本文主要是介绍代码+视频一步到位:手把手教你R语言竞争风险模型建模-列线图-校准曲线-K折验证-外部验证- 决策曲线,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
竞争风险模型就是指在临床事件中出现和它竞争的结局事件,这是事件会导致原有结局的改变,因此叫做竞争风险模型。比如我们想观察患者肿瘤的复发情况,但是患者在观察期突然车祸死亡,或者因其他疾病死亡,这样我们就观察不到复发情况了,这种情况下不能把缺失数据仅仅当做右删失处理,这样的话会造成数据的估值错误。这是我们应该优先选择竞争风险模型来做数据分析,而不是COX回归。我们在既往文章《手把手教你使用R语言做竞争风险模型并绘制列线图》中已经介绍了cmprsk包建立竞争风险模型和绘制列线图,但是cmprsk包功能还是相对简单一点,而且制作列线图的时候还需要对数据进行加权,对新手不怎么友好,许多人做不出来。
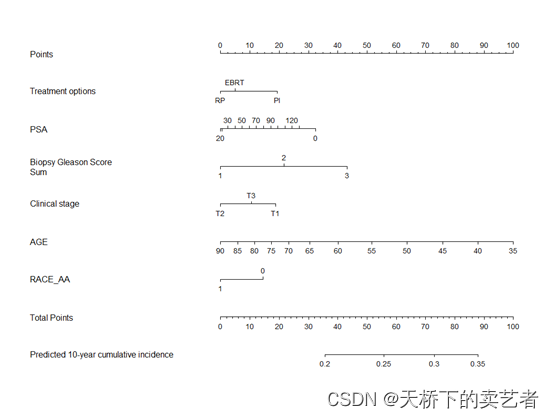
今天我们来介绍一下QHScrnomo包,QHScrnomo是在cmprsk包的基础上将功能呢继续完善,简化流程,可以做出竞争风险模型建模-列线图-校准曲线-K折验证-外部验证-决策曲线等诸多功能,总有一款适合你。
好了,废话不多说,立即开始
为竞争风险模型构建列线图
代码
library(QHScrnomo)
#公众号回复:前列腺癌,可以获得这个数据
bc<-read.csv("E:/r/test/qianliexian.csv",sep=',',header=TRUE)
######数据按7:3比例划分
set.seed(123)
tr1<- sample(nrow(bc),0.7*nrow(bc))##随机无放抽取
bc_train <- bc[tr1,]#70%数据集
bc_test<- bc[-tr1,]#30%数据集
#######整理数据
dd <- datadist(bc_train)
options(datadist = "dd")
######建立模型
prostate.f <- cph(Surv(TIME_EVENT,EVENT_DOD == 1) ~ TX + rcs(PSA,3) +BX_GLSN_CAT + CLIN_STG + rcs(AGE,3) +RACE_AA, data = bc_train,x = TRUE, y= TRUE, surv=TRUE,time.inc = 144)prostate.crr <- crr.fit(prostate.f,cencode = 0,failcode = 1)
#解析模型
summary(prostate.crr)
#对部分指标重命名,这样新的名字就会在列线图出现
prostate.g <- Newlabels(prostate.crr,c(TX = 'Treatment options', BX_GLSN_CAT = 'Biopsy Gleason Score Sum',CLIN_STG = 'Clinical stage'))
###建立列线图并绘图
nomogram.crr(prostate.g,failtime = 120,lp=FALSE,xfrac=0.65,fun.at = seq(0.2, 0.45, 0.05),funlabel = "Predicted 10-year cumulative incidence")nomogram.crr(prostate.crr,failtime = 120,lp=FALSE,xfrac=0.65,fun.at = seq(0.2, 0.45, 0.05),funlabel = "Predicted 10-year cumulative incidence")##计算公式
sas.cmprsk(prostate.crr, time = 120)###10折交叉验证
bc_train$preds.tenf <- tenf.crr(prostate.crr, time=120, fold = 10)##C指数 cindex
with(bc_train, cindex(preds.tenf,ftime = TIME_EVENT,fstatus =EVENT_DOD, type = "crr"))["cindex"]##Cindex计算好以后我们继续绘制校准曲线
with(bc_train,groupci(preds.tenf, ftime = TIME_EVENT,fstatus =EVENT_DOD, g = 5, u = 120,xlab = "Nomogram predicted 10-year cancerspecific mortality",ylab = "Observed predicted 10-year cancerspecific mortality")
)with(bc_train,groupci(preds.tenf, ftime = TIME_EVENT,fstatus =EVENT_DOD, g = 10, u = 120,xlab = "Nomogram predicted 10-year cancerspecific mortality",ylab = "Observed predicted 10-year cancerspecific mortality")
)
这篇关于代码+视频一步到位:手把手教你R语言竞争风险模型建模-列线图-校准曲线-K折验证-外部验证- 决策曲线的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




