本文主要是介绍深度学习(生成式模型)—— Consistency Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 预备知识:SDE与ODE
- Method
- 实验结果
前言
Diffusion model需要多次推断才能生成最终的图像,这将耗费大量的计算资源。前几篇博客我们已经介绍了加速Diffusion model生成图像速率的DDIM和Stable Diffusion,本节将介绍最近大火的Consistency Models(代表模型:Dalle-3),其允许Diffusion model仅经过一次推断就生成最终的图像,同时也允许少量多次推断来生成最终的图像。
预备知识:SDE与ODE
yang song博士在《Score-Based Generative Modeling Through Stochastic Differential Equations》一文中提出可以使用SDE(随机微分方程)来刻画Diffusion model的前向过程,并且用SDE统一了Score-based Model (NCSN)和DDPM的前向过程与反向过程。此外,SDE对应了多个前向过程,即从一张图到某个噪声点的加噪方式有多种,但其中存在一个ODE(常微分方程)形式的前向过程,即不存在随机变量的确定性的前向过程。
具体可查看前一篇博客score-based generative modeling through stochastic differential equations
Method

Consistency Models的核心可总结为上图,在一条ODE轨迹上(可以简单理解为从一个图像到某个噪声点,每一个步骤加的噪声都是特定的,比如第一步加的噪声为0.1,第二步加的噪声为0.2,一旦图像确定了,则对应的噪声点也会被确定),训练一个模型 f θ ( x t , t ) f_\theta(x_t,t) fθ(xt,t),其满足对于任意的 t 、 t ′ t、t' t、t′,模型的输出都一致,即
f θ ( x t , t ) = f θ ( x t ′ , t ′ ) (1.0) f_\theta(x_t,t)=f_\theta(x_{t'},{t'})\tag{1.0} fθ(xt,t)=fθ(xt′,t′)(1.0)
模型 f θ ( x t , t ) f_\theta(x_t,t) fθ(xt,t)即为Consistency Models,这里有个关键点,即训练Consistency Models时,必须是在ODE轨迹上。如果是在SDE轨迹,如下图所示,则有一个x对应多个y的情况出现,从同一个点出发,第一次迭代对应的轨迹是黑线,第二次迭代对应的轨迹是红线,模型将很难收敛。

为了实现式1.0,则只需要采样ODE轨迹上的两个点 x t x_t xt, x t ′ x_{t'} xt′,在套用一个L2 或L1 loss即可。
我们可以使用一系列的ODE solver(即在反向过程中不会引入随机性噪声的Diffusion model,例如DDIM)来帮助我们确定ODE轨迹上的两个点。
注意到式1.0也是自监督学习的优化目标,因此也会有收敛到奔溃解的情况,比如模型所有参数都为0,因此作者选用了自监督学习中的MoCo解决此类问题。
上述思路总结出的训练策略为Consistency Distillation,一个训练范式如下图

如下图,作者也给出了上述算法一些理论上的性质,个人觉得不是本算法的核心,故不总结

此外,作者也提出了Consistency Training的训练策略,即通过往一张图像里持续添加一个固定的噪声来获得一个ODE轨迹

实验结果
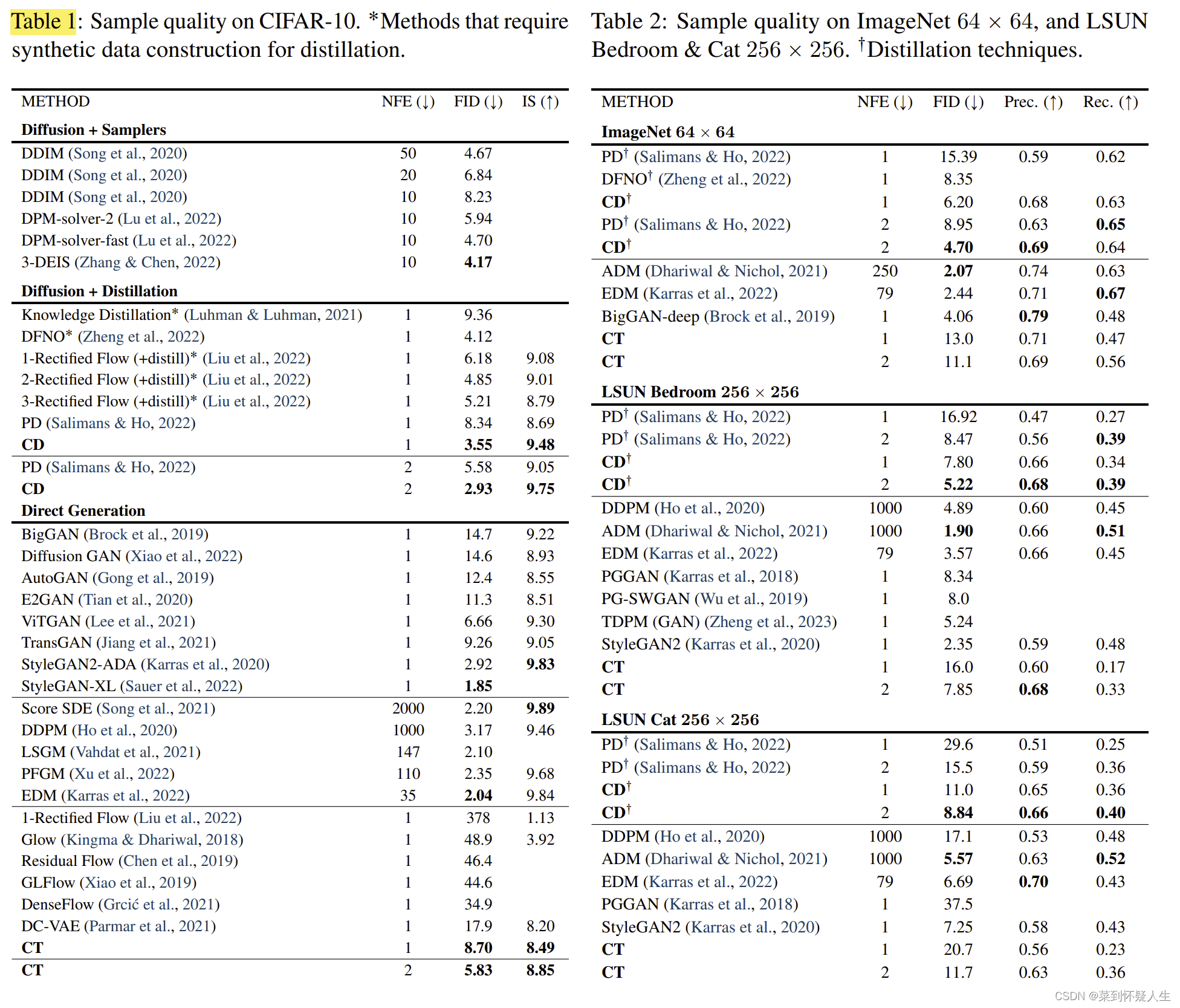
CD表示训练策略为Consistency Distillation,CT表示训练策略为Consistency Training,整体表现上CD优于CT,Dalle3也是使用CD训练的。NFE表示反向过程迭代次数
这篇关于深度学习(生成式模型)—— Consistency Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






