本文主要是介绍『九章数据』新能源乘用车L2渗透率超过50%,城市NOA势不可挡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自动驾驶在新能源乘用车中的渗透率正在快速提升。
根据九章智驾数据库统计,2023年,新能源乘用车总体销量为728.65万辆,其中368.42万辆标配了L2级自动驾驶,L2标配的渗透率达到了50.56%。而在2022年,新能源乘用车L2标配渗透率仅为43%左右,2023年L2标配渗透率相对于2022年来说提升了7个百分点。
此外,2023年还有16.24万辆新能源车型可选配L2,这个数字,占新能源汽车总销量的比例为2.23%。
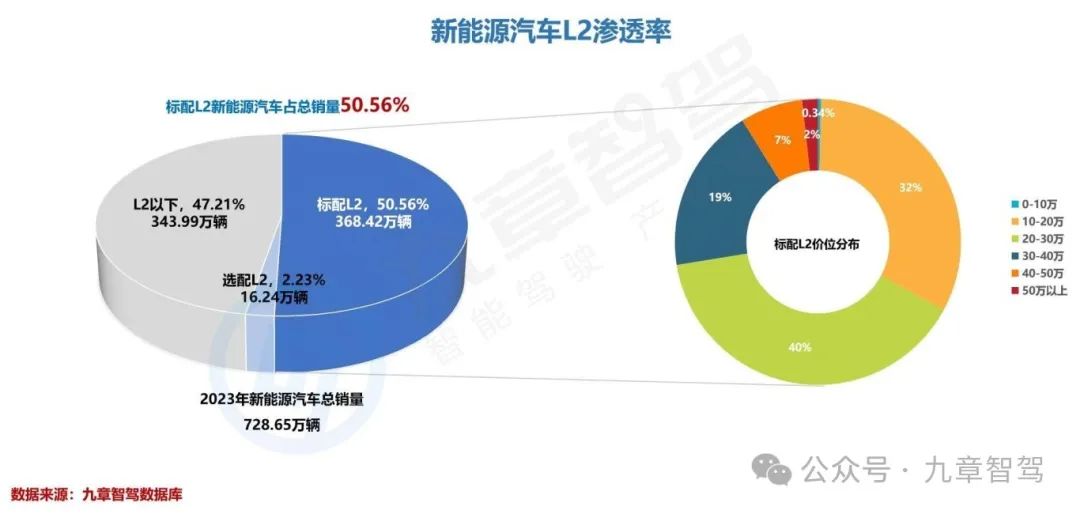
备注:九章数据库定义的L2并未区分L2、L2+、L2++、“L2.5”、“L2.9”等,将基础的车道居中控制LCC、交通拥堵辅助TJA、高速变道辅助HWA、自动泊车APA、遥控泊车RPA等功能及高阶的高速NOA、城市NOA、记忆泊车VPA等功能均归纳于L2。
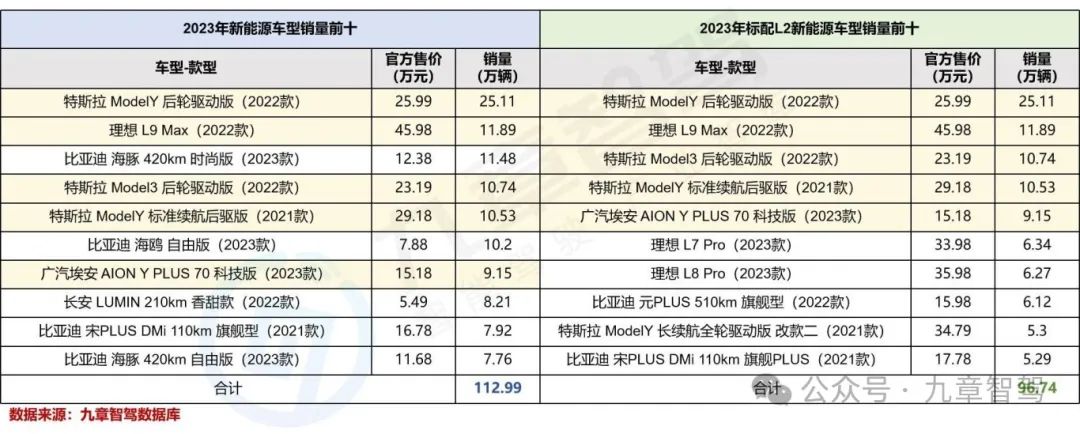
从具体车型来看,不论是新能源汽车总体销量还是标配L2的车型销量前十名中,特斯拉与理想都占据靠前位置,其新能源汽车销量与智能驾驶的渗透不容小觑。
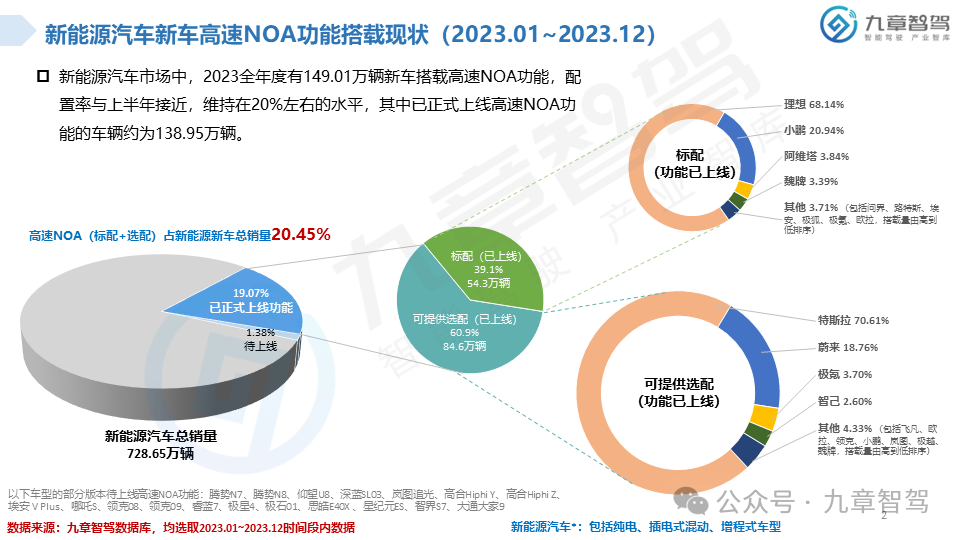
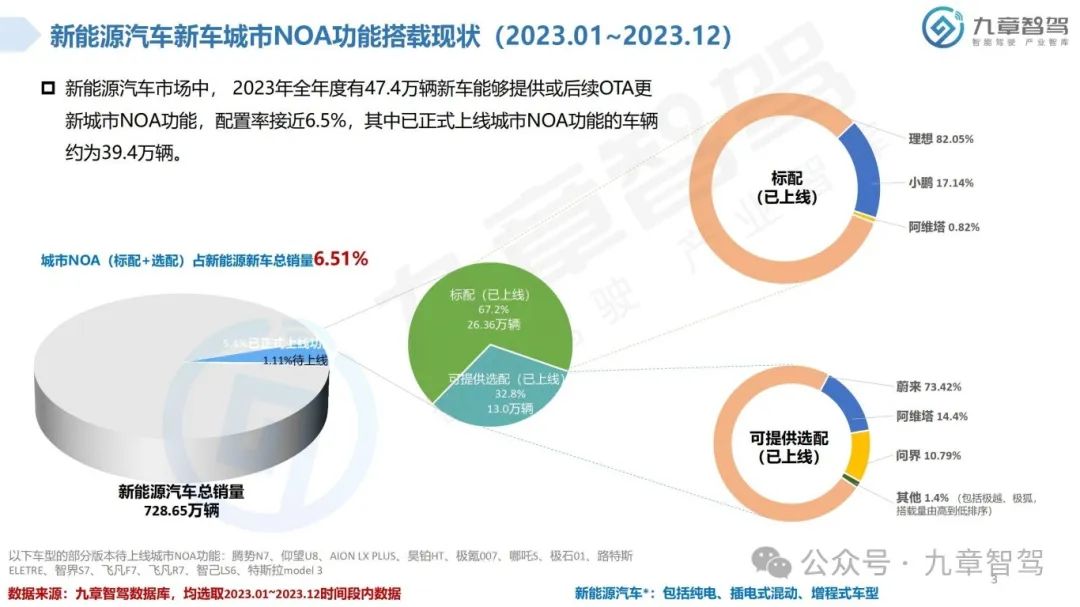
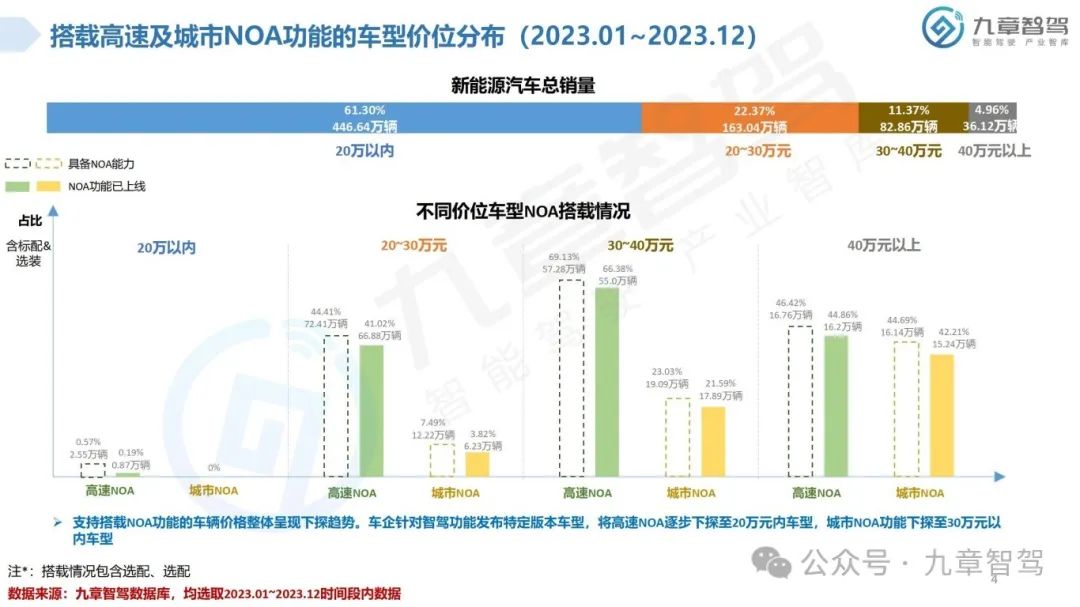
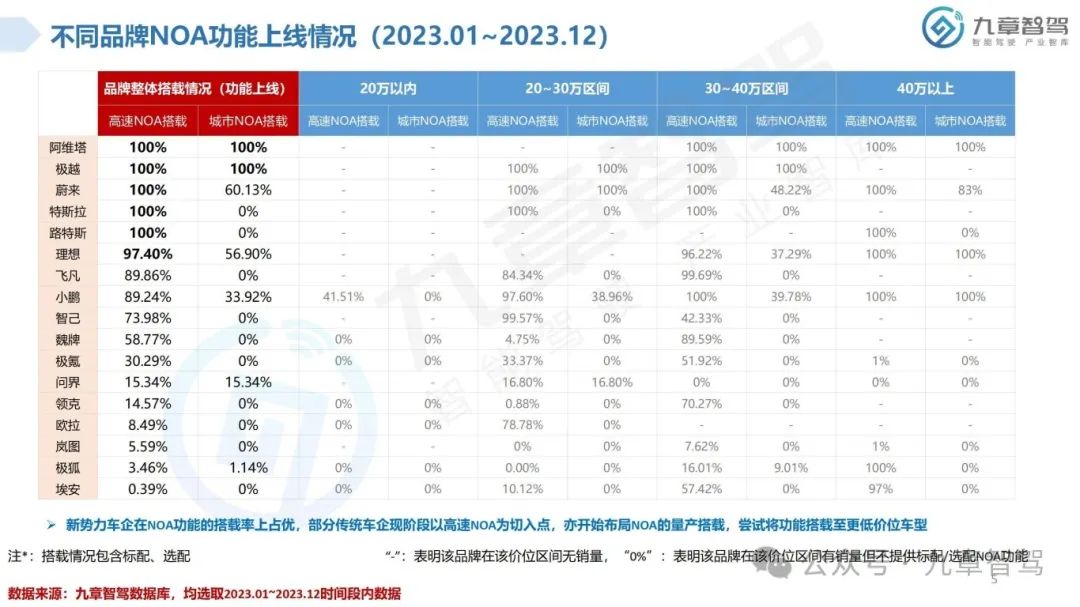
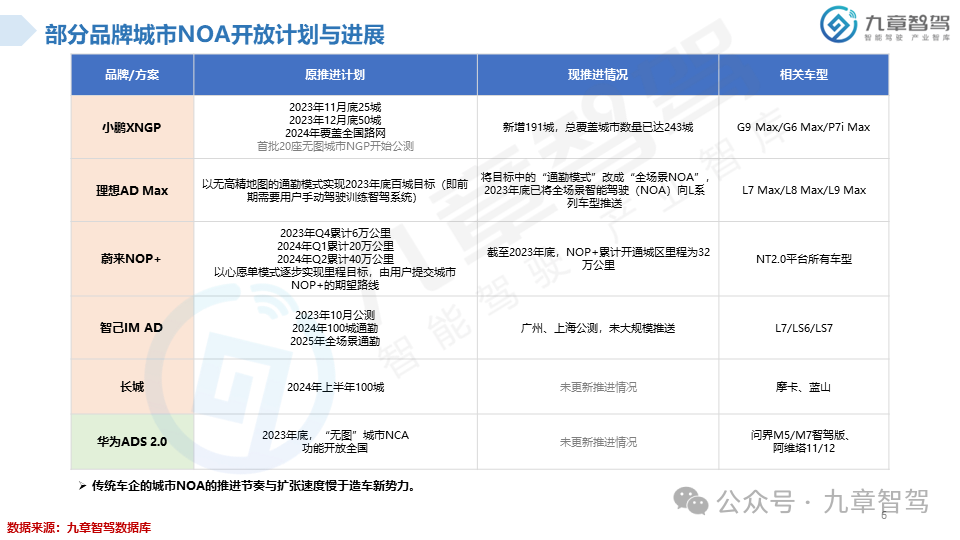
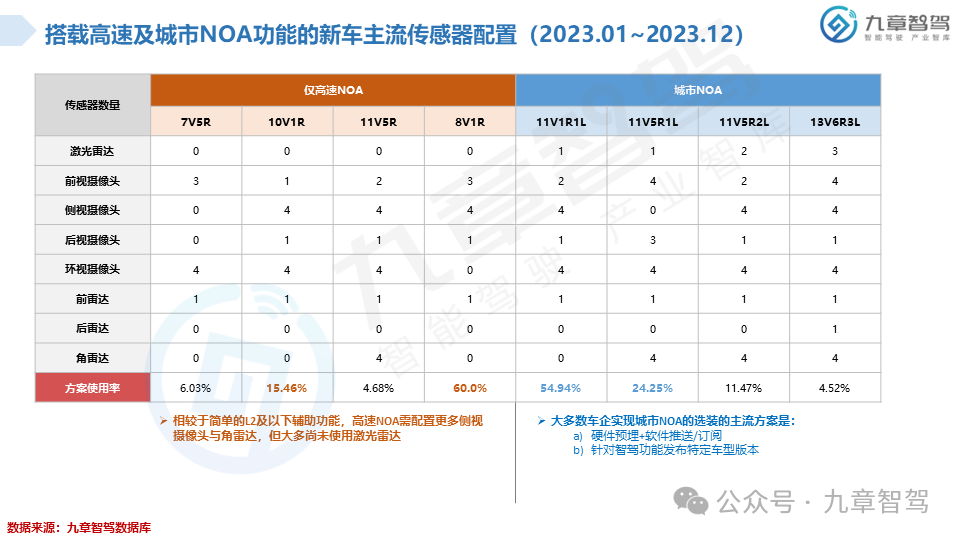
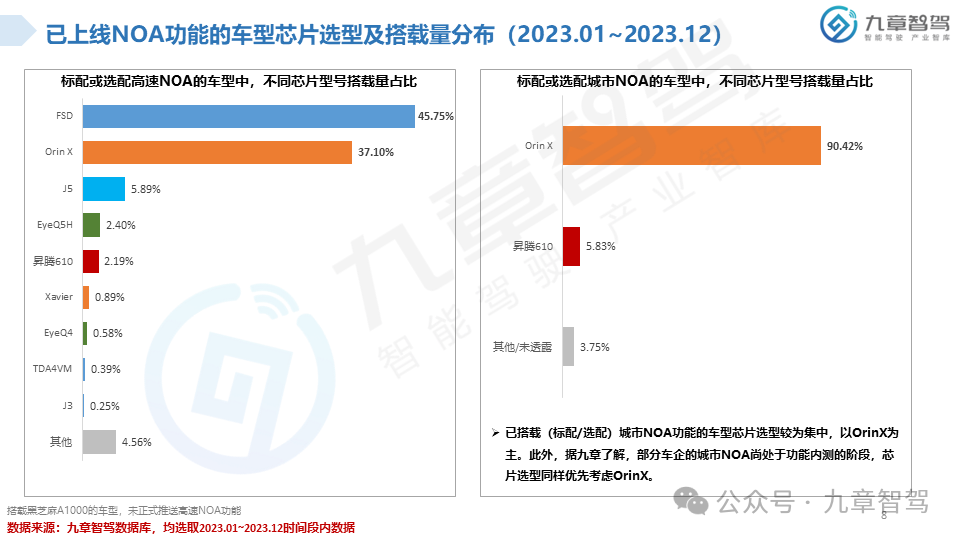
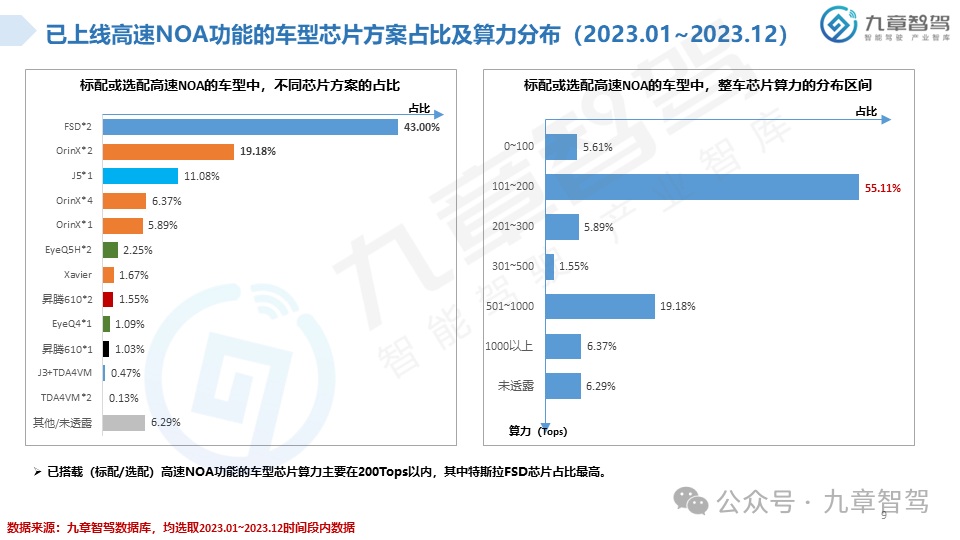
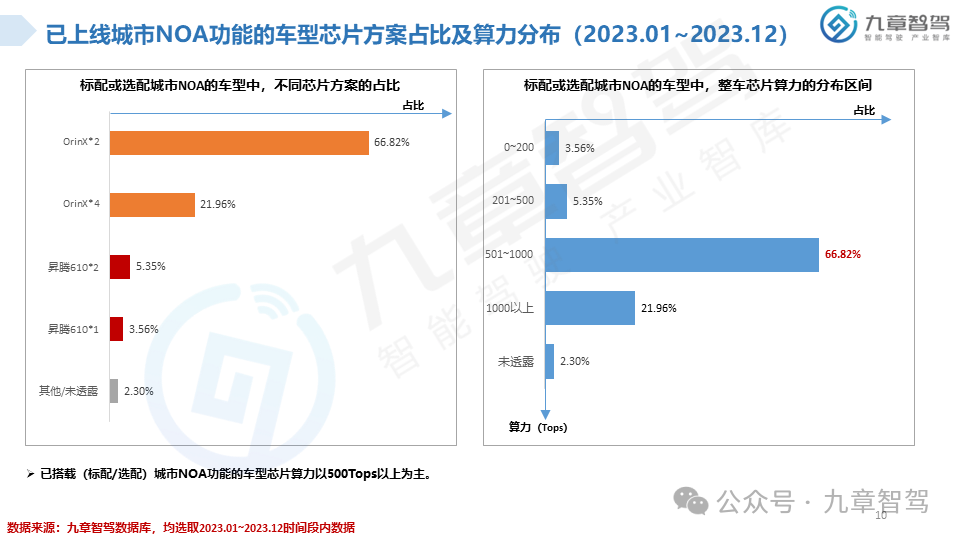
从功能来看,NOA是智能驾驶界关注度最高的功能。2023年,高速NOA的落地应用初具规模,城市NOA也进入开城布局的阶段,九章将从功能搭载现状、车型价位分布、传感器配置、芯片选型等角度分析2023年新能源乘用车NOA功能搭载情况。
根据九章数据库统计,新能源乘用车高速NOA功能的搭载率达到了20.45%,新能源乘用车城市NOA功能的搭载率达到了6.51%。具体分析详见以下《2023年度新能源汽车高速及城市NOA功能搭载现状分析报告》。

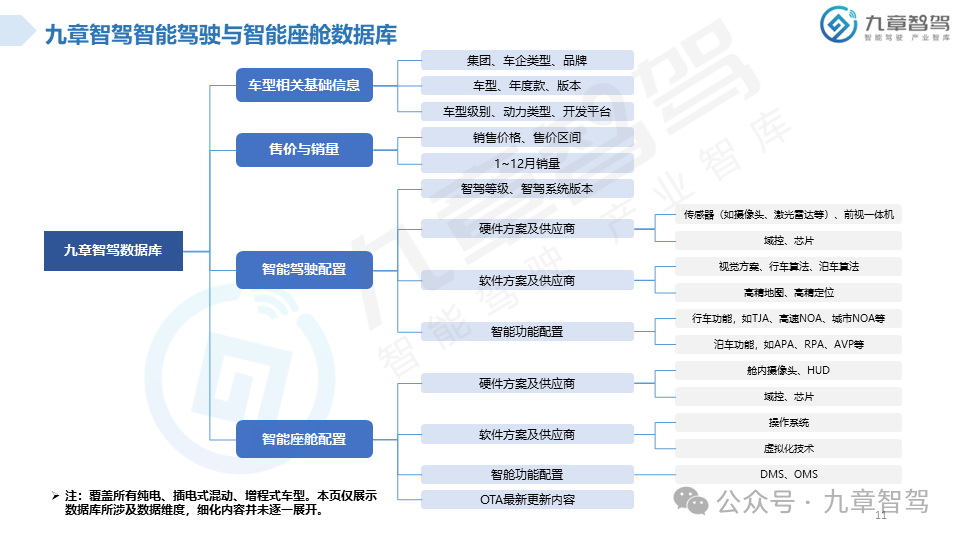
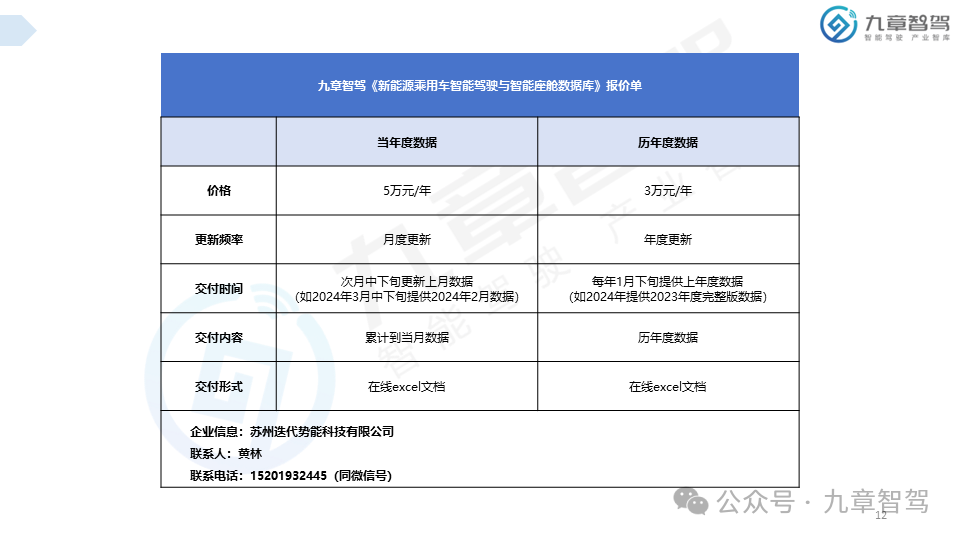
九章智驾数据库已正式发售,如有相关需求,请扫描以下二维码添加负责人微信(注明企业、岗位、姓名)

这篇关于『九章数据』新能源乘用车L2渗透率超过50%,城市NOA势不可挡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






