本文主要是介绍3D数据转换器HOOPS Exchange如何获取模型的几何数据? 干货预警!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
前面讲解过模型在内存中的结构,现在回顾一下,当模型导入成功后,整个模型数据会以原生结构的 PRC 组装树形式存放到内存中。(申请 HOOPS Exchange 试用)
PRC结构的主要类型包含四种,分别是模型文件(Model file)、产品结构节点(Product Occurrence)、零件定义(Part definitions)和表示项(Representation items),其具体结构图如下:

下面我们根据这个脉络,从文件的指针入手,简单说一下如何获取到模型的几何数据。
二、遍历模型
1、模型入口
我们在导入模型后,会获取到导入模型的文件指针(A3DAsmModelFile* m_psModelFile),它是我们遍历模型所有数据的入口。
2、解析产品结构节点(Product Occurrence)
接下来我们根据文件指针m_psModelFile查找其对应的A3DAsmModelFileData数据,在A3DAsmModelFileData数据中可以获取到“产品结构节点(Product Occurrence)”的数量和子节点集合。
之后判断子节点的类型,如果子节点也是“产品结构节点”类型,则进行递归,查找子节点下面的子节点,这样不断递归,就可以将模型中所有的“产品结构节点”找出。
如果子节点的类型是“零件定义(Part definitions)”类型,则就进行下面的解析“零件定义(Part definitions)”节点的操作。
3、解析零件定义(Part definitions)
在获取到“零件定义(Part definitions)”节点后,我们可以获取到“零件定义(Part definitions)”节点对应的“零件定义数据”,通过“零件定义数据”就可以获取到该节点对应的“表示项(Representation items)”的数量和集合。
这一级节点的解析比较简单,没有递归。
4、解析表示项(Representation items)
在获取到“表示项(Representation items)”节点后,我们就可以获取该节点封装的细分数据和 B-rep数据。
其中细分数据一定会有,即便源模型中没有,HOOPS Exchange也会生成;B-rep数据可能会有,因为有的源模型格式并不支持B-rep数据。
下面分别介绍这两种数据。
三、细分曲面数据(Tessellation)
细分曲面数据可以理解成我们肉眼所见的网格数据。我们可以获取到表示项中默认的细分曲面数据,但对于许多应用程序,获得默认曲面细分是不够的,因此可以设置细分曲面数据中的参数,根据这些参数重新生成符合要求的细分曲面数据。
A3DRWParamsTessellationData可以影响细分曲面数据的生成,其参数如下:
- TessellationLevelOfDetail - 由其它A3DRWParamsTessellationData预设值组成的高级设置。如果选择UserDefined,我们可以自定义自己的一组值。
- AccurateTessellation - 将此值设置为true将生成更适合分析的细分。可用于所有细分级别。
- AccurateTessellationWithGrid - 一种精确的曲面细分模式,其中在网格布局中插入点。
- ChordHeightRatio - 指定边界框的对角线长度与弦高的比率。
- AngleToleranceDeg - 指定边的两个连续段之间的角度。
- MaxChordHeight(和UseHeightInsteadOfRatio) - 指定曲面和生成的细分之间的最大距离。
- KeepUV - 将参数点保留为纹理点。
- AccurateSurfaceCurvatures. 曲面细分倾向于沿曲率创建更适合的三角形。
TessellationLevelOfDetail 和AccurateTessellation 设置的效果如下:

AccurateTessellationWithGrid 的设置效果如下:
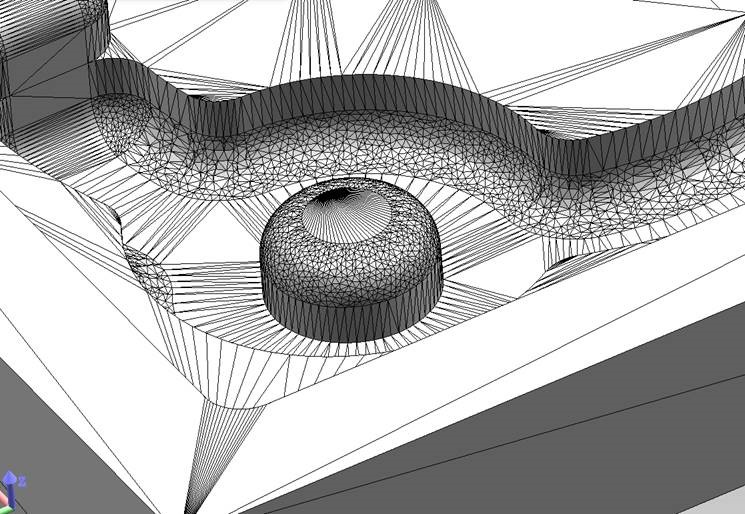
标准精确细分

通过插入网格对齐点进行精确细分
AccurateTessellationWithGridMaximumStitchLength、AccurateSurfaceCurvatures设置效果如下:

四、B-rep 数据(B-rep Data)
B-rep 数据是用数学来描述模型的数据,它是几何造型中最成熟、无二义的表示数据。
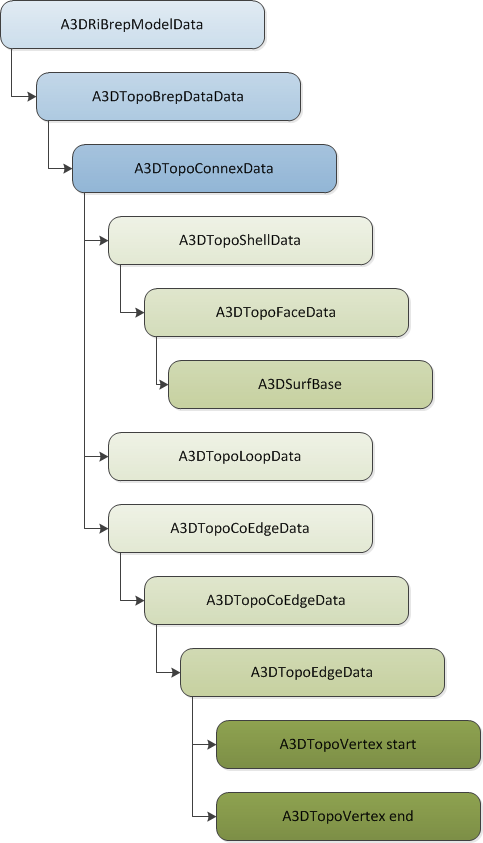
以下实体包含表示 B-rep 数据的几何数据:
- Face:一个曲面和一组Loop。
- Shell:Face实体的集合。
- Connex:Shell实体的集合。
- Topology B-rep 数据:拓扑边界表示法,由边界框和对多个Connex实体的引用组成。
以下为HOOPS Exchange B-rep 的拓扑结构图:
点击>>申请HOOPS试用![]() http://x7pfmmn259623uby.mikecrm.com/d7EBgIv
http://x7pfmmn259623uby.mikecrm.com/d7EBgIv
关于HOOPS可视化
Tech Soft 3D的旗舰图形引擎已为20多年来成功合作的程序提供最先进的图形支持,这些软件包括来自Oracle,SOLIDWORKS,Trimble,Hexagon,ANSYS,3D Systems,Mitutoyo,Actify等。全球各地的公司都依赖HOOPS Visualize在平台,设备和图形卡之间实现极高的性能,和一致的稳定性。
如果您的企业目前也有3D模型可视化、3D数据格式转换的需求,欢迎访问慧都网联系我们,我们也将为您定制3D解决方案并发送相关案例资料!
这篇关于3D数据转换器HOOPS Exchange如何获取模型的几何数据? 干货预警!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








