本文主要是介绍【博士每天一篇论文-算法】Continual Learning Through Synaptic Intelligence,SI算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阅读时间:2023-11-23
1 介绍
年份:2017
作者:Friedemann Zenke,巴塞尔大学弗里德里希·米歇尔研究所(FMI) Ben Poole,谷歌 DeepMind 研究科学家
期刊: International conference on machine learning. PMLR
引用量:2309
这篇论文介绍了受生物神经网络启发的智能突触,用于解决人工神经网络(ANNs)中的忘却灾难问题。当ANNs学习新任务时,会忘记之前学习的任务,这就是所谓的忘却灾难。智能突触通过累积与任务相关的信息来存储新记忆,而不会忘记旧记忆,从而减少忘却,同时保持计算效率。该方法通过为每个突触赋予一个本地的“重要性”度量,来衡量突触在过去训练任务中解决问题的能力。在训练新任务时,对于重要的参数变化进行惩罚,以避免旧的记忆被覆盖。该方法通过保留对过去任务重要参数的改变,同时只允许不重要的参数学习来避免灾难性遗忘。
2 创新点
- 引入了 intelligent synapses(智能突触)的概念,智能突触通过累积与任务相关的信息来存储新的记忆,同时不会忘记旧的记忆,从而降低遗忘,同时保持计算效率。通过单个突触估计其对过去任务的重要性,并对最重要突触的变化惩罚来解决灾难性遗忘。
- 这篇论文指出,ANNs的问题在于它们未能融入生物突触的复杂性,而生物突触使用复杂的分子机制来影响各种时间和空间尺度上的可塑性。因此,论文提出了三种缓解灾难性遗忘的方法:架构、功能和结构方法。而本文提出的方法是一种结构正则化器,可以在线计算和在每个突触局部实施。该方法保持了总损失函数关于所有任务的总和的全局损失,从而减少了在过去被认为是具有重要影响的权重的剧烈变化。
- 智能突触为ANNs引入了生物复杂性,并使其能够在数据分布可能随时间改变的新领域中实现持续学习。
3 相关研究
作者说分为三种研究方向,其实细分的话,可以分为四种:
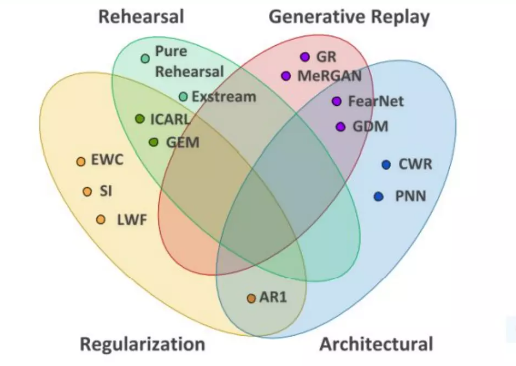
(1)架构
架构方法通过改变网络的架构来减少任务之间的干扰,而不改变目标函数。最简单的架构正则化形式是冻结网络中的某些权重,使其保持完全相同(Razavian et al., 2014)。更灵活的方法是减少与原始任务共享的层的学习率,同时进行微调,以避免参数的剧烈变化(Donahue et al., 2014; Yosinski et al., 2014)。使用ReLU、MaxOut和局部取胜等不同非线性的方法已被证明可提高在排列的MNIST和情感分析任务上的性能(Srivastava et al., 2013; Goodfellow et al., 2013)。此外,注入噪声以稀疏梯度(使用dropout)也可以提高性能(Goodfellow et al., 2013)。Rusu等人(2016)最近的工作提出了更大胆的架构改变,其中先前任务的整个网络被复制并增加了新的特征,同时解决新任务。这样完全可以防止对前面任务的遗忘,但是随着任务数量的增加,架构复杂性也会增加。
(2)功能
功能方法对灾难性遗忘进行附加惩罚项,惩罚神经网络输入-输出函数的变化。在Li&Hoiem(2016)中,通过使用知识蒸馏的一种形式,鼓励先前任务网络和当前网络在应用于新任务的数据时的预测结果相似(Hinton et al., 2014)。类似地,Jung等人(2016)使用最终隐藏激活之间的L2距离进行正则化,而不是使用知识蒸馏惩罚项。这两种正则化方法旨在通过使用先前任务的参数存储或计算额外的激活来保留旧任务的输入-输出映射的某些方面。这使得功能方法变得计算上昂贵,因为它要求每个新数据点都要通过旧任务的网络进行前向传递。
(3)正则化
第三种技术是结构正则化,涉及对参数施加惩罚,以使其保持接近于旧任务的参数。最近,Kirkpatrick等人(2017)提出了弹性权重合并(EWC),对新任务的参数和旧任务的参数之间的差异施加二次惩罚。他们使用的对角线加权与旧任务上旧参数的Fisher信息度量的对角线成正比。准确计算Fisher的对角线需要对所有可能的输出标签求和,因此其复杂度与输出数量成线性关系。这限制了这种方法在低维输出空间中的应用。
4 算法
4.1 算法原理
在学习一个任务后,由于只能访问当前任务的损失函数,无法直接使用该任务的损失函数,所以作者构造一个代理损失函数(surrogate loss)来近似原始损失函数。这样在训练新任务时,对于重要的参数变化进行惩罚,以避免旧的记忆被覆盖。
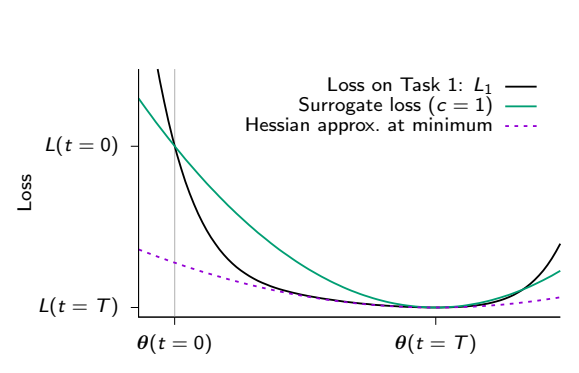
图中展示了在学习完一个任务后,使用二次代理损失函数来匹配原始损失函数下降动态的情况。这个二次代理损失函数满足三个条件:总损失函数的下降量、参数空间的总运动量和在末态达到最小值。这个代理损失函数的构造能更好地总结原始损失函数的下降轨迹。
该方法中,作者目标是限制重要参数的改变,使用二次代理损失来近似对过去任务的损失函数,并将重要参数的改变量与参数距离相结合。通过调整二次代理损失的强度参数,可以权衡对新旧任务的记忆。

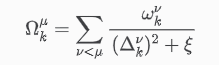
其中,c为强度参数,c = 1将对应于对旧记忆和新记忆的等权重分配, θ k \theta_{k} θk为网络权重参数, Ω k u \Omega_k^u Ωku为参数特定的正则化强度, ξ \xi ξ为额外的阻尼参数,用于在 Δ k v \Delta_k^v Δkv趋于0的情况下限制表达式, ω k u \omega_k^u ωku表示每个参数对总损失变化的贡献, ( Δ k v ) 2 (\Delta_k^v)^2 (Δkv)2确保正则化项具有与损失 L 相同的单位。
与现有的EWC方法相比,这种方法中的重要性计算(路径积分,path integral)是通过沿着整个学习轨迹进行信息积分来计算的,而不是在每个任务结束时计算Fisher信息矩阵的对角线,具体的如何根据学习轨迹计算参数的重要性,需要搞明白几个公式推导。
4.2 推导证明
换一种说法,首先要计算参数的重要性,然后对重要的参数进行限制改变。
(1)参数的重要性计算:
对于每个任务µ,根据以下公式计算每个参数的路径积分损失函数 ω k u \omega_k^u ωku。路径积分损失函数是参数在整个学习轨迹上的贡献的累加,表示参数的重要性。
ω k u = ∫ 0 ∞ θ k T Q d θ \omega_k^u = \int_0^{\infty} \theta_k^TQd\theta ωku=∫0∞θkTQdθ
其中, Q表示参数Hessian矩阵H的对角元素。具体按照以下步骤计算 :
- 计算参数Hessian矩阵H的特征值和特征向量,并将其表示为 λ α \lambda_{\alpha} λα 和 u α u_{\alpha} uα。
- 计算初始参数与最终参数之间的差异在特征向量 α \alpha α上的投影 d α = u α ⋅ ( θ ( 0 ) − θ ∗ ) d_{\alpha} = u_{\alpha}\cdot (\theta(0)-\theta^*) dα=uα⋅(θ(0)−θ∗)。
- 将公式(9)插入到公式(10)中,并进行基础变换以得到H的特征模式,然后进行积分计算,可以得到:
Q = ∫ 0 ∞ e − H τ t d t Q = \int_0^{\infty} e^{-H \tau t}dt Q=∫0∞e−Hτtdt
最终,通过计算路径积分损失函数 ω k u \omega_k^u ωku,可以获得参数 θ k \theta_k θk在整个学习轨迹中的重要性。
(2)以正则项加入损失函数
根据计算得到的路径积分损失函数,通过引入二次替代损失来近似参数的重要性,并保持与之前任务的损失函数相同的最小值和在参数距离上相同的下降量。
(3)更新梯度
在训练新任务时,通过惩罚对重要参数的变化来避免覆盖旧的记忆。
5 实验分析
采用的数据集有:split MNIST、permuted MNIST、split CIFAR-10、split CIFAR-100
5.1 Split MNIST
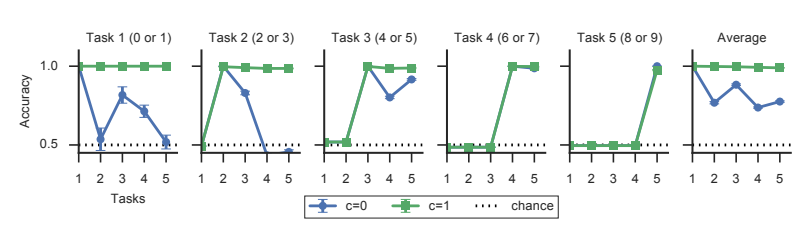
采用只有两层的MLP模型。在训练第一个任务时,两种情况下的惩罚都是零,。当在数字“2”和“3”上进行训练时(任务2),具有和没有整合的模型在任务2上的准确率都接近1。
5.2 permuted MNIST
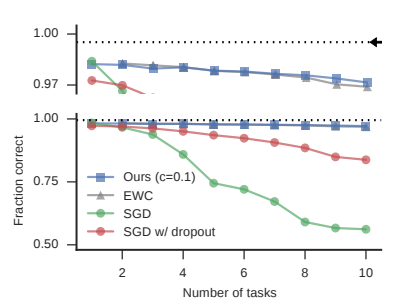
- 当不使用突触巩固(不使用正则化项)时,神经网络在学习新任务时会迅速忘记之前的任务。相比之下,通过启用突触巩固,并选择合适的参数c > 0,同一个网络在学习9个附加任务时能够保持高的分类准确性。
- 该网络学习解决所有其他任务的准确性也很高,并且仅稍微比同时训练所有数据的网络差一点。
- 实验结果与EWC的结果接近

为了更好地理解训练过程中的突触动力学,我们可视化了不同任务之 ω k u \omega_k^u ωku的成对相关性。发现,当不进行巩固时,第二个隐藏层的 ω k u \omega_k^u ωku在不同任务之间是相关的,这可能是灾难性遗忘的原因。然而,通过巩固,这些有助于降低损失的突触集在不同任务之间基本上是不相关的,因此在更新权重以解决新任务时避免了干扰。
5.3 Split CIFAR-10/CIFAR-100
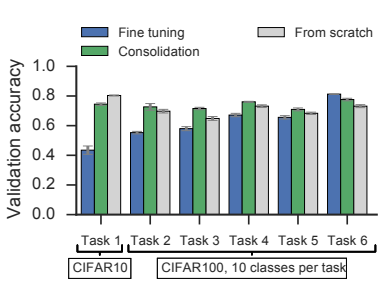
采用4个卷积层和2个带有dropout的全连接层的CNN模型,通过改变参数c的值(在1×10−3 < c < 0.1的范围内),来确定最佳c的值。研究结果发现,在训练了所有任务之后,使用巩固的网络在所有任务上的验证准确度相似,而未使用巩固的网络在老任务上的准确度明显降低。重要的是,使用巩固训练的网络性能总是优于未使用巩固的网络,除了最后一个任务。最后,对比使用巩固训练的网络在所有任务上的性能与从头(from stratch)开始训练的网络的性能,发现前者表现更好。
总之,这项研究表明在更复杂的数据集和更大的模型上,通过突触巩固动力学可以防止灾难性遗忘,并提高网络的泛化性能。
6 思考
(1)本文提出的方法在正则化惩罚方面与 EWC 类似,区别在于计算突触重要性的方式上有所不同。
- SI方法是在线计算和沿着整个学习轨迹计算重要性衡量,而EWC方法则是在每个任务结束时,依赖于参数最终值的点估计来计算重要性。
- SI方法通过结构化的正则化器来减少参数的突然改变,EWC方法需要在单独的阶段计算参数的Fisher信息矩阵的对角线 。
- SI方法可以在每个突触本地实施,并且可以在线计算,以便在以前的任务中引导学习 。
(2)代理损失函数中的常数c成为了一个超参数,需要对不同任务进行调参。c的值在1×10−3 < c < 0.1的范围内。
这篇关于【博士每天一篇论文-算法】Continual Learning Through Synaptic Intelligence,SI算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









