 0 节点做一次 on-demand checkpoint 以保存最新的训练进度,并能够在重启后 reload 最新的 checkpoint 及时续跑,享受 Spot 弹性低成本的同时最小化训练中断的代价。
通过最新版本的 JindoCache 写时落缓存能力,原先重新后从远端重新被动 load 最新的模型文件,变成了重启后即时从本地缓存集群 load 最新的模型文件,端到端 FailOver 的中止时间从平均 10min 缩短到了平均 2min,节约了 80%的闲置宝贵算力损失。
四、总结与展望
综上,使用 JindoCache 在集团大规模机器学习模型训练中发挥了重要作用。在读样本加速场景中,使用 JindoCache 大大提升了系统的吞吐,GPU 负载利用更加均衡。CheckPoint 加速中使得端到端的模型加载速度也有了质的飞跃,使用较低成本完成了性能的巨大提升。未来我们会继续进行更多场景的尝试以及对现有功能的拓展,例如:
-
基于引用计数,自动回收闲置 DataSet 数据集;
-
数据预热,基于任务访问数据 pattern 的自动预热,按目录优先级预热/驱逐和并行预热(按目录拆解预热任务);
-
启用 rdma 来加速集群内的 worker 传输吞吐,利用好集团高性能网络基础设施。
在充分利用 JindoCache 缓存加速能力的基础上对使用方式和上层系统的对接进行优化,在软硬件结合方向一起推动性能优化和对新硬件支持。
参考链接
[01]Fluid
https://github.com/fluid-cloudnative/fluid
[02] JindoCache
https://github.com/aliyun/alibabacloud-jindodata/blob/master/docs/user/6.x/6.2.0/jindo_fluid/jindo_fluid_overview.md
更多 Fluid 和 JindoCache 相关介绍请参考以上链接
这篇关于阿里集团基于 Fluid+JindoCache 加速大模型训练的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






