本文主要是介绍04MARL - priori kownledge and challenge,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、General Learning Process
- 二、中心化学习与独立学习
- 1.central learning
- 1.1 CQL
- 1.2 局限性
- 2.Independent Learning
- 2.1 IQL
- 2.2 局限性
- 三、MARL挑战
- 1.非平稳性
- 1.1单智能体强化学习的非平稳性
- 1.2 MARL非平稳性
- 2.信用分配问题
- 3.均衡选择
- 4.拓展性
- 四、协作型MARL的模型类型
- 1.self-play
- 2.mixed-play
- 总结
一、General Learning Process
在多智能体强化学习中,一般的学习框架包括模型、数据、算法与目标
模型:定义多个智能体如何与环境进行交互、包括非重复标准博弈、重复标准博弈、随机博弈、部分可观测随机博弈等
数据(经验):包括一系列的历史轨迹形成的经验
算法:根据当前的数据与联合策略生产新的联合策略 π z + 1 = L ( D z , π z ) \pi^{z+1}=\mathbb{L}(\mathcal{D}^z,\pi^z) πz+1=L(Dz,πz)
目标:联合策略 π ∗ \pi^{*} π∗,该策略能够在设定的环境下取得最大的回报
二、中心化学习与独立学习
多智能体强化学习的解决思路是将多智能体转化为单智能体,主要分为两种方法:central learning and independent learning
1.central learning
中心化学习直接利用联合动作状态空间学习一个中心化联合策略指导每个智能体的动作
学习一个中心化的策略,通过观测每个智能体的局部环境选择联合动作 A = A 1 × . . . × A n A=A_{1}\times...\times A_{n} A=A1×...×An为每个智能体选择一个动作,这样可以将多智能体问题降为单智能体问题,从而应用RL算法训练中心化的策略指导多智能体选择动作
1.1 CQL

CQL维护联合状态价值函数 Q ( s , a ) Q(s,a) Q(s,a),是MARL当中的主要算法的基础
中心化学习的方法能够有效避免环境非平稳与多智能体间的信用分配问题,但也具有一定的限制
1.2 局限性
局限一:从CQL当中可以看出中心化算法需要将多个智能体的联合奖励转换为单个标量奖励,对于common-reward情况能够进行量化,而对于零和博弈、随机博弈等情况无法有效的量化
局限二:联合动作空间随着智能体的数量增加呈指数型增长,单智能体强化学习算法不能很好的拓展到多智能体强化学习当中
局限三:多智能体系统固有结构导致智能体之间的交流无法实现,在随机博弈过程中,环境是全部可观测的,因此能够将中心化策略分解为单个智能体的策略 π c ( s ) = ( π 1 ( s ) = a 1 , . . . , π n ( s ) = a n ) \pi_c(s)=(\pi_1(s){=}a_1,...,\pi_n(s){=}a_n) πc(s)=(π1(s)=a1,...,πn(s)=an),因此当环境完成可观测时,每个智能体只需计算联合动作,并选择其对于的动作即可,然后环境部分可观测时,无法将联合策略分解为每个智能体的策略
2.Independent Learning
在独立学习中,每个智能体根据局部的信息、自己的奖励、自己的经验学习自身的策略,忽略其他智能体的存在,每个智能体并不会使用其他智能体观测到的信息,其他智能体的行为只是动态环境中的一部分
2.1 IQL

2.2 局限性
独立学习能够避免智能体数目增加带来的拓展问题以及不需要对联合回报进行转换,但环境的不平稳性对独立学习影响巨大,IQL状态转移函数如下:
T i ( s t + 1 ∣ s t , a i t ) = η ∑ a − i ∈ A − i T ( s t + 1 ∣ s t , ⟨ a i t , a − i ⟩ ) ∏ j ≠ i ^ π j ( a j ∣ s t ) \mathcal{T}_i(s^{t+1}\mid s^t,a_i^t)=\eta\sum_{a_{-i}\in A_{-i}}\mathcal{T}(s^{t+1}\mid s^t,\langle a_i^t,a_{-i}\rangle)\prod_{j\neq\hat{i}}\pi_j(a_j\mid s^t) Ti(st+1∣st,ait)=η∑a−i∈A−iT(st+1∣st,⟨ait,a−i⟩)∏j=i^πj(aj∣st)
不难看出,状态转移函数是非平稳的,因此会造成训练过程无法收敛
三、MARL挑战
1.非平稳性
marl当中的核心问题就是在多智能体相互交互学习过程中不断相互适应导致的非平稳问题,非平稳性会导致动态的循环,学习智能体适应其他智能体不断变化的策略,而其他智能体会根据学习智能体策略的改变而调整自身的策略
1.1单智能体强化学习的非平稳性
单智能体平稳性:动态环境不随时间的改变而变化,在蒙特卡洛决策过程当中,如果策略不发生改变,那么决策过程就是平稳的,而在RL当中,策略是在不断学习的,通过学习在t时间内收集到的所有episode内的数据进行更新,因此是非平稳的,和t相关,具体表现:在学习动作价值函数或状态价值函数时,都与后续的动作有关,这些动作也会随着策略的改变而改变,而策略更新会随着时间进行,因此更新的目标会发生改变,造成非平稳的问题
1.2 MARL非平稳性
多智能体的非平稳性:由于每个智能体的策略都会随着时间发生改变,因此加剧了非平稳性,不仅评估价值时具有非平稳性,同时在每个智能体的视角内,环境也带来了非平稳性
2.信用分配问题
在RL当中,信用分配问题是指哪些过去的动作会带来收益,在MARL问题当中,信用分配问题是指哪些智能体的动作有助于收益,因此RL当中通常是时间上的信用分配,MARL当中是指多智能体之间的信用分配
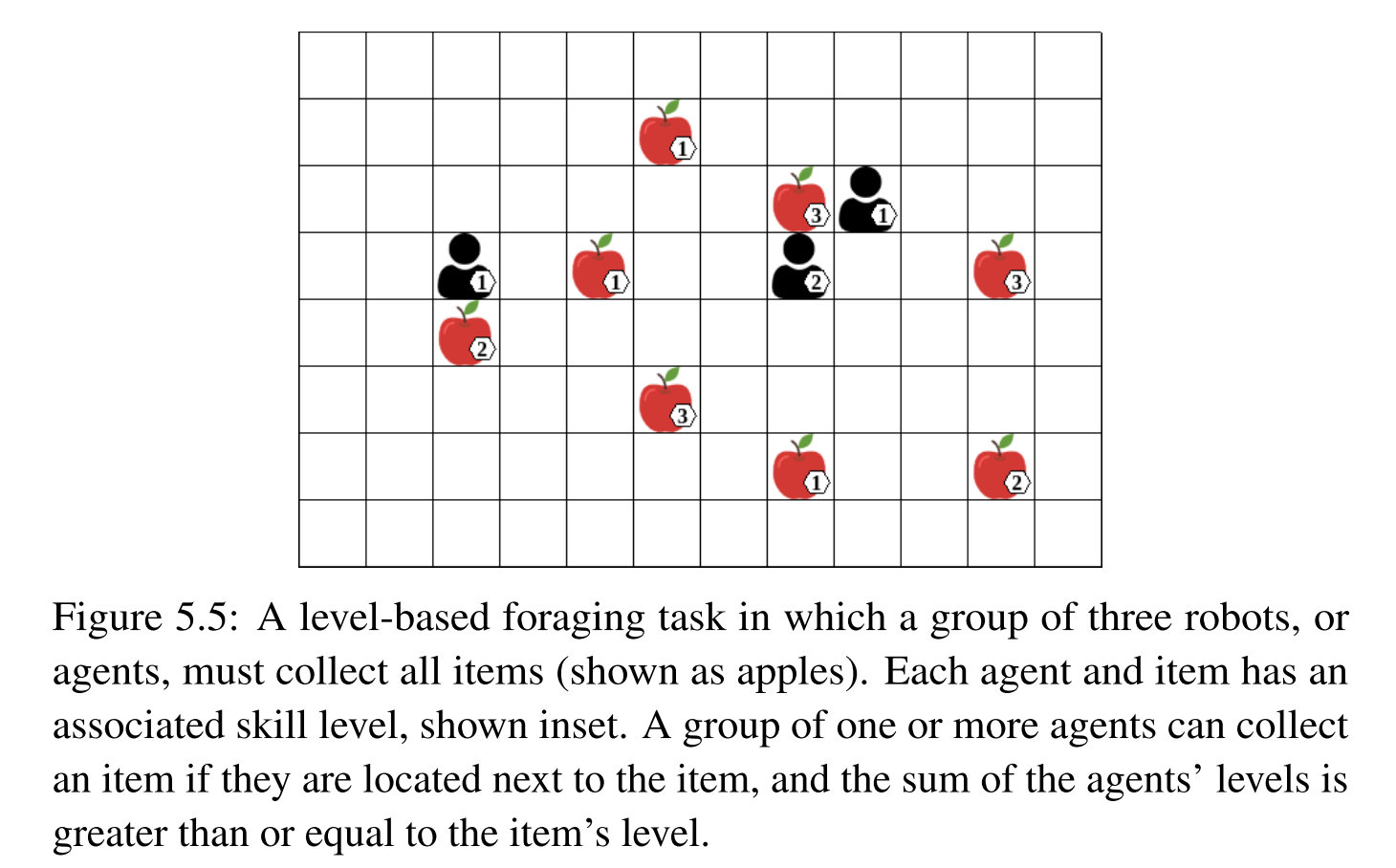
从例子中理解信用分配,例子中的设定,如果苹果周围的一个智能体或多个智能体的level和大于自身的level,那么即可收集该苹果,因此可以明显看出在左边的智能体并不能带来收益,而位于右边的两个智能体需要组合动作才能获得收益,单独采取动作并不能带来收益,这便是信用分配问题(考虑哪些智能体的动作会带来收益),这里没有考虑时间步
为了解决信用分配问题,每个智能体需要了解自身行为对收益的影响以及其他智能体行为的影响,因此采用联合动作能够有效解决该问题,类似于中心化学习的思想,联合动作能够清晰的分解出每个智能体对收益带来的影响
3.均衡选择
在博弈过程中,具有多种不同的均衡结果,因此会带来不同的期望回报,均衡选择也是强化学习中的重要问题
帕累托最优:不存在一组策略,在所有智能体收益不变的情况下,能够增加至少某一个智能体的收益
社会最优:所有智能体的收益之和最大
解决方法:通过增加额外的准则细化求解空间,例如怕累托最优与社会福祉最优
4.拓展性
在MARL当中,算法能够有效拓展到大量的智能体是重要的,由于联合动作随着智能体数量的增加呈指数上升,因此拓展性受到较大的影响
对于中心化学习的方法,智能体数目的增加导致联合动作空间呈指数上升;对于独立学习的方法,智能体数目的增加会导致环境的不平稳性加剧
四、协作型MARL的模型类型
1.self-play
自博弈能够描述两种相关但又完全不同的模型的操作,第一种自博弈定义了所有智能体都使用相同的算法以及对应的模型参数,收敛到相同的均衡状态,第二种自博弈定义在零和序列的博弈过程中,直接针对自身的策略进行训练,智能体发现自身的弱点并学会消除这些弱点
为了区别上述两种模型操作:使用算法自博弈与策略自博弈进行区分,策略自博弈相比于算法自博弈具有更快的训练速度,因为策略自博弈将所有智能体的经验进行组合单独训练一个策略,并且具有更强的限制
2.mixed-play
混合博弈是指智能体使用不同的算法进行学习
总结
此篇笔记记录了MRAL一般训练流程中的成分以及目前的挑战和模型的类型等
这篇关于04MARL - priori kownledge and challenge的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!