本文主要是介绍P1825 [USACO11OPEN] Corn Maze S 广度优先搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 题目链接
- 题目描述
- 解题思路
- 代码实现
- 总结
题目链接
链接: P1825 [USACO11OPEN] Corn Maze S
题目描述
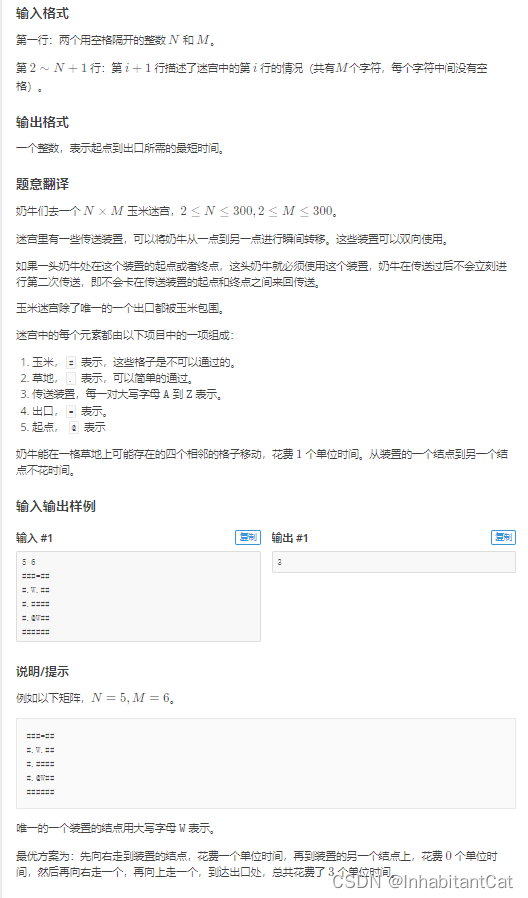
解题思路
这道题目是一个典型的迷宫问题,我们需要找出从起点到终点的最短路径。解决这类问题的常用方法是使用广度优先搜索(BFS)算法。
首先,我们需要读取迷宫的输入,并确定起点的位置。然后,我们可以使用一个队列来存储每一步的状态,其中每个状态记录了当前位置的坐标和到达该位置的步数。我们还需要一个布尔数组来标记已经访问过的位置,以避免重复访问。
在搜索过程中,我们从起点出发,将起点的状态加入队列,并标记起点为已访问。然后,我们不断从队列中取出状态,并根据当前位置的上下左右四个方向进行扩展。如果扩展得到的位置是墙壁或已经访问过的位置,则跳过该位置。如果扩展得到的位置是传送门,则查找相应传送门的另一端位置,并将另一端位置的状态加入队列,步数加1。如果扩展得到的位置是空地,则将该位置的状态加入队列,步数加1,并标记该位置为已访问。
当遇到传送门时,我们需要查找相应传送门的另一端位置,并将另一端位置的状态加入队列,步数加1。
具体而言,我们可以在搜索过程中,判断当前位置是否为传送门(即位置上的字符为大写字母)。如果是传送门,我们可以调用一个函数 cs(char c, int x, int y) 来查找传送门 c 的另一端位置。该函数会遍历迷宫中的其他位置,找到与给定传送门对应的传送门位置。
在函数 cs 中,我们可以使用两层循环遍历迷宫的每个位置:
对于每个位置 (i, j),如果它不是当前位置 (x, y),并且字符为传送门 c,则返回位置 (i, j)。
如果 cs 函数找到了与传送门 c 对应的位置 (i, j),我们可以将该位置的状态 (i, j, t.step + 1) 加入队列,步数加1。其中 t.step + 1 表示到达 (i, j) 位置需要的步数。
需要注意的是,如果 cs 函数没有找到与传送门 c 对应的位置,我们应该返回一个特殊的标记,例如 {-1, -1},表示未找到对应的传送门。
通过在搜索过程中处理传送门,我们可以在搜索最短路径时,考虑迷宫中的传送功能,从而得到正确的结果。
我们在搜索过程中不断扩展状态,直到队列为空或者找到等号位置。如果最终找到等号位置,则输出到达该位置的步数;否则,输出-1表示无解。
代码实现
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int> PII;
const int N=310;
char a[N][N];
bool st[N][N];
struct node{int x;int y;int step;
}q[N*N];
int dx[4]={1,0,-1,0},dy[4]={0,1,0,-1};
int n,m,ans;
PII cs(char c,int x,int y)
{for(int i=1;i<n-2;i++)for(int j=1;j<m-2;j++)if(i!=x&&a[i][j]==c) return {i,j};
}
void bfs(int x,int y)
{int hh=0,tt=0;q[0]={x,y,0}; st[x][y]=true;while(hh<=tt){node t=q[hh++];if(a[t.x][t.y]=='='){cout<<t.step<<endl;return;} for(int i=0;i<4;i++){int nx=t.x+dx[i];int ny=t.y+dy[i];if(a[nx][ny]=='#'||st[nx][ny]) continue;if ( ny < m && a[nx][ny] != '#' && !st[nx][ny]) {st[nx][ny] = true;if (a[nx][ny] >= 'A' && a[nx][ny] <= 'Z') {// 寻找对应传送门的位置for (int j = 1; j < n-1; j++) {for (int k = 1; k < m-1; k++) {if (a[j][k] == a[nx][ny] && (j != nx || k != ny)) {q[++tt]={j,k,t.step+1};break;}}}} else {q[++tt]={nx, ny, t.step + 1};}}}}
}
int main()
{int bx,by;//起始点 cin>>n>>m;for(int i=0;i<n;i++)for(int j=0;j<m;j++){cin>>a[i][j];if(a[i][j]=='@') bx=i,by=j;} bfs(bx,by);return 0;
}
总结
总结起来,解决这道题目的关键思路是使用BFS算法进行图的遍历,通过不断扩展状态来搜索迷宫中的最短路径。通过使用队列和标记数组,我们可以确保每个位置只被访问一次,并且在找到目标位置时能够得到最短路径的步数。
通过解决这道题目,我们学到了以下几个关键点:
-
广度优先搜索(BFS)算法:这道题目的解题思路主要基于广度优先搜索算法。BFS是一种遍历图的算法,它从起点开始,逐层扩展搜索,直到找到目标位置。在解决迷宫问题中,BFS可以帮助我们找到最短路径。
-
处理传送门:题目要求我们要处理迷宫中的传送门。通过编写一个函数来查找传送门的另一端位置,我们可以在搜索过程中正确处理传送门带来的跳跃和路径缩短。
-
队列和标记数组的应用:使用队列和标记数组可以帮助我们进行状态扩展和避免重复访问。队列可以用来存储每一步的状态,并按照先进先出的顺序进行扩展,确保每个位置只被访问一次。标记数组用于标记已经访问过的位置,以避免重复访问。
在思考这道题目时,我们需要考虑以下几个方面:
-
思考问题的复杂度:对于某些复杂的问题,我们需要思考如何降低问题解决的复杂度。在这道题目中,我们使用了广度优先搜索算法,通过按层扩展的方式遍历迷宫,从而找到最短路径。这种方式能够确保我们找到的路径是最短的。
-
掌握基本的数据结构和算法:解决这道题目需要我们熟悉广度优先搜索算法以及队列和标记数组的应用。理解并灵活运用这些基本的数据结构和算法可以帮助我们解决更复杂的问题。
-
注重程序的可读性和可维护性:在解决问题的过程中,我们要注意编写具有良好可读性和可维护性的代码。合理的代码结构和注释可以使我们更好地理解和调试代码,并且在以后需要修改或扩展代码时能够更加容易。
总而言之,通过这道题目我们不仅学习了基本的算法思想和数据结构,还培养了解决问题的思维和优化思考的能力。同时,我们也明确了代码可读性和可维护性在开发过程中的重要性。
这篇关于P1825 [USACO11OPEN] Corn Maze S 广度优先搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




