本文主要是介绍【pytorch】nn.linear 中为什么是y=xA^T+b,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我记得读教材的时候是y=Wx+b, 左乘矩阵W,这样才能表示线性变化。
但是pytorch中的nn.linear中,计算方式是y=xA^T+b,其中A是权重矩阵。
为什么右乘也能表示线性变化操作呢?因为pytorch中,照顾到输入是多个样本一起算的(第一个维度是多个样本数,所以输入默认是行向量),所以用y=xA^T+b,输出的y也是行向量。
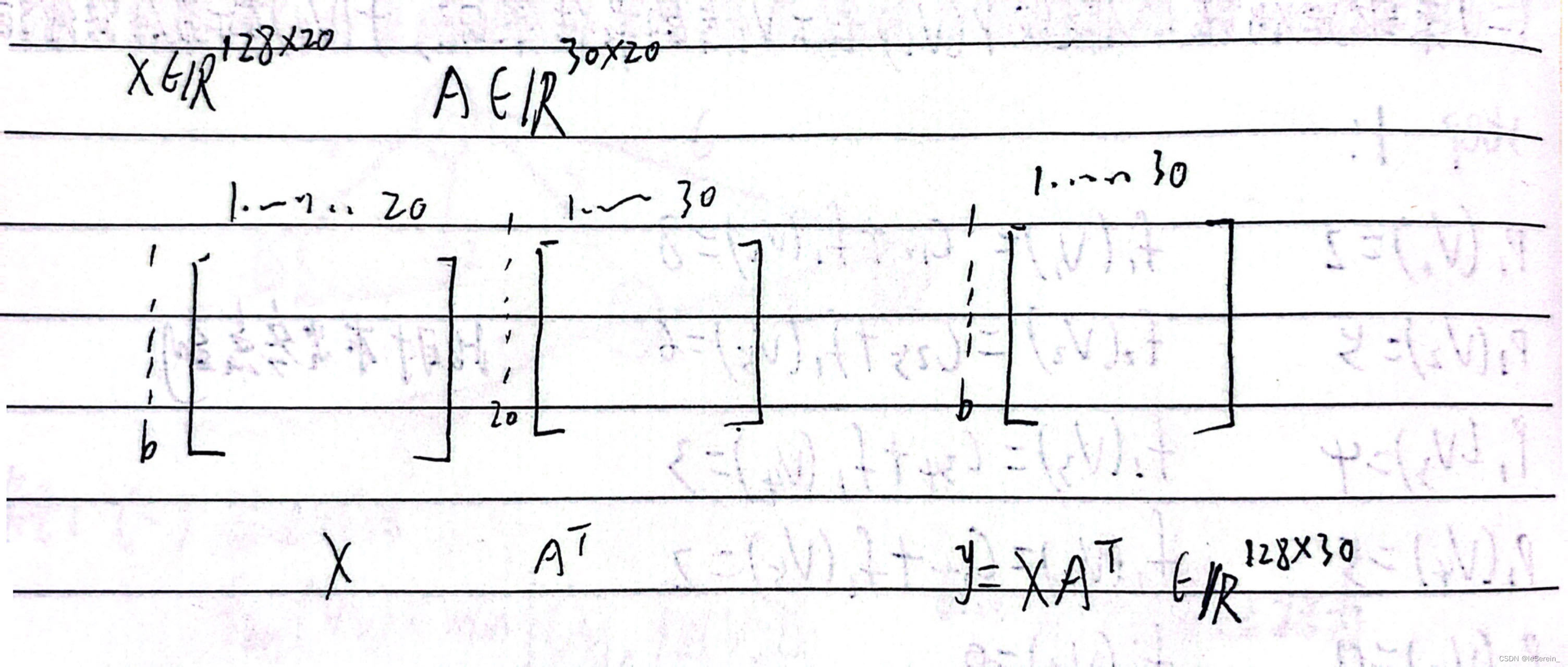
我们的教材中默认输入是列向量的,而pytorch为了用户方便,输入当作列向量,维度为(batch, dim),每行是特征
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)print(output.size())
>>> torch.Size([128, 30])
print(m.weight.shape)
>>>torch.Size([30, 20]) # 注意这里的权重维度
我们再看一张图片,理解一下代码中的实现逻辑:
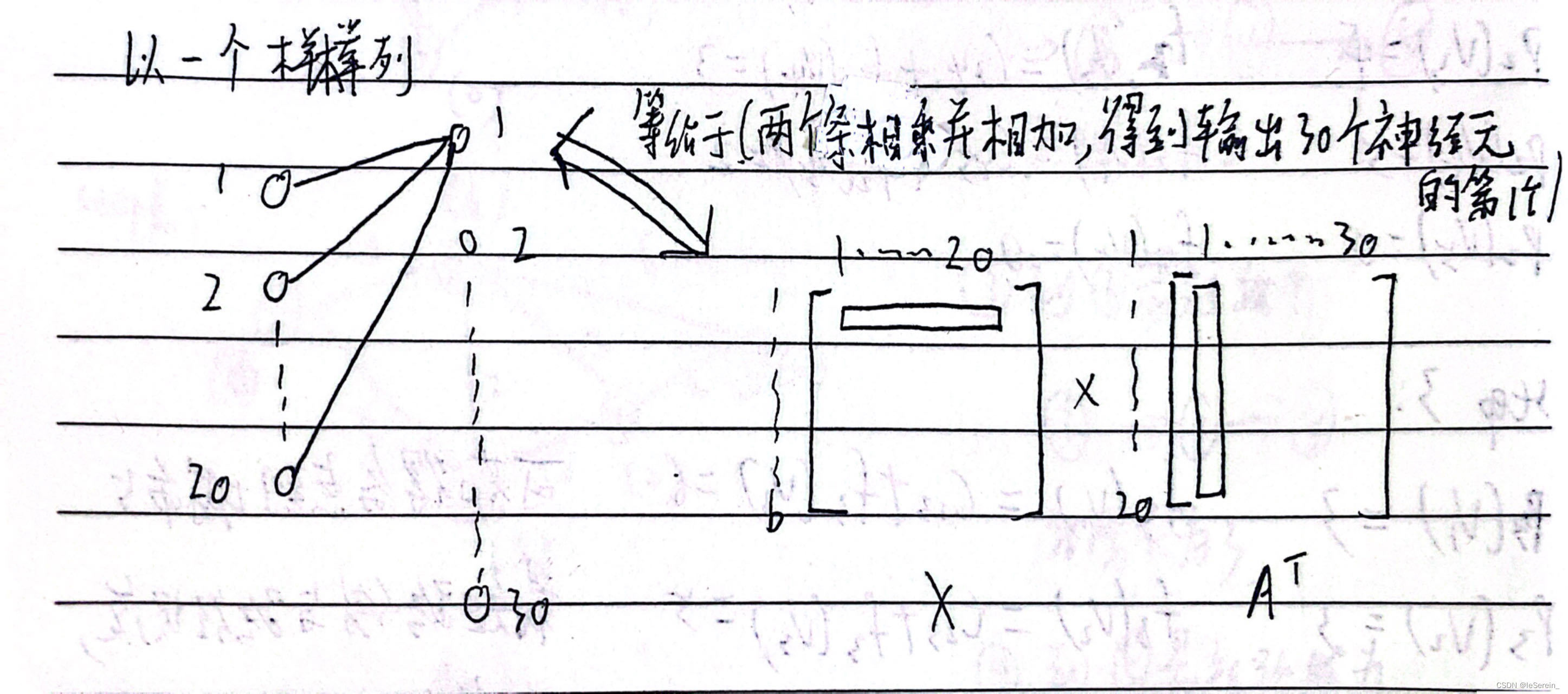
至此应该对代码的实现很理解了,但是需要注意,大家写文章中用的都还是Wx+b的写法。
不管怎样,文章和代码都是能对应上的,最多是表示方式的区别(有的用行向量,有的用列向量)
这篇关于【pytorch】nn.linear 中为什么是y=xA^T+b的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









