本文主要是介绍SplitFed: When Federated Learning Meets Split Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:
[2004.12088v1] SplitFed: When Federated Learning Meets Split Learning (arxiv.org)
AAAI 2022
摘要:
联邦学习+分割学习:消除其固有的缺点的两种方法,以及结合差分隐私和PixelDP的精细架构配置,以增强数据隐私和模型的鲁棒性
提出联邦学习和分割学习的融合,基于差分隐私的度量 和 PixelDP
分割学习(拆分学习):
在分布式机器学习框架中,数据可能被分成多个块,每个块被发送到不同的计算节点上进行处理。每个节点完成其部分的训练后,将结果发送回中心服务器或另一个节点,以便进行后续的训练迭代。这种方法可以提高训练过程的速度和效率,尤其是在处理大量数据时。

差分隐私的度量 和 PixelDP:
基于差分隐私的度量是一种用于保护数据隐私的技术,它通过向数据集中添加受控的随机噪声来防止任何人获取关于数据集中个体的信息。这种技术引入了一个称为epsilon(ε)的隐私损失或隐私预算参数,用于控制向原始数据集添加的噪音或随机性的数量。差分隐私的核心思想是在保持个体参与者的隐私的同时,通过数据分析生成聚合洞察,确保数据的准确性。
PixelDP是一种基于差分隐私的图像隐私保护方法。它通过对每个像素进行随机化处理,使得原始图像与处理后的图像之间存在一定的差异,从而保护图像中的隐私信息。PixelDP的主要步骤包括:
- 对原始图像进行随机化处理,生成一个随机图像;
- 将随机图像与原始图像进行融合,得到保护后的图像;
- 对保护后的图像进行噪声添加,使其与原始图像之间存在一定的差异。
通过以上步骤,PixelDP可以有效地保护图像中的隐私信息,同时保持图像的可用性。实验证明,PixelDP在保护图像隐私的同时,仍能保持较高的图像质量,并且具有较好的鲁棒性。
split learning架构:
参考:Split Learning及其在数据横/纵向切分场景的应用 - 知乎 (zhihu.com)
Split Learning被提出的场景是:多个常规算力节点(Alices)+一个超级算力节点(Bob)。
核心思想是各方在不泄露原始数据的情况下,共同训练一个完整的模型,同时将模型中计算负载较高的部分安排在Bob节点
SFL框架:
(1)差异私有知识扰动
(2)用于鲁棒学习的PixelDP
(3)SFL的总成本分析
整体架构:
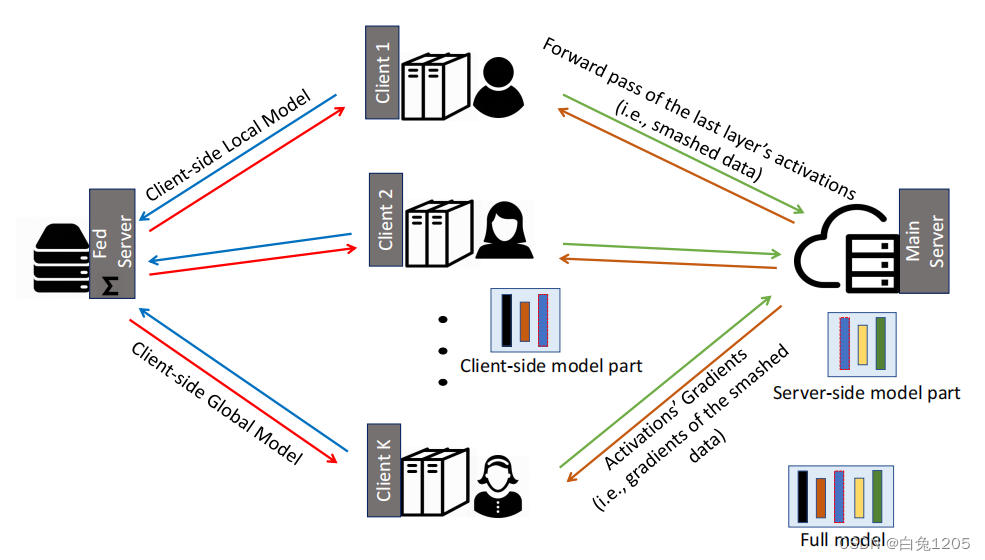
所有客户端并行地执行计算,并与主服务器和fed服务器进行交互。
客户端可以是具有低计算资源的医院或医疗物联网,主服务器可以是具有高性能计算资源的云服务器。引入fed服务器以在客户端本地更新上执行FedAvg。
此外,fed服务器在每一轮网络训练中同步客户端全局模型。fed服务器的计算(主要是计算FedAvg)并不昂贵。因此,可以在本地边缘边界内托管fed服务器。或者,如果我们在fed服务器上对加密信息执行所有操作,即基于同态加密的客户端模型聚合,则主服务器可以执行fed服务器的操作。
工作流程:
(1)所有客户端并行地在其客户端模型(包括其噪声层)上执行正向传播,并将其粉碎的数据传递给主服务器。
(2)然后,主服务器在其服务器端模型上处理前向传播和后向传播,每个客户端的粉碎数据分别以(某种程度上)并行的方式进行。
(3)然后,它将粉碎数据的梯度发送到相应的客户端以进行反向传播。
(4)然后,服务器通过FedAvg更新其模型,即在对每个客户端的粉碎数据进行反向传播期间计算的梯度的加权平均。
(5)在客户端,在接收到其粉碎数据的梯度后,每个客户端对其客户端本地模型执行反向传播,并计算其梯度。
(6)DP机制用于将这些渐变设置为私有,并将它们发送到FED服务器。FED服务器执行客户端本地更新的FedAvg,并将其发送回所有参与的客户端。
基于服务器端聚合:
提出了SFL的两种变体:
- 第一个被称为splitfedv1 (SFLV1),在算法1和2中描述。
- 下一个算法被称为splitfedv2 (SFLV2),它的动机是通过移除算法1中服务器端计算模块中的模型聚合部分来提高模型精度
在算法1中,所有客户端的服务器端模型分别并行执行,然后在每个全局历元进行聚合以获得全局服务器端模型。相比之下,SFLV2根据客户端粉碎的数据顺序处理服务器端模型的前后传播(服务器端模型没有FedAvg)。
客户端顺序是在服务器端操作中随机选择的,模型在每一次前向向后传播中都会得到更新。此外,服务器端同步接收来自所有参与客户端的粉碎数据。客户端操作与SFLV1中相同;fed服务器执行客户端本地模型的fedavg,并将聚合模型发送回所有参与的客户端。这些操作不受客户订单的影响,因为本地客户端模型是通过加权平均方法(即fedavg)进行聚合的。
基于数据标签共享:
由于SFL中的ML模型是分裂的,我们可以在两种设置下进行ML;
(1) 将数据标签共享到服务器
(2) 不将任何数据标签共享到服务器。
算法 1 考虑具有数据标签共享的 SFL。在没有共享数据标签的情况下,假设设置简单,SFL 中的 ML 模型可以分为三个部分。每个客户端将处理两个客户端模型部分;一个具有 W 的前几层,另一个具有最后几层 W 和损失计算。剩下的中间层W将在服务器端进行计算。SL 的所有可能配置,包括垂直分区数据、扩展普通和多任务 SL,可以在 SFL 中与其变体类似地执行。
隐私保护的原因分析:
SFL固有的隐私保护能力是由于两个原因:
首先,它采用了模型到数据的方法
其次, SFL在一个分裂的网络上进行ML
ML学习中的网络分割使客户端/fed服务器和主服务器能够通过不允许主服务器获得客户端模型更新来维护完整的模型隐私,反之亦然。主服务器只能访问被破坏的数据(即切割层的激活向量)。好奇的主服务器需要反转所有客户端模型参数,即权重向量,来推断数据和客户端模型。如果我们用足够多的节点配置客户端ML网络的全连接层,那么推断客户端模型参数和原始数据的可能性是非常小的[9]。然而,对于较小的客户端网络,出现此问题的可能性可能很高。这个问题可以通过修改客户端的损失函数来控制[23]。由于同样的原因,客户端(只能访问来自主服务器的破碎数据的梯度)和fed服务器(只能访问客户端更新)无法推断服务器端模型参数。由于在FL中没有网络分裂和客户端和服务器端单独的训练,因此与FL相比,SFL在训练期间为ML模型提供了更好的体系结构配置,以增强隐私。
Fedadapt和FedFly也是借鉴这篇文章,并把这篇文章当作一个基线。同时都有开源的代码
参考文章:
【1】论文阅读(6) - 知乎 (zhihu.com)
【2】Split Learning及其在数据横/纵向切分场景的应用 - 知乎 (zhihu.com)
【3】PixelDP - 简书 (jianshu.com)
这篇关于SplitFed: When Federated Learning Meets Split Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









