本文主要是介绍The Python Challenge,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
The Python Challenge
地址:http://www.pythonchallenge.com/
一共33关

第0关
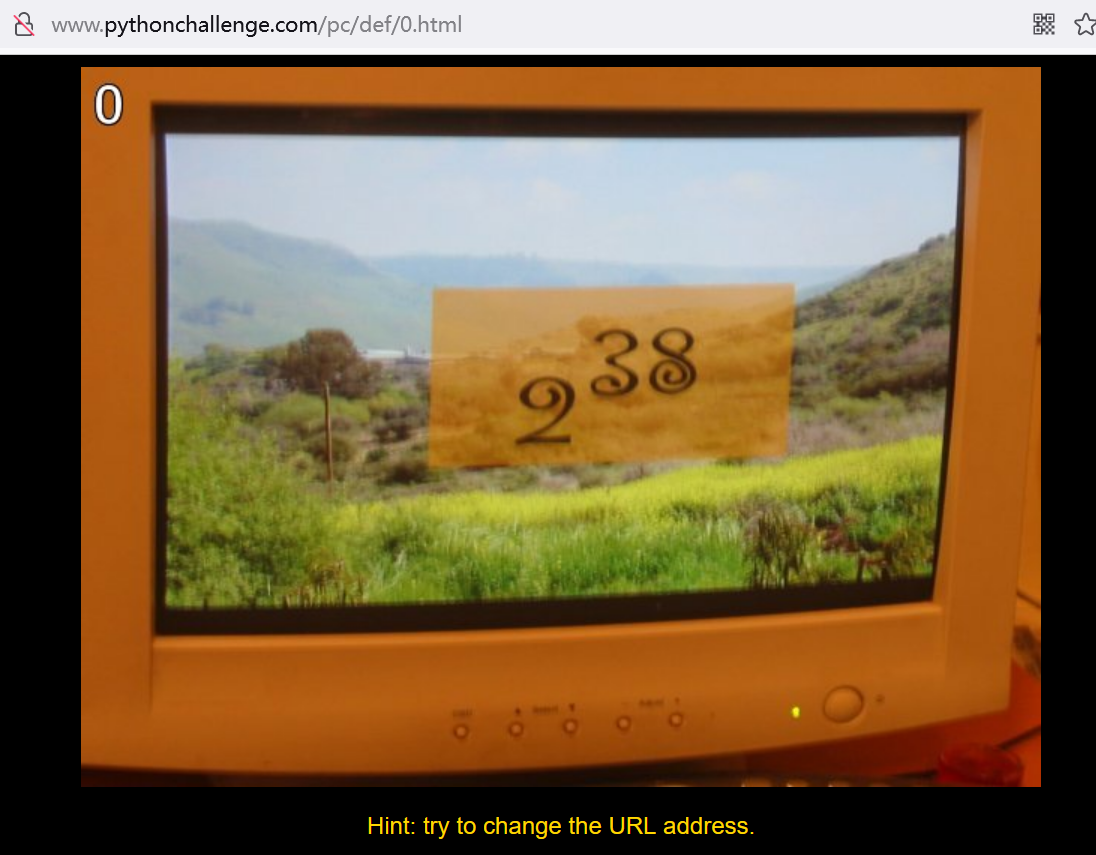 很明显数字238,但是直接访问提示:No… the 38 is a little bit above the 2…
很明显数字238,但是直接访问提示:No… the 38 is a little bit above the 2…
意思是38在2的上方,就是要2的38次方
运算print(2**38)得到结果
第1关
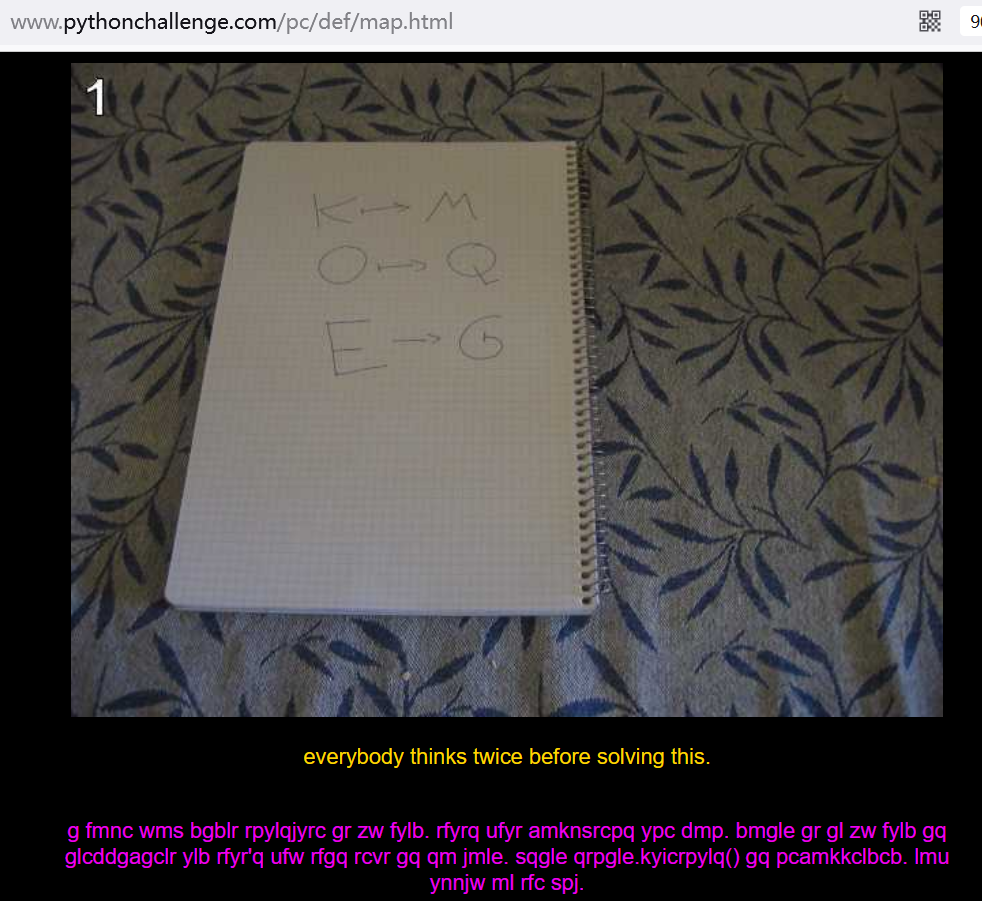
根据映射关系解密,我直接先去试了凯撒:
将这个规则应用到URL上,就是将map进行+2的凯撒加密
使用Python代码:
intab = "KOE"
outtab = "MQG"
str = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj. "def convert(intstr, n):outstr = ""for i in intstr:if 'a' <= i <= 'z':id = ord(i) - ord('a') + noutstr += chr(ord('a')+ id%26)elif 'A' <= i <= 'Z':id = ord(i) - ord('A') + noutstr += chr(ord('A')+ id%26)else:outstr += ireturn outstrprint(convert(str,2))
url = "map"
print(convert(url,2))
第2关

查看网页源代码发现存在提示:find rare characters in the mess below
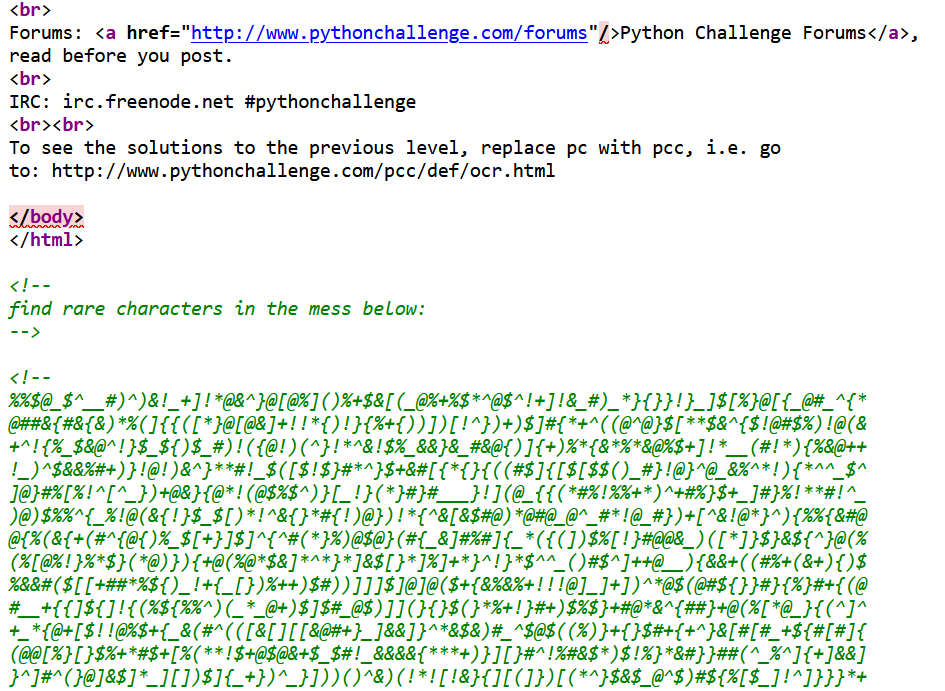
import requests
import re
def parse_ocr():url = "http://www.pythonchallenge.com/pc/def/ocr.html"response = requests.get(url)response_text = response.textdata = re.findall(r'<!--(.*?)-->',response_text, re.DOTALL)# print(data)for item in data:pattern = r'[a-zA-Z]'items = re.findall(pattern, item)print(''.join(items))
if __name__ == "__main__":parse_ocr()
第3关
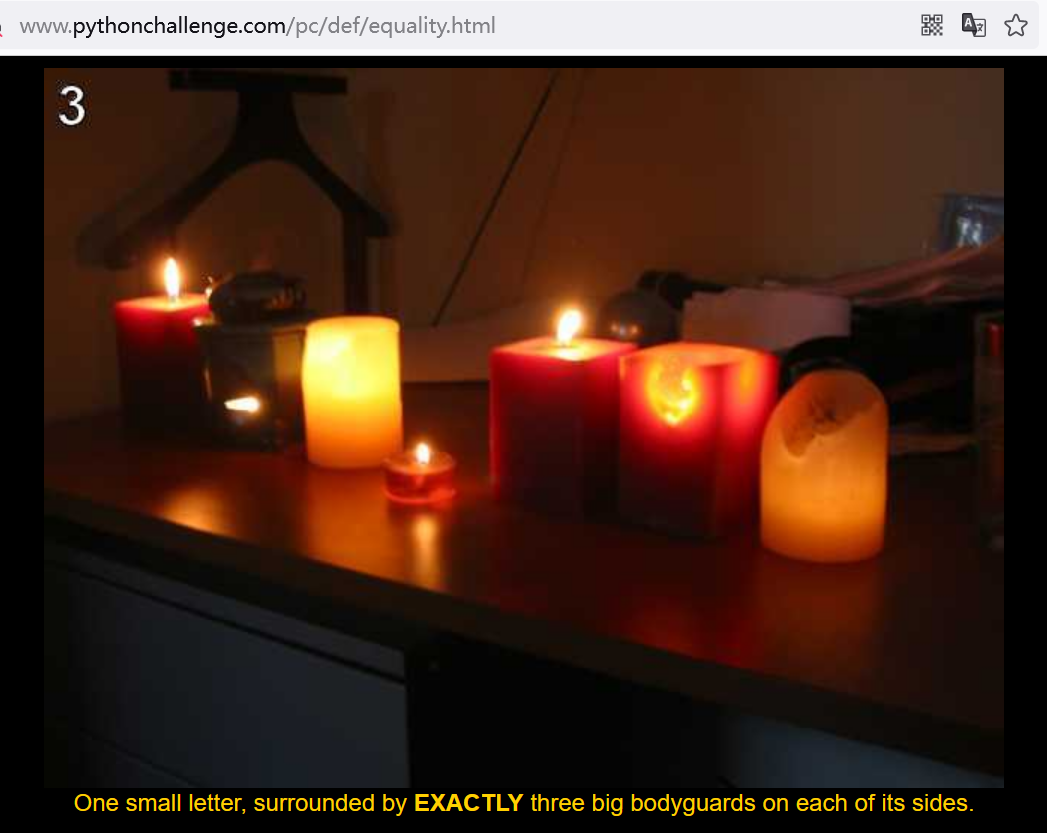
import requests
import re
def parse_html():url = "http://www.pythonchallenge.com/pc/def/equality.html"response = requests.get(url)response_text = response.textdata = re.findall(r'<!--(.*?)-->',response_text, re.DOTALL)# print(data)for item in data:pattern = r'[^A-Z][A-Z]{3}([a-z])[A-Z]{3}[^A-Z]'items = re.findall(pattern, item)print(''.join(items))
if __name__ == "__main__":parse_html()第4关


查看页面源代码:

传入参数:

发现是对参数进行不断匹配,使用正则匹配参数
import requests
import redef get_url(number):url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing={}".format(number)response = requests.get(url)response_text = response.text# print(response_text)pattern = r"\d+"matches = re.findall(pattern,response_text)[0]print(matches)return get_url(matches)if __name__ == "__main__":number = "12345"number = "16044" #Yes. Divide by two and keep going.number = "8022"number = "82683" #You've been misleaded to here. Go to previous one and check.number = "82682" #There maybe misleading numbers in the text. One example is 82683. Look only for the next nothing and the next nothing is 63579number = "63579"get_url(number)number = "66831" #peak.html
参数为16044时匹配报错,查看页面,提示要除以2

参数为82683时匹配报错,查看页面,回到上一步参数

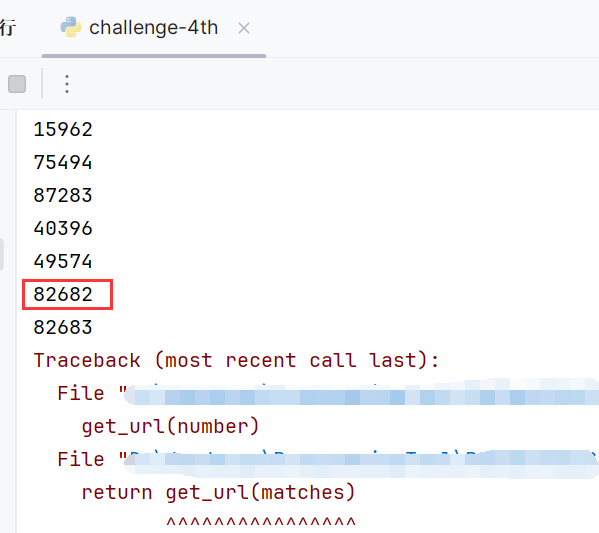
 提示下一个参数应该是63579
提示下一个参数应该是63579
运行到参数66831报错,查看页面

第5关
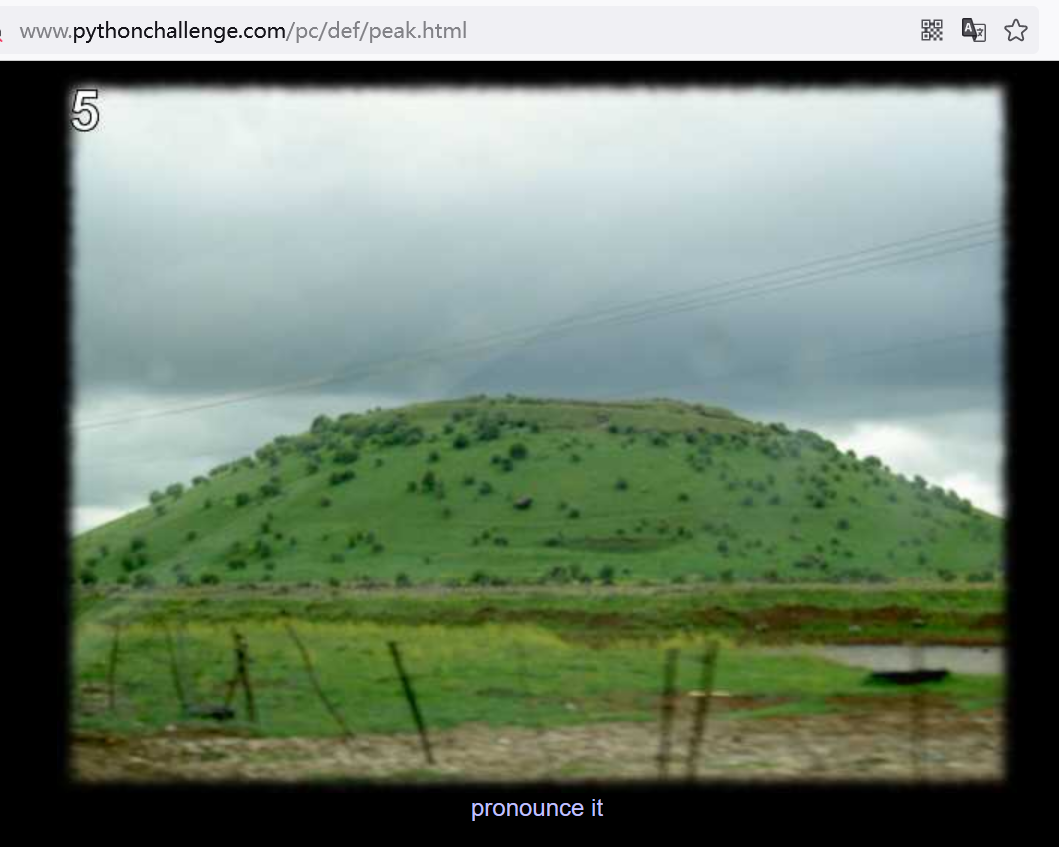
查看页面源代码
访问peakhell标签里面的资源banner.p
 需要对该文件进行解析:
需要对该文件进行解析:
import requests
import pickledef parse():url = "http://www.pythonchallenge.com/pc/def/banner.p"response = requests.get(url)items = pickle.loads(response.text.encode())for i in items:print(''.join([ j[0]*j[1] for j in i]))if __name__ == "__main__":parse()
运行结果:

第6关
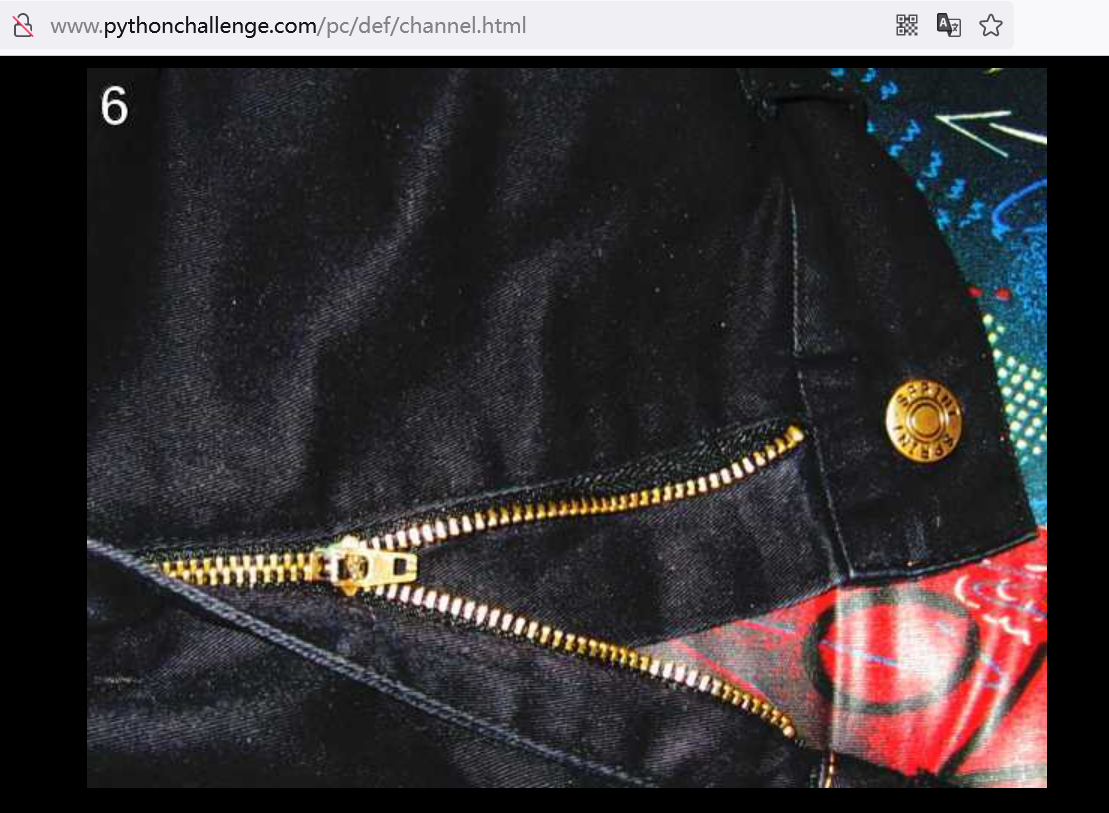
查看页面源代码:
 根据zip提示下载源文件
根据zip提示下载源文件
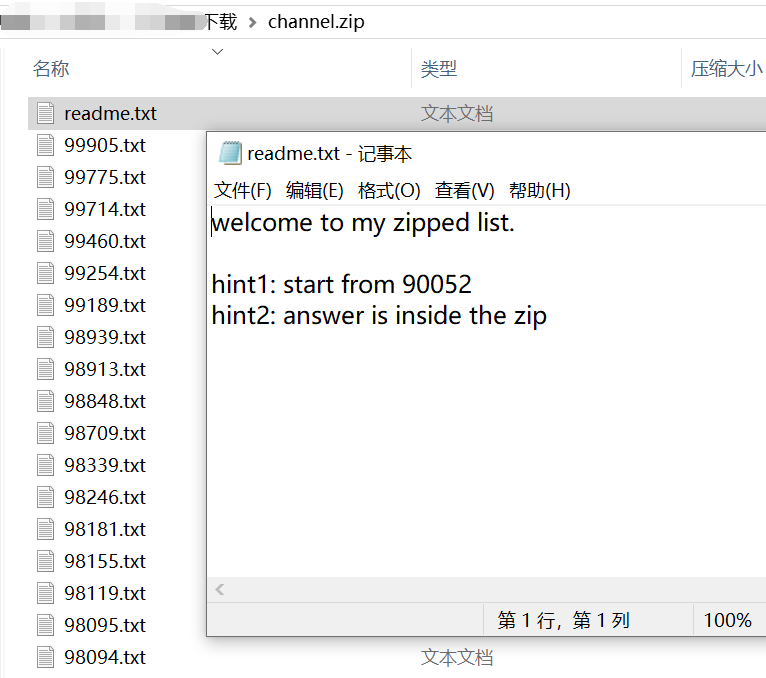
查看90052.txt

对文件内容进行匹配,获取下一个文件名
运行到46145时报错
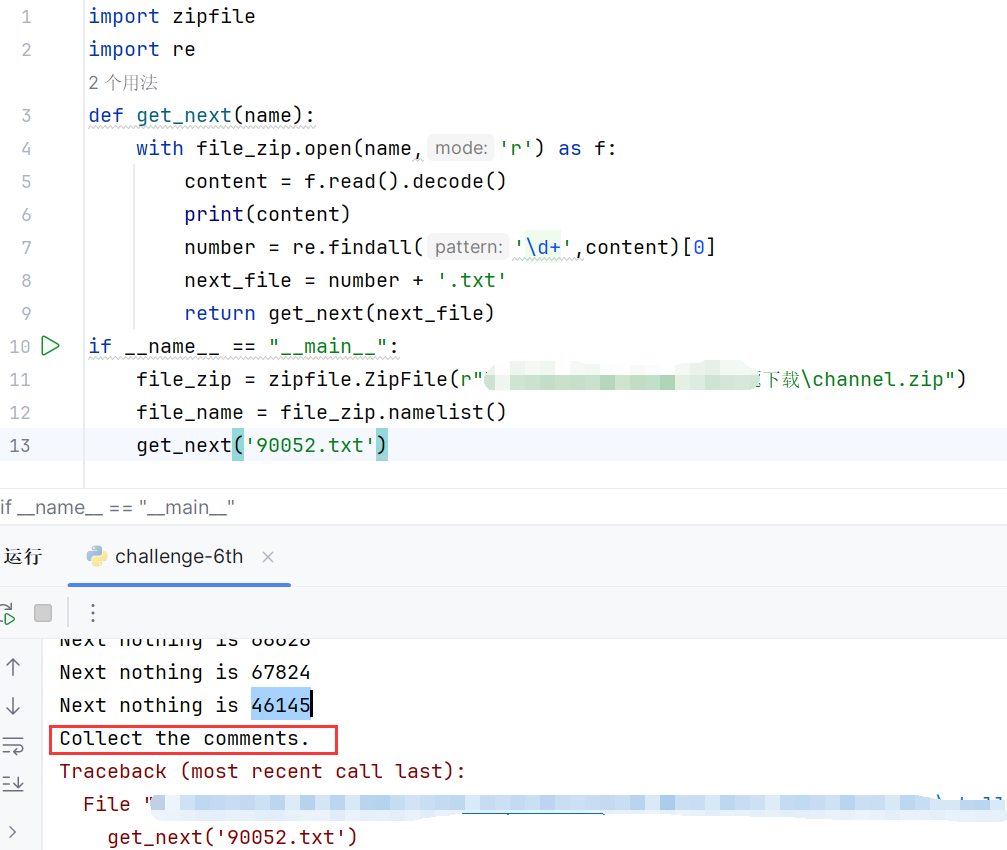
zipfile 的 comment 属性是用于获取或设置 ZIP 文件的注释信息。
对文件的注释进行收集:
import zipfile
import re
def get_next(name):with file_zip.open(name,'r') as f:content = f.read().decode()# print(content)# #正则匹配文件内容# number = re.findall('\d+',content)[0]# next_file = number + '.txt'# return get_next(next_file)#获取zipfile文件的comment属性item = file_zip.getinfo(name).commentcomment_list.append(item.decode())print(content)try:number = re.findall('\d+', content)[0]next_file = number + '.txt'except Exception:return Nonereturn get_next(next_file)if __name__ == "__main__":file_zip = zipfile.ZipFile(r"D:\...\下载\channel.zip")file_name = file_zip.namelist()comment_list = []get_next('90052.txt')print(''.join(comment_list))

第7关
 提示查看字母,前面运行结果里面的字母是:oxygen
提示查看字母,前面运行结果里面的字母是:oxygen

。。。未完待续
这篇关于The Python Challenge的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




